핵심 요약
DROID-SLAM은 update operator가 예측한 flow revision을 Dense Bundle Adjustment(DBA) layer로 넘겨, camera pose와 pixelwise inverse depth를 반복적으로 함께 업데이트하는 deep visual SLAM 시스템이다.
신경망이 SLAM을 대체한다기보다, learned correspondence update와 기하학적 Bundle Adjustment를 하나의 recurrent loop로 묶어 pose-depth 추정을 반복 개선하는 구조.
Frame-Graph Update
임의 개수의 frame graph에서 camera pose와 inverse depth를 동시에 반복 업데이트.
Dense Bundle Adjustment
flow revision과 confidence를 reprojection objective로 바꿔 Gauss-Newton pose-depth update 수행.
Full SLAM System
frontend local BA와 backend global BA/loop closure를 비동기 thread로 구성.
Cross-Sensor Generalization
monocular synthetic video로 학습한 단일 모델을 stereo/RGB-D 입력에도 재학습 없이 활용.
DROID-SLAM의 핵심은 딥러닝이 기하학을 없앤 것이 아니라, 기하학적 최적화가 recurrent network의 내부 연산이 되었다는 점이다. 그래서 같은 모델이 monocular로 학습되어도 stereo/RGB-D의 추가 제약을 테스트 시점의 optimization objective 안으로 자연스럽게 받을 수 있다.
update operator가 correspondence revision을 만들고, DBA가 이를 pose-depth 갱신으로 바꾸는 순서.
학습은 monocular에서 출발하지만, test-time objective에 stereo/RGB-D 관측 제약을 추가할 수 있다.
학습의 기본 입력
scale ambiguity가 있지만, recurrent update와 DBA를 통해 pose-depth를 공동 추정.
추가 기하 제약
재학습 없이 stereo correspondence를 활용해 depth/scale 제약을 강화.
깊이 관측 활용
depth sensor 입력을 테스트 시점의 관측 제약으로 받아 robustness와 accuracy를 개선.
논문 상세 정리
아래부터는 기존 논문 내용을 최대한 담은 상세 해석이다. 핵심 흐름에서 벗어나는 배경지식, notation, 부가 자료는 접어두었다.
Problem: learned SLAM은 무엇을 다시 묻는가
DROID-SLAM은 딥러닝 기반의 SLAM 시스템이며, Dense Bundle Adjustment Layer를 통해 camera pose와 pixelwise depth를 반복적으로 업데이트한다. DROID-SLAM은 정확도가 높아 기존 연구들에 비해 큰 성능향상을 달성했으며, 강건하여 치명적인 실패(catastrophic failure)가 적게 발생한다. 또한 monocular video를 통해 학습한 모델에 대해, 테스트시에 stereo나 RGB-D video를 입력으로 넣어주었을 때 성능이 향상되었다고 한다.
DROID-SLAM의 문제의식은 “정확한 기하 최적화”와 “실세계 robustness” 사이의 간극에서 출발한다.
BA 기반 최적화는 정확하지만 tracking failure, drift, optimization divergence에 취약.
일부 failure에는 강하지만 benchmark accuracy와 full SLAM capability가 부족.
learned correspondence를 dense BA 안에서 pose-depth update로 바꿀 수 있는가?
recurrent update와 DBA를 결합하면 accuracy, robustness, sensor generalization을 동시에 얻을 수 있음.
Context: classical SLAM은 어디서 실패하나
SLAM은 long-term trajectory tracking에 초점을 맞춘 SFM(Structure-From-Motion)의 특별한 형태(special form)이며, 로보틱스(특히 자율주행)에서 중요한 역할을 한다. DROID-SLAM에서는 visual SLAM을 다루며, 보통 monocular, stereo, RGB-D와 같은 카메라 센서를 다룬다.
SLAM 문제는 여러 관점에서 접근되어 왔으며, 초기에는 확률적(probabilistic), 필터링 기반(filtering based) 접근법을 사용했고, 지도(map)와 카메라 포즈(camera pose)를 번갈아가며 최적화 하였다.
