핵심 요약
CUT3R는 매 입력 이미지를 통해 persistent scene state를 갱신하고, 그 state에서 metric pointmap, camera pose, unseen-view structure를 읽어내는 recurrent 3D perception model이다.
CUT3R는 scene마다 백지 상태에서 최적화하던 3D reconstruction을, 관측이 들어올수록 갱신되는 learned state로 바꾼다.
Persistent State
image stream의 scene content를 압축 저장하고 online update 지원.
World-frame Pointmaps
공통 world coordinate에서 metric pointmap 직접 예측.
Raymap Query
virtual camera raymap으로 unseen-view geometry와 color readout.
Broad Input Conditions
video, unordered photo, static/dynamic scene, sparse observation 처리.
CUT3R는 optimization memory가 아니라 model memory로 3D scene을 이어가는 논문으로 읽으면 이해가 쉽다. 핵심은 pointmap 출력 자체보다, scene을 계속 갱신하고 다시 물어볼 수 있게 만드는 state다.
scene별 최적화
현재 관측에서 구조를 만들기 때문에 sparse, degenerate, ill-posed 조건에 취약.
pairwise 예측 후 정렬
pairwise pointmap 예측은 강하지만 multi-view 사용에는 보통 offline global alignment 필요.
persistent state readout
recurrent state를 유지하며 world-frame pointmap과 query-view structure를 online readout.
논문 상세 정리
아래부터는 기존 논문 내용을 최대한 담은 상세 해석이다. 핵심 흐름에서 벗어나는 배경지식, related work, 학습 세부 조건, 부가 평가 조건은 접어두었다.
Problem: scene을 매번 새로 푸는 한계
CUT3R의 출발점은 인간이 장면을 볼 때처럼 이전 관측을 압축해 기억하고, 새 관측이 들어올 때 3D mental model을 갱신할 수 있어야 한다는 문제의식이다. 기존 3D reconstruction은 scene마다 blank slate에서 시작하는 경우가 많아, sparse observation, degenerate camera motion, non-overlapping view처럼 관측이 부족하거나 어려운 조건에서 취약해진다.

논문의 문제 제기는 현재 관측만으로 3D를 푸는 방식에서 관측을 누적한 state를 읽는 방식으로 이동한다.
매 scene에서 현재 관측으로 구조와 카메라를 다시 추정.
sparse, non-overlapping, dynamic view에서 정렬과 최적화가 불안정.
DUSt3R 계열은 강력하지만 multi-view online state가 약함.
scene content를 state에 저장하고 update/readout으로 3D를 예측.
Abstract와 Introduction은 모두 continuous 3D perception을 위한 persistent state가 필요하다는 주장으로 모인다.
| 문제 축 | 기존 접근의 병목 | CUT3R의 관점 |
|---|---|---|
| Few observations | 관측이 적으면 geometry와 pose가 ill-posed | 학습된 3D prior를 state에 저장 |
| Longer observation | 새 관측을 기존 구조와 안정적으로 통합해야 함 | state token을 recurrent하게 update |
| Unseen regions | 보이지 않은 영역은 직접 관측 없이는 추론 어려움 | virtual camera raymap으로 state readout |

Related Work 맥락 자세히 보기
Related Work는 연구를 단순 나열하기보다, CUT3R가 왜 persistent state를 제안하는지 보여주는 대비 구조로 읽는 편이 좋다.
| 연구 흐름 | 얻는 점 | 남는 한계 |
|---|---|---|
| SfM / SLAM / NeRF / 3DGS | scene별 geometry 최적화 | sparse/degenerate 관측에서 취약, scene마다 재시작 |
| DUSt3R / MASt3R | pairwise pointmap prediction으로 강한 3D prior 제공 | multi-view 통합에 offline global alignment 필요 |
| Continuous reconstruction | online update와 memory 개념 도입 | known camera, static scene, observed cache 중심인 경우 많음 |
| Dynamic scene priors | dynamic monocular video 처리 | per-video optimization, pairwise formulation, explicit state 부족 |
Mechanism: persistent state를 어떻게 update/readout하나
방법론의 핵심은 image token과 state token이 transformer decoder 안에서 상호작용하고, 그 결과로 state는 갱신되고 현재 view의 3D output은 즉시 읽힌다는 점이다. 따라서 CUT3R는 “pointmap을 예측하는 모델”이라기보다, state를 통해 계속 장면을 축적하는 recurrent 3D model로 보는 것이 자연스럽다.
