핵심 요약
이 논문은 3D Scene Graph를 동적 agent, traversability, planning query까지 다룰 수 있는 3D Dynamic Scene Graph로 확장하고, visual-inertial data에서 이를 자동 구축하는 SPIN을 제안한다.
3D DSG는 dense mesh에서 building까지 이어지는 계층적 공간 표현에 사람/로봇 같은 agent의 시간적 관계를 붙여, SLAM 결과를 planning과 decision-making에 바로 연결하려는 표현이다.
Dynamic Scene Graph
정적 3D scene graph를 layered, hierarchical, dynamic, actionable representation으로 확장
SPIN
stereo camera와 IMU streaming data에서 DSG를 자동 생성하는 Spatial PerceptIon eNgine 제안
Human Mesh Tracking
visual-inertial SLAM과 dense human mesh tracking을 하나의 spatial perception pipeline 안에서 결합
uHumans Evaluation
Unity 기반 photorealistic simulator에서 crowded scene, object, room parsing을 정량 평가
이 논문은 “semantic SLAM을 더 잘한다”보다 한 단계 위의 질문을 던진다. 핵심은 로봇이 무엇을 기억하고, 무엇을 계획에 써야 하는가이며, DSG는 geometry, semantics, topology, dynamics를 같은 graph 안에서 query 가능한 형태로 묶는다.
metric detail에서 planning abstraction으로 올라가는 layer 관계를 먼저 본다.
3D_SG, 3D_DSG, SPIN이 각각 어디까지 담당하는지 분리한다.
3D Scene Graph
정적 scene의 entity, attribute, relationship을 3D space에 구조화
3D Dynamic Scene Graph
agent trajectory, time-aware relation, traversability까지 포함해 planning query 지원
SPIN
Kimera, object parsing, human tracking, room parsing을 결합해 DSG를 sensor data에서 자동 구축
이 논문은 3D_SG의 “semantic database” 관점을 로봇이 실제로 행동할 수 있는 hierarchy로 바꾼다.
| Layer | 무엇을 담나 | 로봇 관점의 역할 |
|---|---|---|
Mesh | 3D point, face, RGB, panoptic label | 정밀 collision / reconstruction 기반 |
Objects / Agents | object pose, bounding box, human/robot trajectory, mesh | 동적 장면과 object search의 중심 |
Places / Structures | free-space topology, traversability, wall/floor/ceiling | navigation graph와 room parsing 연결 |
Rooms / Building | room adjacency, room containment, building root | 고수준 task planning의 추상화 단위 |
Key Summary
This paper extends 3D Scene Graphs into dynamic, actionable spatial representations and proposes SPIN, a pipeline that builds them from visual-inertial data.
A 3D DSG links dense metric maps, semantic entities, topological places, rooms, buildings, and time-varying agents so SLAM outputs can directly support planning and decision-making.
Dynamic Scene Graph
Extends static 3D scene graphs into layered, hierarchical, dynamic, actionable representations.
SPIN
Builds DSGs automatically from streaming stereo camera and IMU data.
Human Mesh Tracking
Reconciles visual-inertial SLAM with dense human mesh tracking inside one perception pipeline.
uHumans Evaluation
Evaluates crowded scenes, objects, humans, and room parsing in a Unity-based simulator.
The paper is less about improving semantic SLAM alone and more about what a robot should remember and query. DSGs turn geometry, semantics, topology, and dynamics into a single graph for action.
Read the layers as a path from metric detail to planning abstraction.
Separate what 3D_SG, 3D_DSG, and SPIN each contribute.
3D Scene Graph
Structures static entities, attributes, and relationships in 3D space.
3D Dynamic Scene Graph
Adds agent trajectories, time-aware relations, and traversability for planning queries.
SPIN
Combines Kimera, object parsing, human tracking, and room parsing to build DSGs from sensor data.
The representation turns the 3D_SG semantic database idea into an actionable hierarchy for robots.
| Layer | What it stores | Robot-facing role |
|---|---|---|
Mesh | 3D points, faces, RGB, panoptic labels | Fine metric basis for collision and reconstruction |
Objects / Agents | Object pose, bounding boxes, human and robot trajectories, meshes | Core layer for dynamic scenes and object search |
Places / Structures | Free-space topology, traversability, wall/floor/ceiling nodes | Connects navigation graph to room parsing |
Rooms / Building | Room adjacency, containment, building root | Abstraction unit for high-level task planning |
논문 상세 정리
아래부터는 기존 논문 내용을 최대한 담은 상세 해석이다. 핵심 흐름에서 벗어나는 배경지식, 반복 나열, 부가 자료는 접어두었다.
Problem: dynamic 3D scene을 왜 계층 graph로 봐야 하나
Abstract는 DSG를 “표현 방식”, SPIN을 “그 표현을 자동으로 채우는 엔진”으로 나눠 소개한다.
| 축 | 논문의 주장 | 읽는 포인트 |
|---|---|---|
Representation | DSG는 scene graph를 dynamic scene과 actionable relation으로 확장 | graph 자체가 planning/decision-making 입력 |
Engine | SPIN은 visual-inertial data에서 DSG를 자동 구축 | SLAM, object parsing, human mesh tracking의 결합 |
Evaluation | Unity simulator와 uHumans dataset으로 robustness와 expressiveness 평가 | 정량 평가보다 “어떤 query가 가능해지는가”도 중요 |
이 논문은 3D Dynamic Scene Graphs를 actionable spatial perception을 위한 통합 표현으로 제시한다. Scene graph의 node는 objects, walls, rooms 같은 entity를 나타내고, edge는 inclusion, adjacency 같은 relation을 나타낸다.
DSG는 여기에 moving agents, spatio-temporal relations, multiple abstraction levels를 추가한다. 즉 “사람 A가 시간 t에 방 B에 있음”, “두 place 사이에 traversable edge가 있음”처럼 로봇 행동에 바로 필요한 정보를 graph에 포함한다.