최근 현대(modern) SLAM 방식은 least-squares optimization이 가능한데, 정확도를 높이는 핵심 요소로 full BA(Bundle Adjustment)가 단일 최적화 문제에서 카메라 포즈와 3차원 지도를 동시에(jointly) 최적화 할 수 있다는 것이다. 또한 최적화 기반 SLAM의 장점은 서로 다른 센서를 쉽게 활용할 수 있도록 수정이 가능하다는 점이다. 예를 들어 ORB-SLAM3은 monocular, stereo, RGB-D, IMU 센서를 지원하며, 이외에도 다른 현대 SLAM 시스템들은 다양한 카메라 모델을 지원한다. 하지만 이렇게 많은 발전(progress)이 있었음에도 불구하고, 현대 SLAM 시스템들은 많은 실세계 응용(real-world application)에서 요구하는 강건성(robustness)이 부족하며, 실패 요인으로는 특징 추적이 끊어지거나, 최적화 알고리즘에서 발산하거나, drift가 축적되는 것이 있다.
딥러닝은 이러한 실패 요인들에 대한 해결책을 제시했는데, 이전 연구에서는 수작업(hand-crafted)으로 추출한 특징을 신경망 기반 3차원 표현(neural 3D representation)으로 학습한 특징으로 대체하거나, 학습된 에너지 항(energy term)을 고전 최적화 벡엔드와 결합하였다. 이러한 시스템들은 때때로 더 강건하였지만, 일반적인 벤치마크(benchmark)에서는 고전적인 방법들에 비해 정확도가 떨어졌다.
본 연구에서는 딥러닝 기반의 DROID-SLAM을 소개하며, 이는 매우 어려운 벤치마크에서 기존의 고전 및 학습 기반 SLAM 시스템들과 매우 큰 격차를 보이며, SOTA(State-Of-The-Art)급 성능을 보여준다.
특히 아래와 같은 이점을 가진다.
DROID-SLAM이 앞부분에서 주장하는 장점은 성능 수치보다 “같은 모델이 여러 센서/데이터셋에서 무너지지 않는다”는 방향으로 읽는 것이 좋다.
| 주장 | 핵심 근거 | 읽는 포인트 |
|---|---|---|
| High Accuracy | TartanAir, ETH3D, EuRoC, TUM-RGBD에서 기존 방법 대비 큰 오차 감소 | 딥러닝 기반이지만 classical SLAM 대비 정확도도 밀리지 않음 |
| High Robustness | ETH3D 30/32 시퀀스 추적, 주요 벤치마크에서 catastrophic failure 감소 | tracking loss와 drift 누적 문제를 줄이는지가 핵심 |
| Strong Generalization | synthetic TartanAir monocular 학습 후 여러 real dataset/sensor에 적용 | DBA layer가 test-time sensor constraint를 받아들이는 구조적 장점 |
Contribution 세부 수치 보기
Introduction에서 제시한 장점은 정확도, 실패율, 일반화 성능으로 나눠 읽으면 논문의 주장 구조가 선명해진다.
| 주장 | 세부 근거 | 읽는 포인트 |
|---|---|---|
| High Accuracy |
| deep SLAM이 단순히 robust한 대체재가 아니라, classical SLAM 대비 accuracy도 강하게 주장한다는 근거 |
| High Robustness |
| 평균 오차보다 먼저 tracking loss가 얼마나 줄었는지 확인해야 하는 주장 |
| Strong Generalization |
| network가 모든 센서에 따로 맞춰진 것이 아니라, optimization layer가 추가 관측 제약을 받아들이는 구조라는 점이 핵심 |
DROID-SLAM의 강력한 성능과 일반화는 DROID(Differentiable Recurrent Optimization-Inspired Design)라는 구조 때문이며, 이는 고전적인 접근법과 깊은 신경망(deep networks)의 이점이 결합된 미분가능한 end-to-end 구조를 의미한다. 특히 순환적 반복 업데이트(recurrent iterative updates) 구조로 이루어져 있으며, optical flow를 위한 RAFT 구조 기반이되 2가지의 핵심적인 새로운 아이디어를 소개한다.