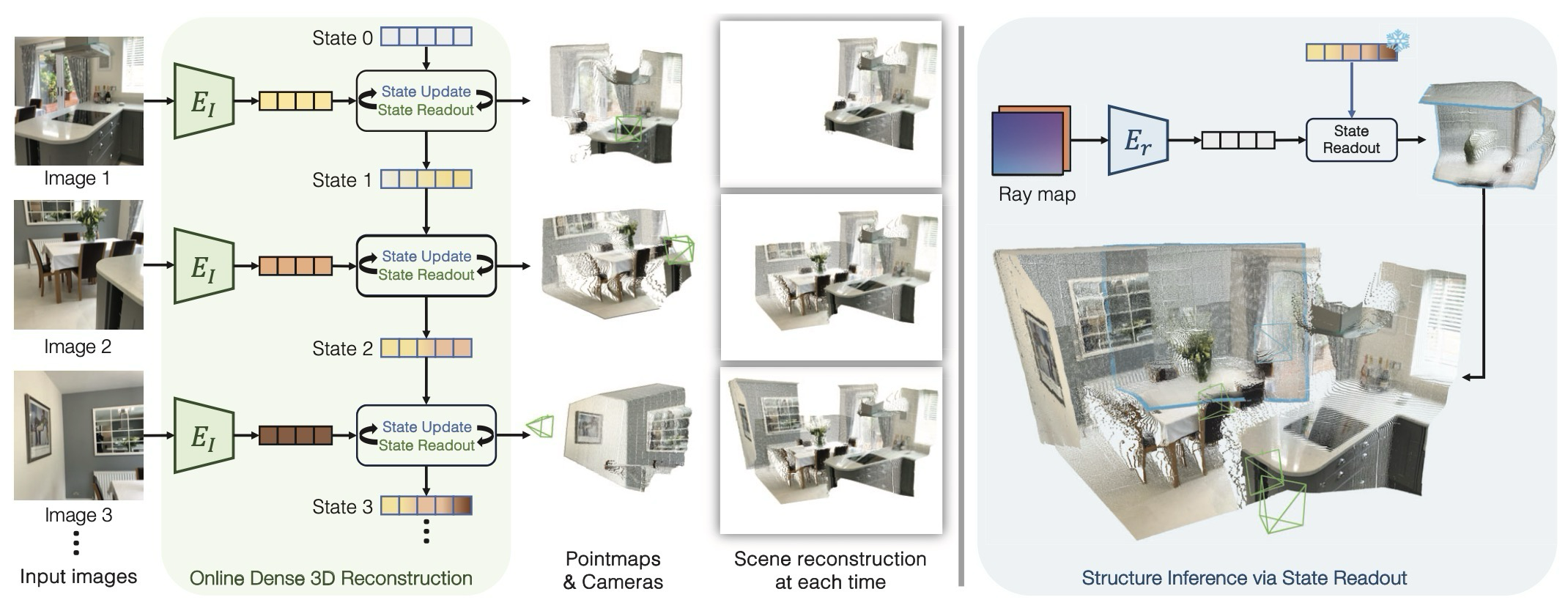
Method는 입력 image를 state와 섞고, 업데이트된 state에서 현재 view와 virtual view를 읽어내는 구조로 정리된다.
| 구간 | 무엇을 담당하나 | 핵심 장치 |
|---|---|---|
| Image encoding | 입력 frame을 feature token으로 변환 | DUSt3R pretrained ViT-Large encoder |
| State interaction | 현재 image token과 이전 state가 bidirectional interaction | learnable state token, interconnected transformer decoders |
| Readout heads | self/world pointmap, confidence, pose 예측 | self head, world head, pose head |
| Raymap query | 새 관측 없이 unseen view 구조와 color 추론 | 6-channel raymap, lightweight raymap encoder |
CUT3R의 중요한 선택은 state를 explicit map으로 두지 않고 compressed token state로 유지한다는 점이다.
pairwise prediction을 모아 offline alignment 수행.
state token이 scene context를 압축 저장.
streaming input과 unseen-view query를 같은 framework에서 처리.
DUSt3R / MASt3R 계열에서 이어받은 요소 보기
CUT3R는 DUSt3R/MASt3R식 pointmap prior를 출발점으로 삼지만, pairwise 결과를 나중에 정렬하는 방식이 아니라 state token을 계속 갱신하는 방향으로 바꾼다.
| 요소 | 기존 계열의 역할 | CUT3R에서의 처리 |
|---|---|---|
| ViT encoder | image pair에서 강한 geometric feature 추출 | DUSt3R pretrained encoder를 recurrent state update의 입력 feature로 사용 |
| Pointmap | 각 pixel을 3D point로 직접 예측 | self/world pointmap을 모두 예측해 현재 view와 누적 world frame을 연결 |
| Confidence loss | 불확실한 point prediction의 영향을 조절 | state에서 읽은 pointmap에도 confidence-weighted regression 적용 |
| Global alignment | pairwise prediction을 후처리로 묶는 단계 | state token이 sequence context를 누적하므로 online readout에 더 가까움 |
각 시점의 image는 encoder를 거쳐 token이 되고, pose token 및 이전 state와 함께 decoder에 들어간다. decoder는 image token을 state context로 보정하고, 동시에 state를 다음 시점으로 업데이트한다.
출력 head는 self-frame pointmap, world-frame pointmap, camera pose를 동시에 예측한다. world frame은 첫 번째 image coordinate로 정의되며, pointmap을 누적하면 dense reconstruction이 된다.
virtual camera는 origin과 ray direction을 담은 6-channel raymap으로 표현된다. raymap은 scene content를 새로 제공하는 입력이 아니므로 state를 업데이트하지 않고 readout만 수행한다. encoded ray token \(F_r\)는 persistent state와 상호작용한 뒤 readout token \(F'_r\)가 된다.