Abstract의 기여는 “표현 → 엔진 → 검증 → 응용” 순서로 읽으면 깔끔하다.
dynamic agents와 actionable relation을 포함한 layered directed graph
visual-inertial input에서 DSG를 자동 생성하는 spatial perception engine
VIO와 dense SMPL human mesh tracking을 하나의 pipeline으로 결합
planning, HRI, long-term autonomy, prediction 가능성 제시
Context: robot scene understanding에는 무엇이 부족한가
Introduction의 핵심은 “SLAM map을 task-level action으로 어떻게 연결할 것인가”다.
| 필요 조건 | 기존 한계 | DSG의 대응 |
|---|---|---|
Metric grounding | SLAM/VIO는 low-level geometry 중심 | semantic concept를 metric map에 연결 |
Hierarchy | motion planning과 task planning의 해상도 차이 | mesh, place, room, building을 계층화 |
Dynamics | static scene graph는 사람 같은 moving entity를 모델링하지 않음 | agent pose graph와 temporal relation 추가 |
로봇이 “2층 건물에서 생존자를 찾아라” 같은 고수준 명령을 수행하려면 survivor, floor, building 같은 semantic concept가 metric map 위에 정확히 grounding되어야 한다. 또한 motion planning은 fine-grained map을, task planning은 추상화된 world model을 요구한다.
기존 연구의 빈틈은 세 가지가 동시에 만족되지 않는다는 점이다.
주로 2D, static environment, dense semantic 부족
object list, mesh, volume처럼 flat representation에 가까움
계층은 있지만 traversability와 dynamic agents가 부족
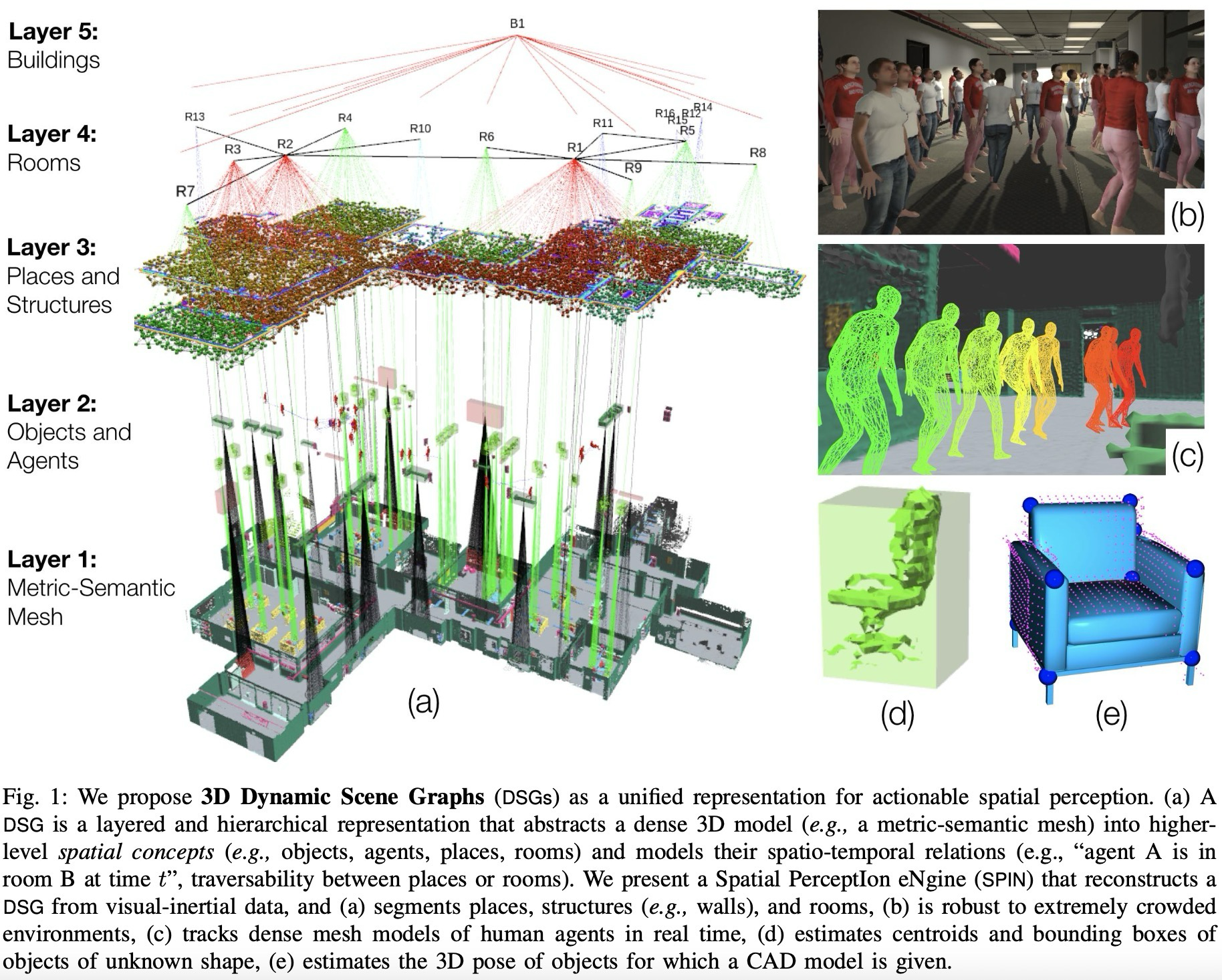
DSG는 “static 3D scene graph + 사람 node” 정도가 아니라, topological map, temporal relation, bounding volume hierarchy까지 포함해 action query를 가능하게 하는 표현으로 정의된다.
Gap: static graph와 dynamic robot perception 사이에 무엇이 비어 있나
세부 문헌 나열은 접고, 이 논문이 결합하는 연구 축을 먼저 본다.
| 연구 축 | 기존 초점 | 이 논문의 위치 |
|---|---|---|
Scene Graphs | 2D image understanding, QA, captioning, static 3D scene | dynamic, hierarchical, actionable graph로 확장 |
Robotics Mapping | 2D hierarchical maps, conceptual maps, topological maps | 3D mesh와 semantic label, dynamic agents를 함께 사용 |
Metric-Semantic Mapping | object map, dense point cloud, mesh, volumetric model | flat map을 DSG hierarchy와 query structure로 끌어올림 |
Dynamic SLAM / Human Pose | moving object tracking, 3D pose estimation | SMPL dense human mesh를 SLAM map과 결합 |
Related Work 세부 흐름 보기
이 토글은 Dynamic Scene Graph가 기존 scene graph와 metric-semantic mapping 위에 어떤 동적 계층을 얹는지 확인하는 보충 구간이다.
object, place, room처럼 정적인 semantic/spatial hierarchy를 제공.