이 부분은 “RAFT 구조를 가져왔다”보다, update 대상이 optical flow에서 SLAM state로 바뀌었다는 점이 핵심이다.
| 비교 축 | RAFT | DROID-SLAM | 읽는 포인트 |
|---|---|---|---|
| 업데이트 대상 | 두 frame 사이 optical flow | camera pose와 pixelwise inverse depth | flow 자체보다 SLAM 변수 개선이 목표 |
| 적용 범위 | pairwise image matching | 임의 개수의 frame graph | long trajectory와 loop closure까지 확장 |
| 기하 제약 | matching signal 중심 | DBA layer의 reprojection objective | learned update를 기하 최적화로 검증 |
논문이 선택한 핵심 방향은 pose/depth를 직접 회귀하지 않고, DBA가 풀 수 있는 correspondence target을 반복적으로 갱신하는 것이다.
pose와 depth를 한 번에 출력하면 long trajectory와 loop closure에서 기하 일관성을 유지하기 어렵다.
update operator는 correlation/residual/context를 보고 correspondence correction과 confidence를 예측한다.
DBA layer가 reprojection objective를 풀어 pose와 inverse depth를 jointly update한다.
첫 번째로, 반복적으로 optical flow를 업데이트하는 RAFT와 다르게, DROID는 카메라 포즈(camera pose)와 깊이(depth)를 업데이트 한다. 또한 RAFT의 업데이트는 2개의 프레임을 기반으로 동작하는 반면에, DROID의 업데이트는 임의의 개수의 프레임에 적용되어, 모든 카메라 pose와 depth map을 한 번에 조정하여 개선(joint global refinement)할 수 있게하는데, 이는 장기 궤적(long trajectories)및 루프 폐쇄(loop closure)를 위한 drift 최소화에 필수적이다.
두 번째로, DROID-SLAM에서 카메라 pose와 depth map의 각 업데이트는 미분가능한 DBA(Dense Bundle Adjustment) layer에서 수행되며, 이는 카메라 pose와 픽셀별(per-pixel) depth에 대해 optical flow의 현재 추정값과 최대한 일치하게끔 Gauss-Newton 업데이트를 진행한다. 해당 DBA layer는 기하학적 제약을 준수하며, 정확도와 강건성을 향상시키며, monocular 시스템이 재학습없이 stereo나 RGB-D 입력을 다룰 수 있게 한다.
이 대목의 핵심은 RAFT를 SLAM 변수 업데이트로 바꾸고, 그 업데이트를 DBA layer가 기하적으로 검증한다는 점이다. 즉 flow prediction, pose update, depth update가 따로 노는 구조가 아니라 하나의 반복 최적화 loop로 묶인다.
DeepV2D / BA-Net 비교 메모 보기
이 토글은 DROID-SLAM이 기존 deep geometry 방법과 어떻게 다른지 확인하는 짧은 비교 구간이다.
video depth와 pose를 반복적으로 다듬는 흐름을 제공.
학습 네트워크 안에 optimization 구조를 넣는 방향을 보여줌.
correspondence와 confidence를 예측하고 DBA가 pose/depth를 함께 갱신.
DROID-SLAM의 구조는 새로우며(novel), 이전에 비슷한 deep architecture로는 DeepV2D와 BA-Net이 있으며, 둘다 깊이 추정(depth estimation)에 초점을 맞추고 있었으며, 제한적인(limited) 결과를 보여주었다.
DeepV2D는 bundle adjustment를 직접 수행하기보다는, 깊이(depth) 업데이트와 카메라 포즈 업데이트를 번갈아 수행하는 방식을 사용하였고, BA-Net은 bundle adjustment layer를 포함하고 있으나 dense한 방식은 아니다. BA-Net의 경우, 소수의 계수(coefficients)만을 최적화하여 미리 예측된(pre-predicted) 깊이 맵들로 구성된 depth basis를 선형 결합(linearly combine)하는 방식인 반면, DROID-SLAM의 DBA layer는 이러한 depth basis에 의해 제한되지 않고 모든 픽셀의(per-pixel) 깊이에 대해 직접 최적화를 수행한다.
본 논문에서는 4개의 다른 데이터셋과 3개의 다른 센서 모달리티를 통해 확장 평가(extensive evaluation)를 수행했으며, 모든 경우에서 SOTA급 성능을 보여주었다. 또한 중요한 설계 선택 및 하이퍼파라미터를 설명하는 ablation study를 포함한다.