Training objective / notation 보기
학습은 pointmap regression, pose regression, raymap RGB consistency를 함께 사용한다. metric-scale annotation이 있으면 model이 metric pointmap을 직접 학습하도록 scale을 고정한다.
CUT3R의 수식은 DUSt3R식 pointmap head에 persistent state를 붙인 형태다. state token, pose token, image token이 어떤 출력으로 이어지는지 분리해 읽으면 된다.
| Notation | 의미 | 읽는 포인트 |
|---|---|---|
| \(I_t\), \(F_t\) | time \(t\)의 image와 image feature token | 새 observation이 image encoder를 통해 recurrent loop에 들어감. |
| \(z\), \(z'_t\) | decoder 전후의 pose token | camera pose head는 갱신된 pose token에서 pose를 읽음. |
| \(s_{t-1}\), \(s_t\) | 현재 image를 보기 전후의 persistent scene state | scene memory가 frame마다 누적되는 핵심 변수. |
| \(F'_t\) | state와 상호작용한 뒤의 image feature | 현재 view의 pointmap, confidence, pose readout의 입력. |
| \(\hat X_t^{\mathrm{self}}\), \(\hat X_t^{\mathrm{world}}\) | 현재 camera frame과 공통 world frame의 pointmap | self/world head를 나눠 현재 view와 누적 reconstruction을 연결. |
| \(C_t^{\mathrm{self}}\), \(C_t^{\mathrm{world}}\) | 각 pointmap의 confidence map | pointmap regression에서 불확실한 pixel의 영향을 조절. |