사람과 움직임을 graph 안의 agent/layer로 다루는 방향을 추가.
VIO, mesh, semantics, human tracking을 묶어 DSG를 자동 생성.
2D scene graph는 image retrieval, captioning, visual question-answering, action detection에서 많이 사용되었다. 3D scene graph에서는 Armeni et al.이 static hierarchical model을 제시했고, Kim et al.은 robotics 관점의 graph를 제안했지만 objects 중심에 머물렀다.
Robotics map representation은 오래전부터 hierarchical map의 필요성을 제기했지만 대부분 2D, static, sparse semantic에 가까웠다. Metric-semantic reconstruction은 SLAM++, SemanticFusion, Kimera 같은 방식으로 metric-semantic map을 만들었지만, 논문이 원하는 multi-level action query까지는 직접 연결되지 않는다.
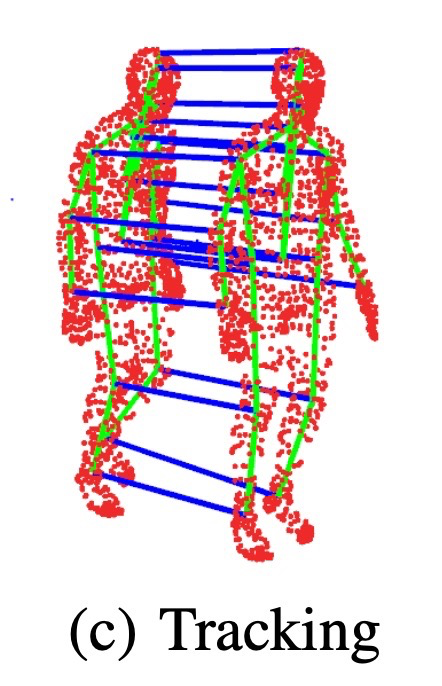
Dynamic SLAM과 human pose 연구는 moving object나 사람 pose를 다루지만, 이 논문은 사람을 agent node로 넣고 pose graph와 dense mesh를 DSG 내부에 함께 저장한다는 점이 다르다.
Mechanism: dynamic scene graph는 어떤 layer로 구성되나
DSG는 5개의 layer와 layer 안팎의 edge로 구성된 directed graph다.
| Layer | Node / Attribute | Edge / Relation | 읽는 포인트 |
|---|---|---|---|
L1 Mesh | 3D position, normal, RGB, panoptic label | triangle face topology | 정적 환경의 dense metric-semantic 기반 |
L2 Objects / Agents | object pose, bbox, class / agent pose graph, mesh | co-visibility, proximity, temporal tracking | static object와 dynamic human/robot을 분리 |
L3 Places / Structures | free-space place, wall/floor/ceiling structure | traversability, structural relation | path planning과 room parsing의 접점 |
L4 Rooms | room pose, bbox, semantic class | adjacency, containment | 고수준 spatial context 제공 |
L5 Building | single building pose, bbox, class | room containment | 전체 graph의 root abstraction |
Layer가 높아질수록 metric detail은 줄고, planning abstraction은 커진다.
정적 환경을 dense mesh와 panoptic label로 표현
object는 static, agent는 time-varying pose graph와 mesh를 가짐
free-space topology와 구조물을 함께 관리
place를 묶어 room/corridor/hall abstraction 생성
single building 단위의 최상위 root

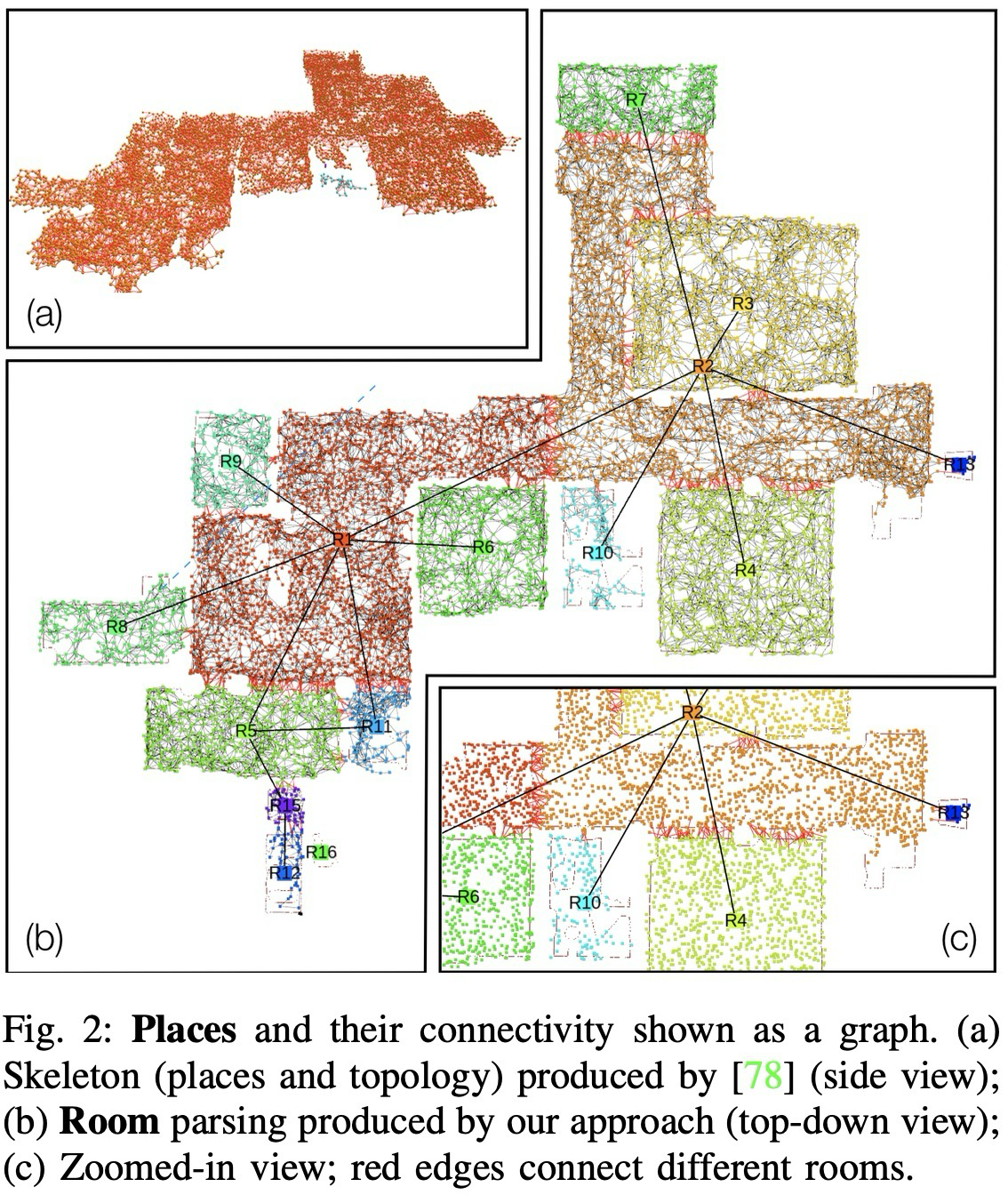



논문은 node와 edge 선택이 유일하지 않으며, task query에 맞게 확장 가능하다고 말한다.