Gap: learned VO와 Bundle Adjustment 사이에 무엇이 비어 있나
DROID-SLAM은 direct/indirect 중 하나를 고르는 대신, full image 기반 matching signal과 reprojection objective를 결합한다.
| 계열 | 무엇을 쓰나 | 약점 / DROID의 선택 |
|---|---|---|
| Indirect SLAM | feature detection, descriptor, matching 후 reprojection error 최적화 | corner/edge 중심 정보에 의존하지만 objective는 비교적 smooth |
| Direct SLAM | image intensity/photometric error를 직접 모델링 | 정보량은 많지만 local minimum, rolling shutter, pyramid 설계에 민감 |
| DROID-SLAM | full image feature/correlation으로 correspondence를 만들고 reprojection error 최적화 | direct의 표현력과 indirect의 기하 objective를 recurrent DBA loop로 결합 |
Related Work 자세히 보기
Related Work는 DROID-SLAM이 RAFT식 correspondence update와 classical BA를 어떻게 연결하는지 확인하는 보충 구간이다.
| 계열 | 이어받은 점 | DROID-SLAM의 차이 |
|---|---|---|
| Optical flow | correlation volume과 recurrent update | flow 자체보다 SLAM state update에 사용 |
| Deep visual odometry | 학습 기반 pose/depth 추정 | pose/depth를 직접 출력하지 않고 optimization target을 생성 |
| Bundle adjustment | reprojection error 기반 기하 최적화 | differentiable dense BA layer로 network 안에 결합 |
현대 SLAM 시스템은 localization과 mapping을 동시에 최적화하는 joint optimization problem으로 다뤄진다. 특히 Visual SLAM은 monocular, stereo, RGB-D 이미지 기반 관측에 초점을 맞추며, 일반적으로 direct와 indirect 접근법으로 나뉜다.
Indirect 방식은 이미지를 먼저 intermediate representation(중간 표현)으로 변환하고, feature(특징)을 검출하여 feature descriptor를 붙인 뒤, 이미지 간 feature를 매칭한다. 이후 투영된 3D point와 이미지상에서의 위치 사이의 재투영 오차(reprojection error)를 최소화하면서, 카메라 위치와 3D point cloud를 최적화한다.
반면 direct 방식은 이미지 형성 과정(image formation process)을 모델링하고, photometric error를 최소화하는 objective function을 정의한다. 또한 indirect 방식 대비 line(선), intensity(세기) 변화와 같은 이미지의 더 많은 정보를 모델링할 수 있지만, 어려운 최적화 문제를 가지며, rolling shutter와 같은 기하학적 왜곡에 민감하다. 또한 local minimum을 피하기 위해 coarse-to-fine image pyramid와 같은 정교한 최적화 기법이 필요하다.
본 논문에서 제안하는 방법은 direct와 indirect 어느 한쪽에 명확히 속하지 않으며, direct 방식처럼 전체 이미지를 사용하여 indirect 방식보다 풍부한 정보를 활용하고, indirect 방식처럼 reprojection error를 최소화하는 방식을 사용해 image pyramid와 같은 복잡한 표현 없이도 최적화가 가능하다.
따라서 이 접근법은 indirect 방식의 smoother(부드러운) objective function과 direct 방식의 높은 modeling capacity를 동시에 활용한다.
원문 표현 확인

Fig. 1. DROID-SLAM 개요.dense correspondence, recurrent update, BA 기반 trajectory/depth refinement가 하나의 SLAM loop로 연결된다. → 이 문장은 문맥상
capacity of indirect approaches보다capacity of direct approaches로 읽는 편이 자연스럽다. DROID-SLAM의 핵심은 direct 계열의 dense image information과 indirect 계열의 smooth reprojection objective를 함께 쓰는 데 있다.
최근에는 딥러닝을 SLAM 시스템에 적용하려는 연구가 활발하다. 기존 연구들은 feature detection(특징 탐지), feature matching(특징 매칭), outlier rejection(이상치 제거), localization(위치 추정) 등 SLAM의 특정 하위 문제(subproblem)를 학습하는 데 집중했다.
예를 들어 SuperGlue는 feature matching과 verification을 수행하여 두 뷰 간 pose 추정을 더욱 강건하게 만든다. 본 논문에서 제안하는 네트워크는 Dusmanu et al의 연구에서 영감을 받아, keypoint localization 정확도를 높이기 위해 SfM 파이프라인에 신경망을 통합하였다.