| \(R\), \(F_r\), \(F'_r\) | 6-channel raymap query, encoded ray token, state-conditioned ray token | state를 갱신하지 않고 unseen view 구조와 color를 readout. |
| \(\hat q_t\), \(\hat\tau_t\), \(\hat s\) | rotation, translation, scale prediction | pose/scale-normalized loss에서 camera trajectory를 학습. |
학습 구성과 구현 세부 보기
학습 세부 조건은 핵심 구조를 이해한 뒤 확인하면 좋다. 중요한 점은 다양한 annotation level을 가진 dataset을 함께 사용한다는 것이다.
| 항목 | 내용 | 의미 |
|---|---|---|
| Data scale | 32개 이상 dataset | synthetic/real, static/dynamic, indoor/outdoor, object/scene-level 포함 |
| Curriculum | 4-view static에서 dynamic/partial annotation, high-resolution, long context로 확장 | 짧은 안정 학습에서 긴 state 학습으로 이동 |
| Architecture | DUSt3R ViT-Large encoder, ViT-Base decoder, 768 state tokens | 강한 pairwise 3D prior를 recurrent state 구조로 확장 |
| Raymap encoder | 2-block lightweight encoder | virtual camera query를 image token처럼 readout |
Evidence: 어떤 claim을 어떻게 검증했나
평가는 각 실험이 어떤 claim을 지지하는지를 기준으로 정리된다. CUT3R는 depth, pose, 3D reconstruction, state update, unseen-view inference를 통해 “persistent state가 다양한 3D perception task에 재사용된다”는 주장을 검증한다.