semantic attribute는 high-level task를, geometry와 edge는 motion planning을 지원
multi-story building에서는 Building과 Rooms 사이에 Level layer를 추가 가능
Mechanism: SPE는 graph를 어떻게 갱신하나
SPIN은 sensor data에서 DSG의 각 layer를 채우는 pipeline이다.
| 단계 | 입력 / 방법 | DSG에 채우는 것 |
|---|---|---|
Mesh / Robot | Kimera-VIO, RPGO, Mesher, Semantics | Layer 1 mesh, robot pose graph |
Humans | SMPL mesh estimation, skeleton consistency, dynamic masking | agent node, human pose graph, human mesh |
Objects | semantic mesh clustering, CAD model fitting, TEASER++ | object centroid, bbox, pose, class |
Places / Rooms | ESDF topology, structural labels, 2D ESDF section, majority voting | place graph, structures, room labels, room adjacency |
streaming visual-inertial data
metric-semantic mesh and robot node
dynamic agent pose graph
static object nodes
topology and room graph
query-ready spatial representation
사람 node는 단일 이미지 추정 결과를 그대로 쓰지 않고, outlier rejection과 temporal consistency를 거친다.
image boundary에 너무 가깝거나 bbox가 30px 이하인 detection 제거
이전 skeleton과 현재 detection의 joint motion이 물리적으로 가능한지 확인
human pixel은 free-space만 ray casting하여 static mesh에 사람 잔상이 남지 않게 함

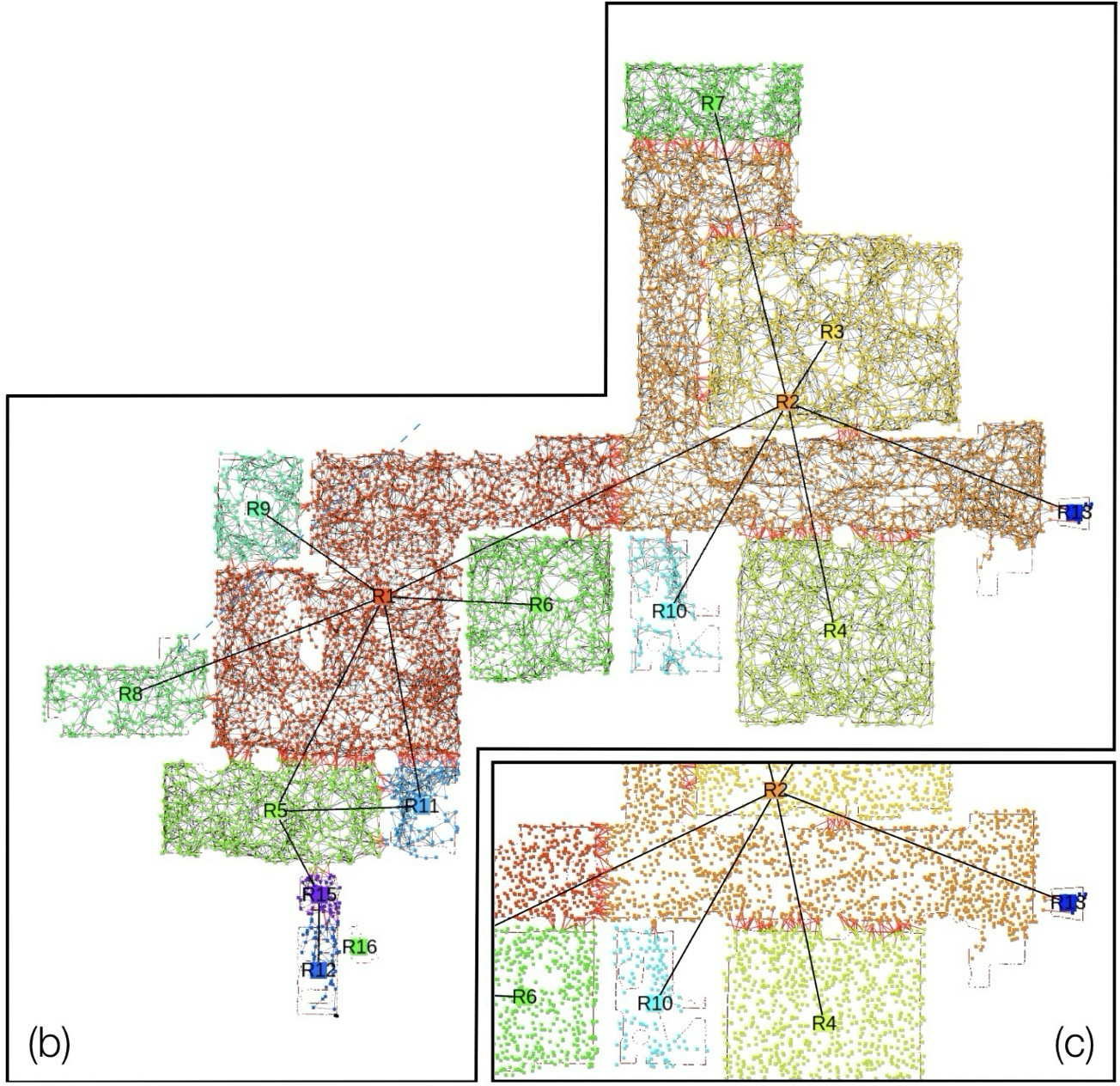
방 분할은 복잡한 floor plan reconstruction 대신 ESDF의 수평 절단면을 이용하는 간단한 heuristic으로 구현된다.