일부 연구들은 SLAM 시스템을 end-to-end로 학습하는 접근을 시도했지만, 대부분 완전한 SLAM 시스템이 아닌, 소규모 reconstruction(2~12 프레임)에만 초점을 맞췄다. 이들은 loop closure나 global bundle adjustment와 같은 현대 SLAM의 핵심 기능(core capabilities)이 부족하여, DROID-SLAM이 다룬 대규모 reconstruction 수행에는 제한이 있다.
∇SLAM은 기존 SLAM 알고리즘을 미분 가능한 연산 그래프로 구현하여 reconstruction 단계의 오차를 센서 측정으로 역전파할 수 있게 했지만, 훈련 가능한 파라미터가 없기 때문에 모방한 고전 알고리즘의 정확도에 의존한다.
DeepFactors는 CodeSLAM을 기반으로 구축된 가장 완전한 deep SLAM 시스템으로, pose와 depth 변수를 동시에 최적화하고, 단거리 및 장거리 loop closure를 지원한다. 그러나 DeepFactors은 BA-Net과 비슷하게, 추론 중 학습된(learned) depth basis의 파라미터를 최적화하는 반면, DROID-SLAM은 학습된 basis에 의존하지 않고 모든 픽셀의 depth를 직접 최적화함으로써, 훈련 데이터셋에 과도하게 종속(tied)되지 않고 새로운 데이터셋에서도 더 일반화된 성능을 제공한다.
Mechanism: recurrent update와 DBA로 어떻게 푸나
Approach는 “state representation → frame graph → update operator → DBA → full SLAM system” 순서로 보면 된다.
| 구성 | 핵심 역할 | 논문에서 중요한 이유 |
|---|---|---|
| State | 각 frame마다 camera pose와 inverse depth 유지 | depth를 모든 pixel 단위 변수로 직접 최적화 |
| Frame Graph | covisible frame edge로 correlation/BA 대상 정의 | long-range edge 추가 시 loop closure 가능 |
| Update Operator | correlation, flow, residual, context로 revision/confidence 예측 | pose/depth를 직접 찍지 않고 DBA가 풀 수 있는 correspondence target 생성 |
| DBA Layer | reprojection objective를 Gauss-Newton으로 풀어 pose/depth update 산출 | network 안에 기하학적 최적화가 들어가는 핵심 장치 |
| SLAM System | frontend local BA, backend global BA/loop closure, motion-only BA 구성 | 논문 모델을 실제 video stream에서 돌아가는 SLAM으로 완성 |
DROID-SLAM에서는 video를 입력으로 받아 카메라의 궤적 추정과 주변 환경의 3차원 지도를 만드는 것을 목표로 한다. 첫 번째로, monocular setting에 대해 설명하고, 후에 섹션 3.4에서 이를 stereo와 RGB-D 시스템에 어떻게 일반화시키는 지를 설명한다.
Representation
DROID-SLAM은 순차적인 이미지 집합 을 입력으로 받으며, 각 이미지 t는 camera pose
와 inverse depth(역깊이) 라는 2개의 상태 변수(state variables)를 보유한다.
camera pose의 집합 와 inverse depth의 집합 은 알려지지 않은(unknown) 상태 변수들이며, 이는 추론 단계에서 새로운 프레임들을 처리하면서 반복적으로 업데이트 된다.
(또한 앞으로 해당 논문에서 언급되는 depth는 inverse depth를 의미한다고 한다)
또한 프레임들간의 co-visibility를 표현하기 위해 frame graph (𝜈, 𝜀)를 도입하였으며, edge인 은 이미지 와 가 특징점을 공유하는 서로 겹치는 영역을 가진다는 것을 의미한다. Frame graph는 훈련과 추론시에 동적으로 구축되며, 각 pose나 inverse depth가 업데이트되면 frame graph를 업데이트 하기 위해 visibility를 다시 계산할 수 있다. 또한 만약 카메라가 이전에 매핑한 지역으로 돌아오면, frame graph에 long range connection을 추가하여 loop closure를 수행한다.
3.1 Feature Extraction and Correlation
특징들은 각 새로운 이미지로부터 추출되어 시스템에 추가된다. 해당 단계에서 핵심 요소들은 RAFT에서 가져온 것이다.