핵심 평가는 depth/pose/reconstruction이고, state update와 raymap query는 persistent state의 의미를 보여주는 분석이다.
| 평가 축 | 근거 | 확인할 점 |
|---|---|---|
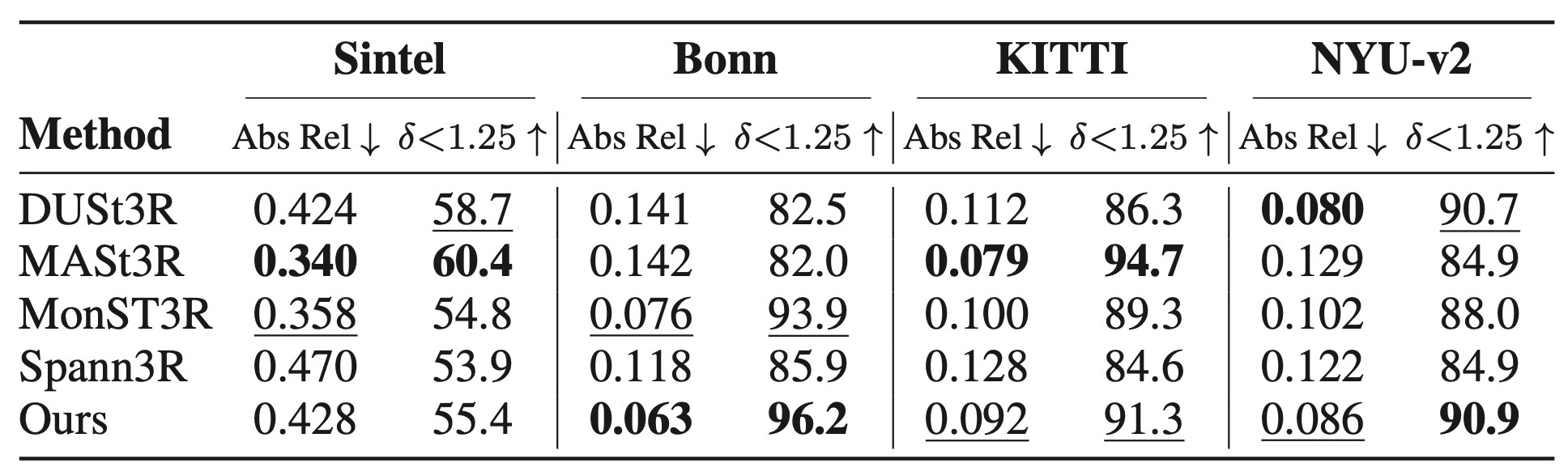
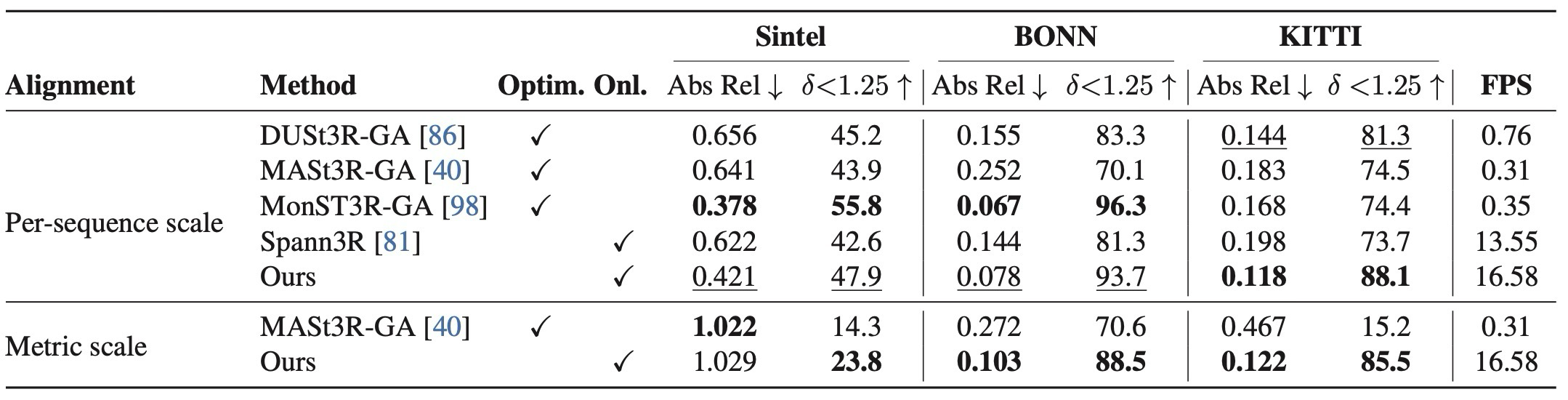
| Depth estimation | Table 1-2 | single-frame zero-shot과 video depth에서 기존 pairwise/global alignment 계열과 비교. |
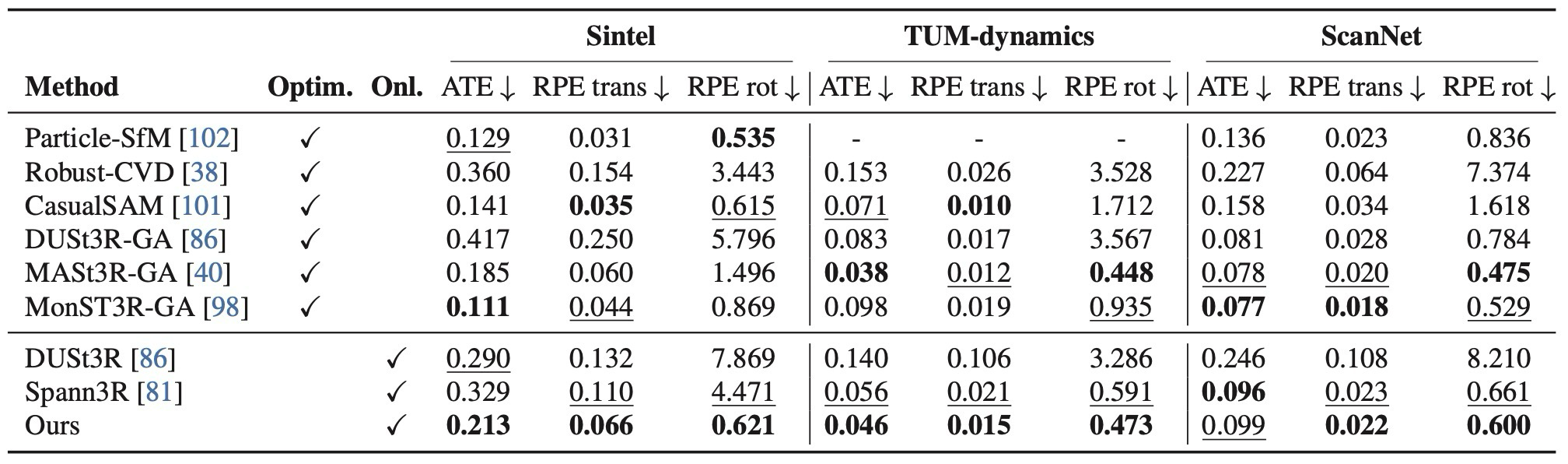
| Camera pose | Table 3 | online method 중 강한 pose 성능, dynamic scene에서의 안정성. |
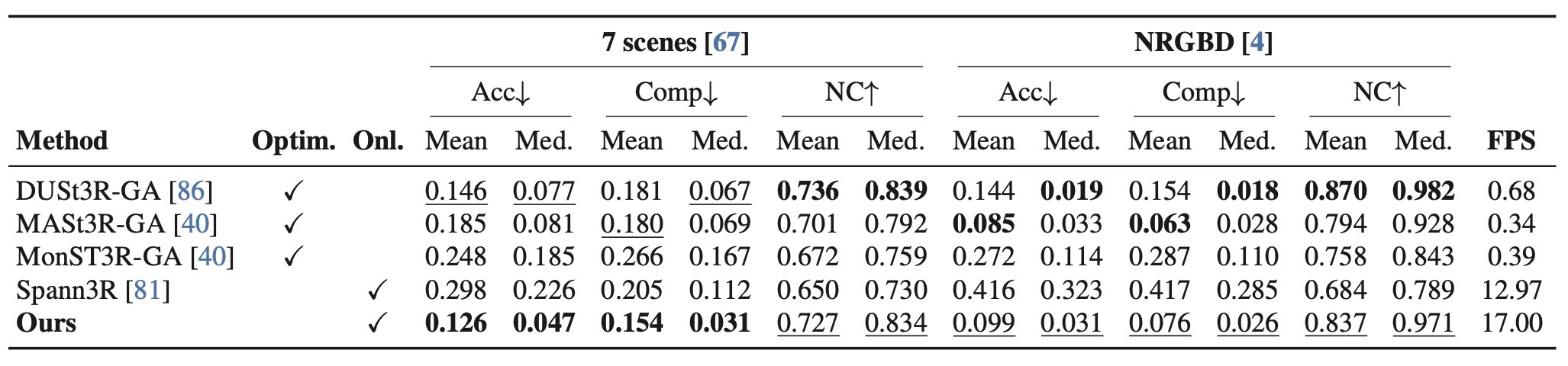
| 3D reconstruction | Table 4, Figure 4 | sparse image collection과 in-the-wild video에서 online reconstruction 품질 확인. |
| 분석 축 | 근거 | 의미 |
|---|---|---|
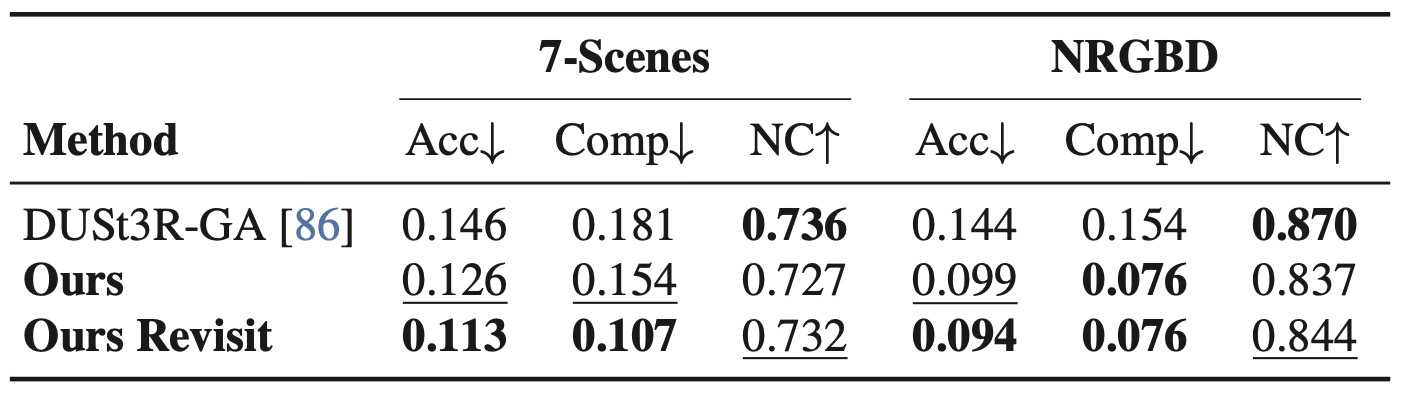
| State update | Table 5, Figure 5 | 더 많은 observation과 revisiting이 state 품질을 개선. |
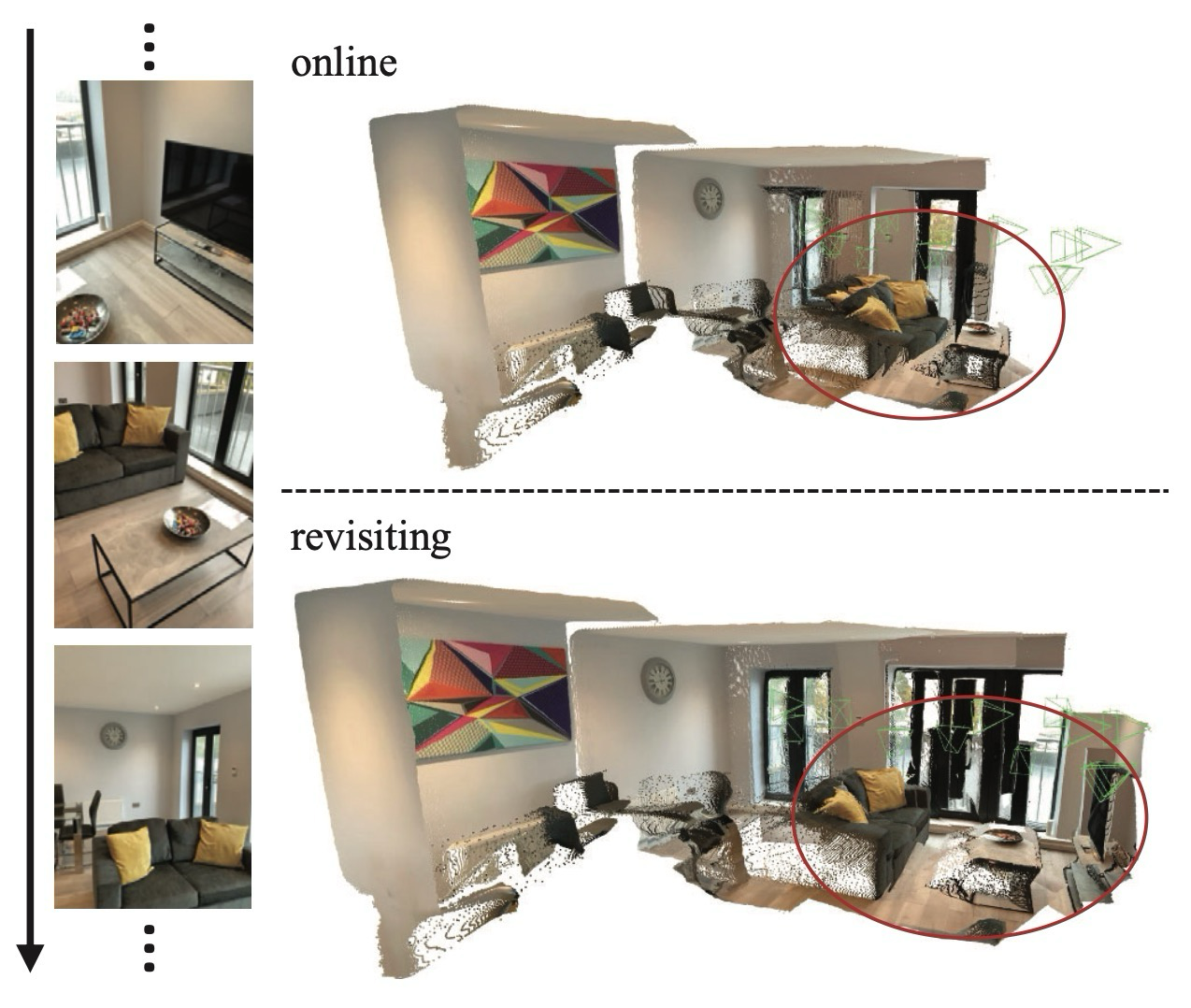
| Unseen readout | Figure 6 | state가 관측되지 않은 view의 structure를 생성할 수 있음을 시각화. |


평가 결과는 CUT3R가 특정 task 하나의 모델이 아니라, state를 여러 3D perception readout에 재사용하는 모델임을 보여준다.
single-frame과 video depth에서 zero-shot generalization 확인.