ceiling 아래 0.3m 지점에서 3D ESDF를 수평으로 절단
0.2m 이상 거리만 남겨 작은 opening과 noise 제거
2D 위치와 graph neighborhood majority voting으로 place를 room에 할당
서로 다른 room의 place가 연결되면 room adjacency edge 추가
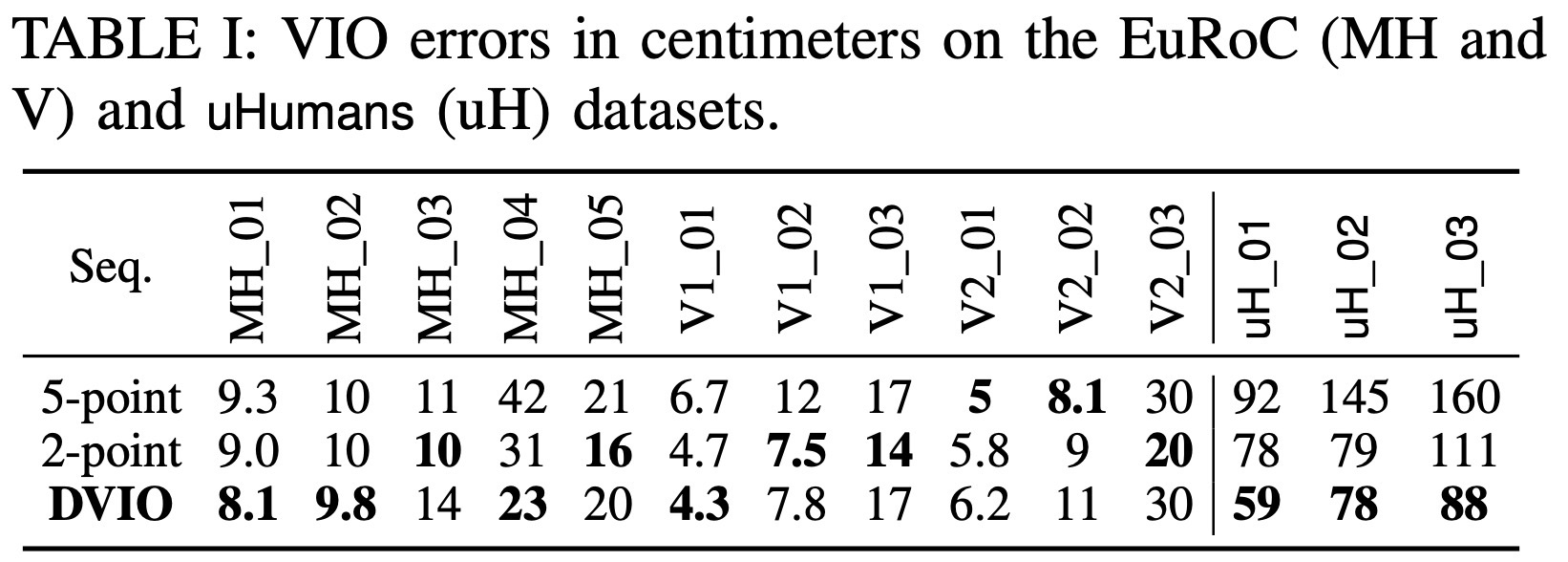
Evidence: 어떤 query와 reconstruction으로 검증했나
실험은 실제 robot benchmark라기보다, photorealistic simulator에서 SPIN의 robustness와 표현력을 검증하는 구조다.
| Dataset | 환경 | Human 수 | 평가 목적 |
|---|---|---|---|
uH_01 | 65m x 65m Unity office | 12 | crowded scene 기본 설정 |
uH_02 | same simulator | 24 | 중간 혼잡도 |
uH_03 | same simulator | 60 | 높은 혼잡도와 dynamic object stress test |
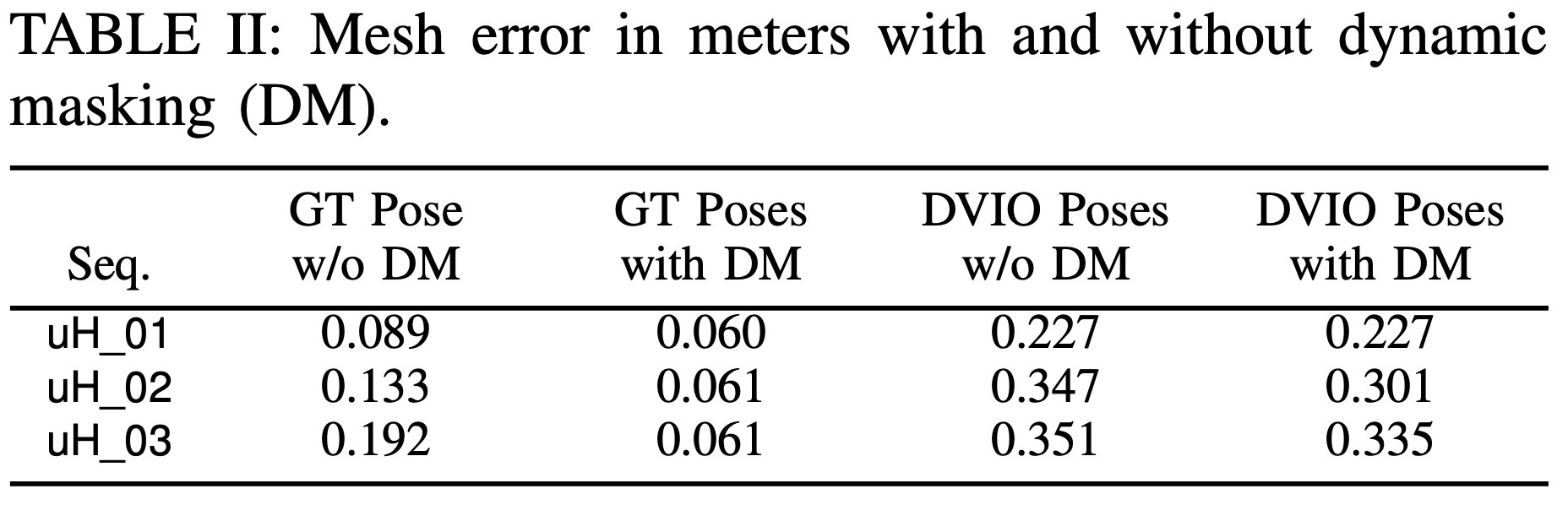
crowded scene에서 핵심은 VIO robustness와 dynamic masking이 함께 필요하다는 점이다.