각 입력 이미지들은 특징 추출 신경망에 의해 처리되며, 해당 신경망은 6개의 residual block과 3개의 downsampling layer로 구성되어 있으며, 입력 이미지 해상도의 1/8에 해당하는 dense feature map을 생성한다. 또한 RAFT처럼 2개의 분리된 신경망(feature network, context network)을 이용하며, feature network는 correlation volume을 형성하는데에 사용되며, context feature는 업데이트 연산중에 신경망에 주입된다.
Frame graph에서 각 edge 에 대해, 와 의 모든 쌍의 feature vector들 간에 dot product를 취하여 4D correlation volume을 계산한다.
(위 수식은 4D correlation volume을 의미한다)
그리고 4-level correlation pyramid를 형성하기 위해 해당 4D correlation volume의 마지막 두 차원에 대해 average pooling을 적용한다.
위 수식은 반지름 r의 격자(grid)를 이용하여 correlation volume을 인덱싱(indexing)하는 lookup 연산자를 정의한 것이다.
lookup operator는 H×W 크기의 격자 좌표(grid of coordinate)를 입력으로 받아, bilinear interpolation(쌍선형 보간법)을 이용하여 correlation volume에서 값을 조회(retrieve)한다. 또한 operator는 pyramid의 각 correlation volume에 적용되어, 각 level별 결과를 이어붙임으로써 마지막 feature vector가 계산된다.
3.2 Update Operator
update operator는 pose/depth를 직접 출력하는 black box가 아니라, correlation과 residual을 보고 flow revision과 confidence를 만든다. 실제 pose-depth 갱신은 이어지는 DBA layer가 담당한다.
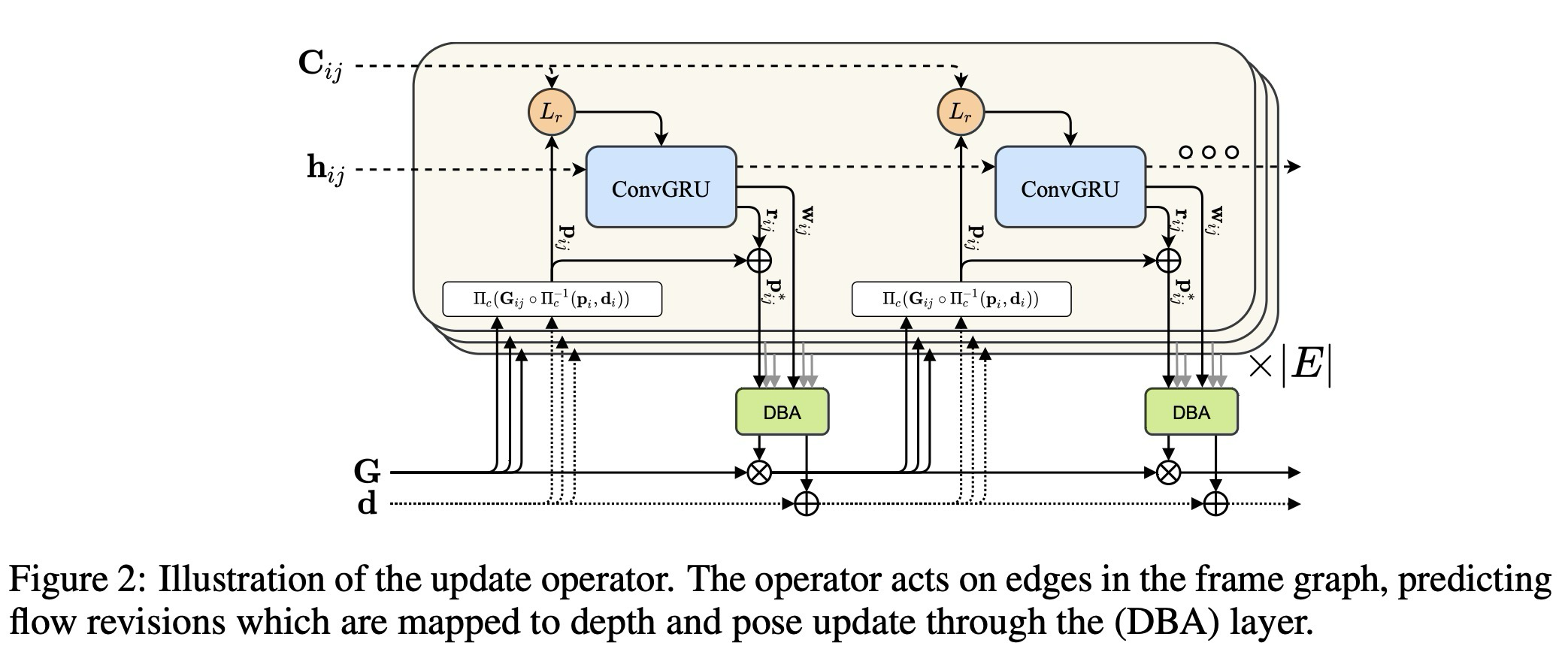
위 그림은 DROID-SLAM의 핵심 요소인 learned update operator를 보여준다. 해당 update operator는 hidden state(은닉 상태) h를 가지는 3x3 크기의 convolutional GRU이며, operator가 적용될때마다 hidden state를 업데이트하고 추가적으로 pose update() 및 depth update()를 수행한다.