optimization-based method와의 격차는 남지만 online method 중 강한 성능.
online 방식으로 sparse collection과 web video reconstruction 처리.
observation 증가와 revisiting에서 state 품질 개선.
평가 설정과 baseline 세부 보기
baseline과 metric은 task마다 다르다. 핵심은 pairwise/global alignment 계열과 online state 기반 CUT3R를 같은 task에서 비교하는 것이다.
| Task | Dataset / metric | 주요 baseline |
|---|---|---|
| Single depth | KITTI, Sintel, Bonn, NYU-v2 / depth error | DUSt3R, MASt3R, MonST3R 등 |
| Video depth | per-sequence scale alignment / FPS 포함 | DUSt3R-GA, MASt3R-GA, Spann3R, MonST3R-GA |
| Pose | Sintel, TUM-dynamic, ScanNet / ATE, RPE | online/optimization-based pose methods |
| Reconstruction | 7-Scenes, NRGBD / accuracy, completion, normal consistency | Spann3R, DUSt3R-GA 등 |
Usage / Limits: 언제 유용하고 어디서 약한가
CUT3R는 camera calibration이나 explicit global alignment 없이도 image stream을 online으로 3D state에 통합해야 하는 상황에 잘 맞는다. 반면 매우 긴 sequence에서는 explicit global alignment가 없기 때문에 drift가 누적될 수 있고, 큰 viewpoint extrapolation에서는 deterministic readout이 high-frequency detail을 흐리게 만들 수 있다.