- 2-point RANSAC으로 static EuRoC에서도 성능 유지/개선
- uHumans에서는 DVIO가 Kimera-VIO baseline보다 낮은 trajectory error
- human contrail이 mesh에 남는 문제 제거
- GT pose에서도 mesh error 개선 효과 확인
동적 환경에서는 pose accuracy만 좋아도 충분하지 않고, mesh update에서 dynamic region을 어떻게 다루는지가 중요하다.
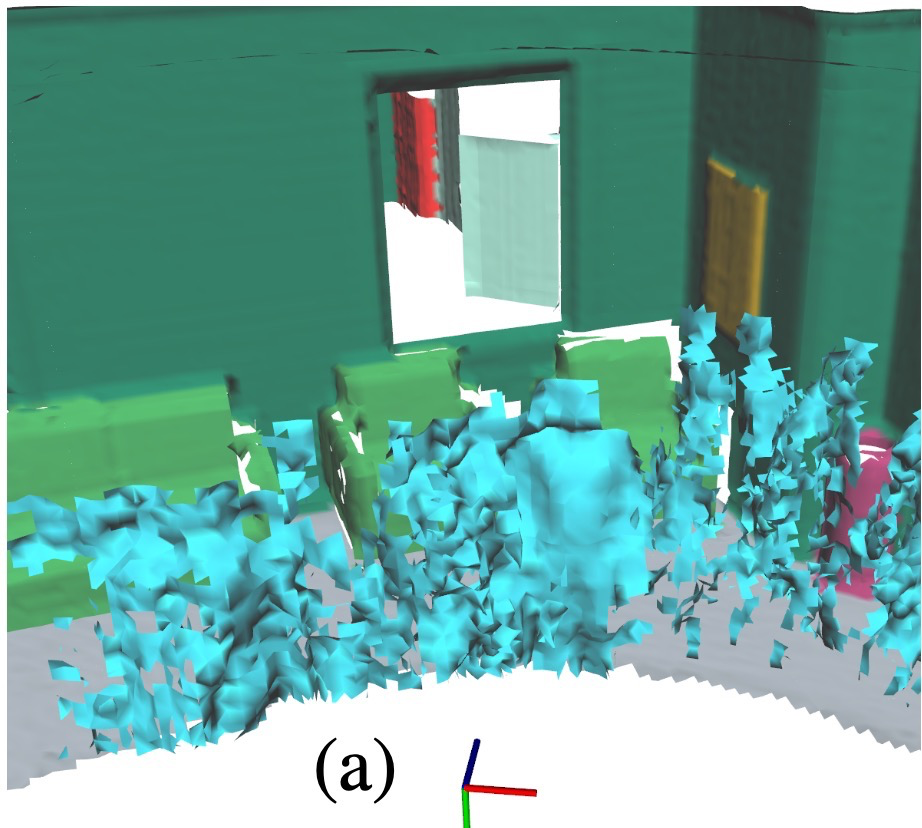
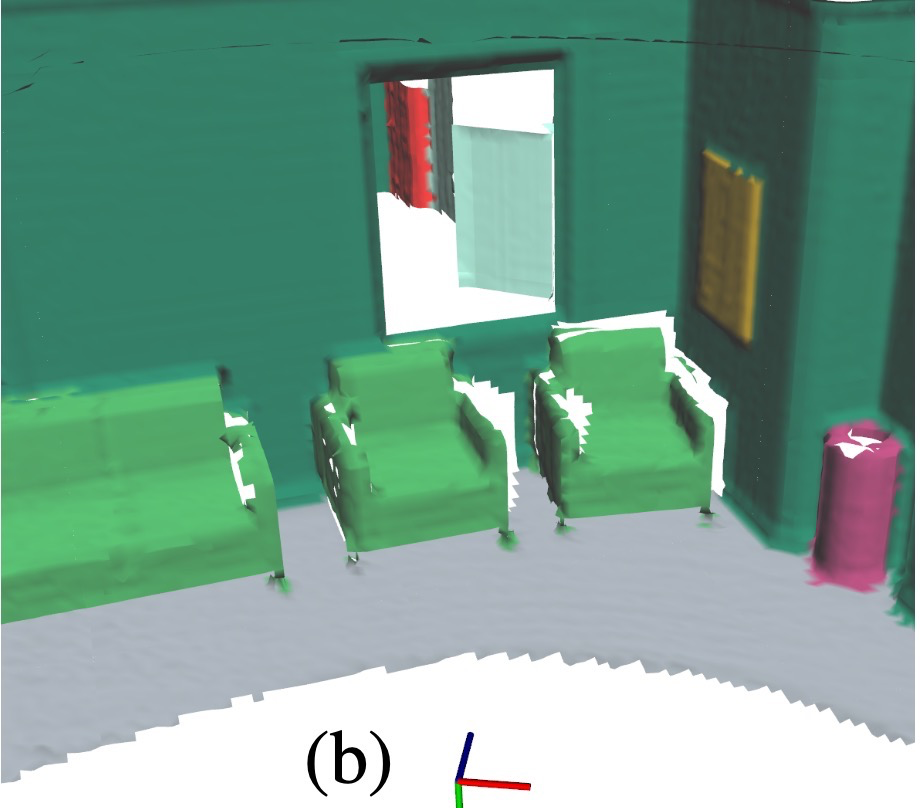
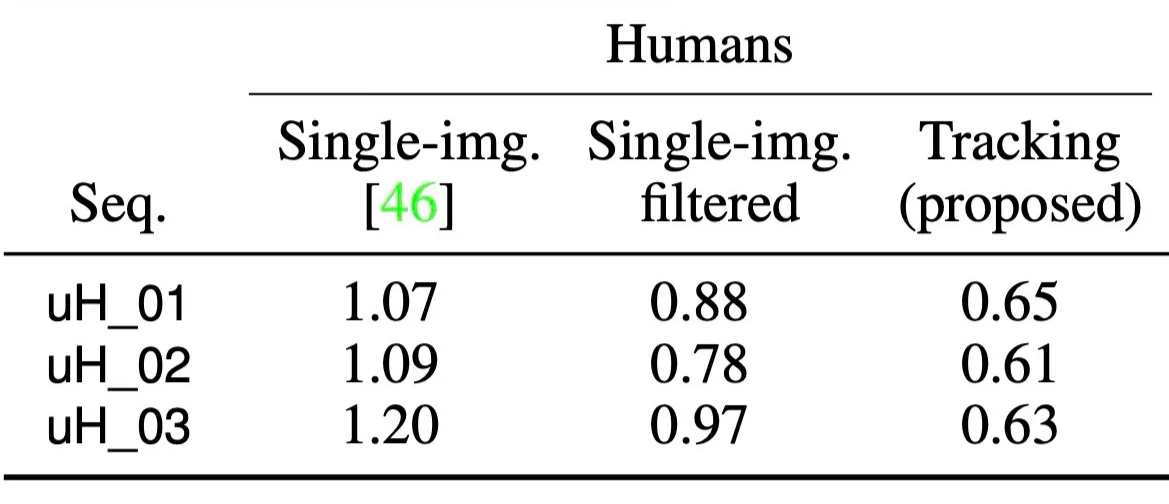
SPIN은 human agent와 static object를 같은 Layer 2에 두지만, 생성 방식은 다르게 가져간다.
- single-image estimate보다 filtered detection 개선
- pose graph tracking이 가장 낮은 localization error
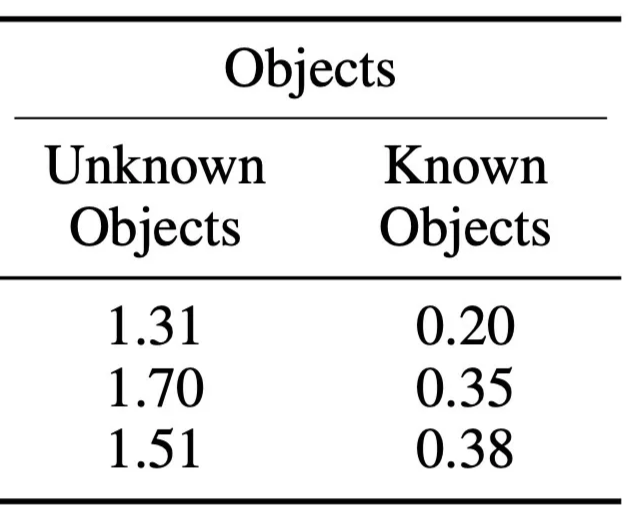
semantic mesh에서 class별 부분을 추출하고 Euclidean clustering으로 instance 분리.
CAD model keypoint와 Kimera mesh keypoint를 TEASER++로 robust registration.
uH_01에서 place-to-room classification precision 99.89%, recall 99.84%.
Usage / Limits: 어떤 robot query에 유용한가
Section VI는 DSG가 어떤 query를 가능하게 하는지 보여주는 파트다.
room/object/agent bounding box가 BVH처럼 작동해 collision checking 가속
“사람이 시간 t에 어디 있었나?”, “어떤 물체를 집었나?” 같은 query 가능
자주 관측되지 않는 branch를 pruning하고 필요한 abstraction만 유지
metric-semantic mesh와 agent description을 physics simulator에 연결
DSG의 bounding box hierarchy는 computer graphics에서 collision checking에 쓰이는 Bounding Volume Hierarchy와 유사하게 사용할 수 있다. 또한 objects와 places의 connected subgraph는 object search 같은 고수준 명령을 path planning으로 연결하는 데 쓰인다.
Long-term autonomy 관점에서는 room node를 제거하면 그 아래 places, objects 등을 함께 제거할 수 있고, object CAD model은 하나만 저장한 뒤 여러 node에서 참조할 수 있어 memory compression이 가능하다.
느낀점
(진행중...)
Problem: why represent dynamic 3D scenes as layered graphs?
The abstract separates the representation, the engine that builds it, and the simulator evaluation.
| Axis | Claim | Reading point |
|---|---|---|
Representation | DSGs extend scene graphs to dynamic scenes and actionable relations. | The graph itself becomes input for planning and decision-making. |