이러한 pose 및 depth update는 SE3 manifold(다양체)에서의 retraction과 vector addition을 통해 현재 depth와 pose 추정에 사용된다.
update operator는 pose와 depth를 직접 완성하는 black box가 아니라, correlation과 flow/residual을 바탕으로 correspondence revision과 confidence를 반복 예측하고, DBA가 이를 pose-depth update로 바꾸도록 연결하는 모듈이다.
각 반복의 시작에서 correspondence를 추정하기 위해 pose와 depth의 현재 추정을 이용하는데, i번째 프레임의 픽셀 좌표 격자 가 주어지면, dense correspondence field 를 계산한다.
위 수식에서 는 3D point를 이미지로 mapping하는 camera model이며, 은 inverse depth map 와 coordinate grid 를 3D pointcloud로 mapping하는 inverse projection function이다.
따라서 는 추정된 pose와 depth를 이용하여 frame i의 픽셀 좌표 를 frame j로 mapping한 것을 나타낸다.
correlation volume에 인덱싱(index)하기 위해 correspondence field()를 사용하는데, 각 edge 에 대해 correlation volume 에서 correlation feature를 조회하기 위해 를 사용한다.
correspondence field를 사용하여 카메라 움직임(motion)에 의해 생기는 optical flow를 계산하는데, 이는 로 정의된다. 또한 이전 BA solution의 residual을 해당 flow field와 결합하여 신경망이 이전 iteration에서의 정보를 feedback을 사용할 수 있도록 한다.
correlation feature는 의 주변의 visual similarity(시각적 유사성)를 제공하여, 신경망이 시각적으로 유사한(visually similar) 이미지 영역을 정렬(align)하도록 학습할 수 있게 한다. 하지만 correspondence는 때때로 모호할 수 있는데, 이때 flow는 보완적인 정보를 제공하며, motion fields에서 연속성(smoothness)을 활용하여 신경망이 강건한 예측을 할 수 있게 돕는다.
correlation feature와 flow feature는 GRU에 입력되기 전에 2개의 convolution layer를 통과한다. 또한 context network에서 추출된 context feature를 element-wise addition 연산을 통해 GRU로 같이 입력한다.
ConvGRU는 작은 receptive field를 가지는 local operation이다. 이미지의 공간적 차원(spatial dimension)에 대한 정보를 가지는 hidden state의 평균을 구함으로써 global context를 추출하고, 해당 feature vector를 GRU의 추가적인 입력으로 사용한다. Global context는 SLAM에서 중요한데, 예를 들어 큰 규모의 움직이는 물체는 불완전한 correspondence로 인해 시스템에 성능 저하를 가져오며, network에서는 이를 인지하고 제거하는 것이 중요하다.
GRU는 업데이트된 hidden state ()를 내놓는데, 이때 depth나 pose의 업데이트를 직접 예측하는 것 대신, dense flow fields 공간에서의 업데이트를 예측한다. 또한 hidden state를 2개의 추가적인 convolution layer에 통과시켜 2개의 출력값을 만드는데, 하나는 revision flow field ()이고, 다른 하나는 associated confidence map ()이다.
revision 는 dense correspondence field()의 오차를 교정(correct)하기 위한 항(term)으로 신경망에 의해서 예측되며, 교정된 correspondence를 로 나타낼 수 있다.