| 구분 | 정리 | 이유 |
|---|---|---|
| 잘 맞는 상황 | streaming video, sparse photo collection, camera 정보가 부족한 scene | state update/readout만으로 pointmap과 pose를 online 예측 |
| 강한 조건 | static/dynamic scene이 섞인 다양한 3D perception task | 32개 이상 dataset과 partial annotation을 사용해 broad prior 학습 |
| 약한 조건 | 매우 긴 sequence, 큰 viewpoint extrapolation, 세밀한 texture/detail 요구 | explicit global alignment 부재와 deterministic generation 한계 |
느낀점
(진행중...)
Problem: the limit of rebuilding every scene from scratch
CUT3R starts from the idea that 3D perception should work more like human scene understanding: compress previous observations into memory and update a 3D mental model as new images arrive. Many reconstruction pipelines start each scene from a blank slate, so sparse observations, degenerate motion, and non-overlapping views can make the problem unstable.
The paper moves from solving 3D from current observations to reading 3D from an accumulated state.
Structure and camera are estimated again for each scene.
Sparse, non-overlapping, and dynamic views make alignment unstable.
DUSt3R-like models are strong, but online multi-view state is limited.
Store scene content in state and predict 3D through update/readout.
The abstract and introduction converge on the need for a persistent state for continuous 3D perception.
| Problem axis | Bottleneck | CUT3R's view |
|---|---|---|
| Few observations | Geometry and pose are ill-posed with limited evidence | Store a learned 3D prior in state |
| Longer observation | New views must be integrated into the existing scene | Update state tokens recurrently |
| Unseen regions | Unobserved areas are hard to infer from observation alone | Read out the state with a virtual-camera raymap |
Related work context
The related work is best read as a contrast that explains why CUT3R needs persistent state.
| Research line | Strength | Remaining limit |
|---|---|---|
| SfM / SLAM / NeRF / 3DGS | Scene-wise geometry optimization | Fragile under sparse or degenerate observations |
| DUSt3R / MASt3R | Strong pairwise pointmap prediction | Offline global alignment often needed for multi-view use |
| Continuous reconstruction | Online update and memory concepts | Often assumes known cameras, static scenes, or observed-cache memory |
| Dynamic scene priors | Dynamic monocular video handling | Per-video optimization, pairwise formulation, or limited explicit state |
Mechanism: how does persistent state update and read out 3D?
The core mechanism is that image tokens and state tokens interact inside transformer decoders. The state is updated, and the current view's 3D output is read immediately. CUT3R is therefore better understood as a recurrent 3D model that accumulates the scene through state, not only as a pointmap predictor.
The method can be summarized as mixing image tokens with state, updating the state, and reading current or virtual views from it.
| Part | Role | Core device |
|---|---|---|
| Image encoding | Converts the input frame into feature tokens | DUSt3R pretrained ViT-Large encoder |
| State interaction | Lets current image tokens and previous state interact | Learnable state tokens, interconnected transformer decoders |
| Readout heads | Predicts self/world pointmaps, confidence, and pose | Self head, world head, pose head |
| Raymap query | Infers unseen-view structure and color without a new observation | 6-channel raymap, lightweight raymap encoder |
The key design choice is to keep scene memory as compressed state tokens rather than as an explicit map.
Collect pairwise predictions and run offline alignment.
Use state tokens to compress scene context.
Handle streaming input and unseen-view queries in one framework.
What is inherited from DUSt3R / MASt3R-style models?
CUT3R starts from DUSt3R/MASt3R-style pointmap priors, but replaces post-hoc pairwise alignment with recurrent state updates.
| Element | Role in prior models | How CUT3R uses it |
|---|---|---|
| ViT encoder | Extracts strong geometric features from image pairs | Uses a DUSt3R-pretrained encoder as input features for recurrent state update |
| Pointmap | Predicts a 3D point for each pixel | Predicts both self-frame and world-frame pointmaps |
| Confidence loss | Controls uncertain point predictions | Applies confidence-weighted regression to pointmaps read from the state |
| Global alignment | Combines pairwise predictions as a post-process | Replaces much of that role with online state accumulation and readout |
Each image is encoded into tokens and passed to the decoder with a pose token and the previous state. The decoder refines the image tokens with state context and updates the state for the next time step.
The heads predict a self-frame pointmap, a world-frame pointmap, and the camera pose. The world frame is defined by the first image coordinate system, and accumulated pointmaps form dense reconstruction.
A virtual camera is represented as a 6-channel raymap containing ray origins and directions. Because a raymap does not add new scene content, it reads from the state without updating it. The encoded ray token \(F_r\) interacts with the persistent state and becomes the readout token \(F'_r\).