Engine | SPIN builds DSGs automatically from visual-inertial data. | Combines SLAM, object parsing, and dense human mesh tracking. |
Evaluation | Unity and uHumans test robustness and expressiveness. | The possible queries matter as much as the numbers. |
The paper introduces 3D Dynamic Scene Graphs as a unified representation for actionable spatial perception. Nodes represent scene entities, and edges represent spatial, logical, or temporal relations.
DSGs add moving agents, spatio-temporal relations, and multiple levels of abstraction. This makes queries such as “agent A is in room B at time t” or “which place should the robot reach to find this object?” natural graph queries.
The contributions read as representation, engine, tracking, and applications.
Layered directed graph with dynamic agents and actionable relations.
Spatial perception engine that builds DSGs from visual-inertial input.
Integrates VIO and dense SMPL human mesh tracking.
Motivates planning, HRI, long-term autonomy, and prediction queries.
Context: what is missing in robot scene understanding?
The introduction asks how a SLAM map becomes useful for task-level action.
| Need | Prior limitation | DSG response |
|---|---|---|
Metric grounding | SLAM and VIO focus on low-level geometry. | Ground semantic concepts in a metric map. |
Hierarchy | Motion and task planning require different resolutions. | Layer mesh, places, rooms, and building abstractions. |
Dynamics | Static scene graphs do not model people or other moving agents. | Add agent pose graphs and temporal relations. |
High-level instructions require semantic concepts to be grounded in metric space. At the same time, robots need both fine maps for motion planning and compact abstractions for task planning.
The prior literature misses at least one of these three requirements.
Mostly 2D, static, and semantically sparse.
Often flat object, mesh, or volumetric representations.
Hierarchical but lacking traversability and dynamic agents.
A DSG is not just a static scene graph with a human node. It also adds topology, temporal relations, and bounding-volume structure for action queries.
Gap: what is missing between static graphs and dynamic robot perception?
The related work is best read as the set of threads SPIN combines.
| Thread | Prior focus | This paper's move |
|---|---|---|
Scene graphs | 2D image understanding, QA, captioning, static 3D scenes | Extends graphs to dynamic, hierarchical, actionable robotics maps |
Robotics maps | 2D hierarchical, conceptual, and topological maps | Uses 3D mesh, semantics, and dynamic agents together |
Metric-semantic mapping | Object maps, dense point clouds, meshes, volumetric models | Lifts flat maps into graph hierarchy and query structure |
Dynamic SLAM / Human pose | Moving objects or 3D human pose | Stores SMPL human meshes and trajectories as DSG agent nodes |
Related work details
This supplement explains how Dynamic Scene Graphs extend static semantic graphs with agents, time, and an automatic construction pipeline. The important gap is that prior maps often keep semantics, geometry, and dynamics in separate representations.
Provide object/place/room hierarchy for semantic spatial structure.
Add humans and temporal state to the graph representation.
Combines VIO, mesh, semantics, and human tracking to build DSGs automatically.
2D scene graphs support retrieval, captioning, VQA, and action detection. Armeni et al. introduced a static 3D scene graph, and Kim et al. proposed a robotics graph focused mostly on objects.
Robotics map representations recognized hierarchy early, but were often 2D and static. Metric-semantic mapping creates rich maps, yet usually lacks the multi-level action-query interface that DSGs target.
Mechanism: which layers make up a dynamic scene graph?
A DSG is a directed graph with five semantic and geometric layers.
| Layer | Node / attribute | Edge / relation | Reading point |
|---|---|---|---|
L1 Mesh | 3D position, normal, RGB, panoptic label | triangle-face topology | Dense metric-semantic basis of the static environment |
L2 Objects / Agents | Object pose, bbox, class / agent pose graph and mesh | co-visibility, proximity, temporal tracking | Separates static objects from dynamic humans and robots |
L3 Places / Structures | Free-space places, walls, floor, ceiling | traversability, structural relations | Connects path planning to room parsing |
L4 Rooms | Room pose, bbox, semantic class | adjacency, containment | Provides high-level spatial context |
L5 Building | Single building pose, bbox, class | room containment | Root abstraction of the graph |
Moving upward reduces metric detail and increases planning abstraction.
Dense static environment with panoptic labels.
Objects are static; agents are time-varying pose graphs with meshes.
Free-space topology plus structural elements.
Groups places into room, corridor, and hall abstractions.
Top-level root for the single building.
The chosen node set is task-oriented and compositional.
Semantic attributes support high-level tasks; geometry and edges support motion planning.
A multi-story building can insert a level layer between building and rooms.
Mechanism: how SPE updates the graph
SPIN fills each DSG layer from sensor data.
| Stage | Input / method | DSG output |
|---|---|---|
Mesh / Robot | Kimera-VIO, RPGO, Mesher, Semantics | Layer 1 mesh and robot pose graph |
Humans | SMPL mesh estimation, skeleton consistency, dynamic masking | Agent node, human pose graph, human mesh |
Objects | Semantic mesh clustering, CAD model fitting, TEASER++ | Object centroid, bbox, pose, class |
Places / Rooms | ESDF topology, structural labels, 2D ESDF section, majority voting | Place graph, structures, room labels, room adjacency |
streaming visual-inertial data
metric-semantic mesh and robot node
dynamic agent pose graph
static object nodes
topology and room graph
query-ready spatial representation
Human nodes are not raw single-image estimates. SPIN applies rejection and temporal consistency.
Discard detections near image boundaries or with bounding boxes under 30 px.
Check whether joint motion between detections is physically plausible.
Ray-cast only free space for human pixels so humans do not become static mesh artifacts.
The room parser avoids a full floor-plan reconstruction by slicing the ESDF.
Cut the 3D ESDF horizontally 0.3 m below the ceiling.
Keep distances above 0.2 m to suppress small openings and noise.
Assign places to rooms with position and neighborhood majority voting.
Add room adjacency when places across rooms are connected.
Evidence: which queries and reconstructions test it?
The experiments test robustness and expressiveness in a photorealistic simulator.
| Dataset | Environment | Humans | Purpose |
|---|---|---|---|
uH_01 | 65m x 65m Unity office | 12 | Base crowded-scene setting |
uH_02 | same simulator | 24 | Medium crowding |
uH_03 | same simulator | 60 | Strong dynamic-agent stress test |
In crowded scenes, VIO robustness and dynamic masking are both necessary.
- 2-point RANSAC preserves or improves static EuRoC performance.
- DVIO lowers trajectory error on uHumans compared with Kimera-VIO.
- Removes human contrails from the static mesh.
- Improves mesh error even with ground-truth poses.
Pose accuracy alone is insufficient in dynamic scenes; the mesh update must also treat moving regions correctly.
Humans and static objects share Layer 2, but they are inferred differently.
- Filtered detections improve over raw single-image estimates.
- Pose-graph tracking gives the lowest localization error.
Cluster class-specific semantic mesh regions into object instances.
Register CAD keypoints to the mesh with TEASER++.
uH_01 place-to-room classification reaches 99.89% precision and 99.84% recall.
Usage / Limits: which robot queries is it useful for?
Section VI shows what a DSG enables as a robot-facing representation.
Bounding boxes form a BVH-like structure for faster collision checking.
Queries such as where a person was at time t become natural.
Rarely observed graph branches can be pruned while retaining useful abstractions.
Mesh and agent descriptions can feed short-term scene dynamics simulation.
The hierarchy of bounding boxes resembles a Bounding Volume Hierarchy and can speed up collision checks. Connected subgraphs of objects and places support high-level commands such as object search.
For long-term autonomy, the robot can prune a room branch and its descendants, or keep cheap object summaries while dropping expensive mesh details.
Takeaway
(In progress...)
Comments