Training objective / notation
The training objective combines pointmap regression, pose regression, and raymap RGB consistency. When metric-scale annotation is available, the model is trained to predict metric pointmaps directly.
CUT3R equations are DUSt3R-style pointmap heads attached to a persistent scene state. The easiest way to read them is to separate state tokens, pose tokens, image tokens, and the outputs read from them.
| Notation | Meaning | How to read it |
|---|---|---|
| \(I_t\), \(F_t\) | Image and image feature token at time \(t\) | Each new observation enters the recurrent loop through the image encoder. |
| \(z\), \(z'_t\) | Pose token before and after decoder interaction | The camera pose head reads pose from the updated pose token. |
| \(s_{t-1}\), \(s_t\) | Persistent scene state before and after the current image | The main variable that carries scene memory over time. |
| \(F'_t\) | State-conditioned image feature | Input to current-view pointmap, confidence, and pose readouts. |
| \(\hat X_t^{\mathrm{self}}\), \(\hat X_t^{\mathrm{world}}\) | Pointmaps in the current camera frame and shared world frame | Self/world heads connect the current view to accumulated reconstruction. |
| \(C_t^{\mathrm{self}}\), \(C_t^{\mathrm{world}}\) | Confidence maps for the two pointmaps | Control uncertain pixels in pointmap regression. |
| \(R\), \(F_r\), \(F'_r\) | 6-channel raymap query, encoded ray token, and state-conditioned ray token | Reads unseen-view structure and color without updating the state. |
| \(\hat q_t\), \(\hat\tau_t\), \(\hat s\) | Predicted rotation, translation, and scale terms | Used in pose and scale-normalized losses. |
Training setup and implementation details
The important point is that CUT3R learns from many datasets with different annotation levels.
| Item | Content | Meaning |
|---|---|---|
| Data scale | More than 32 datasets | Synthetic/real, static/dynamic, indoor/outdoor, object/scene-level data |
| Curriculum | Static 4-view training, dynamic/partial annotations, high-resolution, long context | Moves from stable short sequences to long-state training |
| Architecture | DUSt3R ViT-Large encoder, ViT-Base decoder, 768 state tokens | Extends a strong pairwise 3D prior into recurrent state |
| Raymap encoder | 2-block lightweight encoder | Reads virtual-camera queries like image tokens |
Evidence: which claims are tested?
The evaluation is clearest when each experiment is tied to a claim. CUT3R tests depth, pose, 3D reconstruction, state update, and unseen-view inference to support the claim that persistent state can serve multiple 3D perception readouts.
Depth, pose, and reconstruction are the main evaluations, while state update and raymap query explain what the persistent state contributes.
| Axis | Evidence | What to check |
|---|---|---|
| Depth estimation | Table 1-2 | Single-frame zero-shot and video depth compared with pairwise/global-alignment methods. |
| Camera pose | Table 3 | Strong online pose performance, especially under dynamic scenes. |
| 3D reconstruction | Table 4, Figure 4 | Online reconstruction from sparse image collections and in-the-wild videos. |
| Axis | Evidence | Meaning |
|---|---|---|
| State update | Table 5, Figure 5 | More observations and revisiting improve state quality. |
| Unseen readout | Figure 6 | The state can synthesize structure for views that were not observed. |
The results show CUT3R as a state-based model whose readouts can support multiple 3D perception tasks.
Checks zero-shot generalization in single-frame and video depth.
Still trails optimization-heavy methods in some cases, but is strong among online methods.
Handles sparse collections and web videos with an online model.
Improves with more observations and revisiting.
Evaluation setup and baselines
Each task uses different metrics and baselines. The key comparison is between pairwise/global-alignment methods and CUT3R's online state-based inference.
| Task | Dataset / metric | Main baselines |
|---|---|---|
| Single depth | KITTI, Sintel, Bonn, NYU-v2 / depth error | DUSt3R, MASt3R, MonST3R |
| Video depth | Per-sequence scale alignment / FPS | DUSt3R-GA, MASt3R-GA, Spann3R, MonST3R-GA |
| Pose | Sintel, TUM-dynamic, ScanNet / ATE, RPE | Online and optimization-based pose methods |
| Reconstruction | 7-Scenes, NRGBD / accuracy, completion, normal consistency | Spann3R, DUSt3R-GA |
Usage / Limits: when is it useful?
CUT3R is useful when an image stream must be integrated into a 3D state without camera calibration or explicit global alignment. It is weaker for very long sequences because there is no explicit global alignment, and deterministic readout can blur high-frequency detail under large viewpoint extrapolation.
| Category | Summary | Reason |
|---|---|---|
| Good fit | Streaming videos, sparse photo collections, scenes with limited camera information | Predicts pointmaps and poses online through state update/readout |
| Strong condition | Mixed static/dynamic scenes and broad 3D perception tasks | Uses broad datasets and partial annotations to learn a general prior |
| Weak condition | Very long sequences, large viewpoint extrapolation, fine texture/detail needs | No explicit global alignment and deterministic generation limits |
Takeaway
(In progress...)
Comments