이후에, hidden state에서 동일한 source view 를 공유하는 모든 features를 pooling하고, 각 픽셀별 damping factor 를 예측한다. 또한 damping factor 가 양수(positive)임을 보장하기 위해 softplus 연산자를 사용한다. 추가적으로 pooling된 features를 이용해 8x8 마스크를 예측하며, 이는 inverse depth 추정에 대한 결과를 upsampling하는 데 사용된다.
DBA는 flow revision의 집합을 pose와 픽셀별 depth update의 집합으로 매핑한다.
전체 frame graph에 대한 cost function을 정의하면 아래와 같다.
는 Mahalanobis distance를 의미하며, confidence weight 에 기반한 오차 항(error term)을 정의한다. 따라서 위 수식은 reprojected points( )가 update operator에 의해 예측되는 revised correspondence 에 가까워지도록(match) pose 과 depth 을 업데이트해야 한다는 것을 의미한다.
위 수식을 선형화(linearize)하기 위해 local parameterization을 사용하고 업데이트()를 위해 Gauss-Newton 알고리즘을 사용한다. 또한 수식에서 각 항은 단일(single) depth variable만 포함하고 있기 때문에 Hessian matrix가 diagonal structure(대각 행렬)이다. pose와 depth variable들을 분리하여 Schur complement(슈어 보상행렬)을 적용할 수 있고, 픽셀별 damping factor 가 대각행렬인 depth block 에 더해져 손쉽게 역행렬을 구할 수 있다는 점에서 효율적인 시스템을 제공한다.
DBA layer는 computation graph의 일부로 구현되어 있으며, 훈련중에 backpropagation이 수행된다.
3.3 Training
학습 섹션은 성능 수치보다 gauge freedom 제거와 supervision 설계가 핵심이다.
| 항목 | 설정 | 의미 |
|---|---|---|
| Gauge Freedom |
| monocular training의 선형 시스템 conditioning과 gradient 안정화 |
| Video Sampling |
| 너무 쉽거나 어려운 sequence를 피해서 recurrent update 학습 |
| Supervision |
| 최종 결과뿐 아니라 반복 과정 전체가 수렴하도록 유도 |
| Training Setup |
| 이후 모든 modality 결과가 단일 monocular-trained model에서 출발 |
DROID-SLAM의 시스템은 Pytorch로 구현되어 있으며, 모든 group elements의 tangent space에서 backpropagation을 수행하기 위해 LieTorch 확장자를 사용한다.
monocular setting에서 신경망은 오직 similarity transform만을 통해 카메라의 궤적을 보정(recover)할 수 있고, 이를 통한 하나의 방법이 similarity transform에 불변한(invariant) loss를 정의하는 것이다.
하지만 gauge-freedom은 훈련중에 여전히 존재하고 있으며, 선형(linear) 시스템의 조건형성(conditioning)과 기울기(graident)의 안정성에 안좋은 영향을 준다. 이는 각 훈련 시퀀스에서 첫 2개의 pose를 ground-truth pose로 고정시킴으로써 해결 가능한데, 첫 번째 pose를 고정하면 6-dof gauge freedom을 제거되고, 두 번째 pose를 고정하면 scale freedom이 제거된다.
각 훈련 예제는 7개의 프레임으로 구성된 비디오 시퀀스이며, 안정적인 훈련과 좋은 downstream performance를 위해 너무 쉽지도 않고 어렵지도 않은 샘플 비디오가 필요하다.
훈련 데이터셋은 비디오의 집합으로 이루어져 있고, 의 길이를 가지는 각 비디오 에 대해서 의 distance matrix를 계산하는데, 이는 각 프레임쌍들간에 average optical flow magnitude를 저장한다. 그러나 모든 프레임들이 covisible 한 것은 아니기 때문에, 프레임쌍들간에 겹치는(overlap) 부분이 50% 미만이면, distance를 무한(infinity)로 설정한다. 또한 훈련중에 distance matrix에서 path들을 샘플링함으로써 동적으로 비디오를 생성하며, 인접 비디오 프레임들 사이의 평균 flow는 8px~96px 사이의 값을 가진다.
신경망을 지도할 때 pose loss와 flow loss를 섞어서 사용한다.
flow loss는 인접 프레임쌍들에 적용되는 loss이며, 예측된 depth와 pose로 얻어진 optical flow와, ground truth depth와 pose로 얻어진 flow 간의 average l2 distance를 적용하여 구해진다.
pose loss는 ground truth pose의 집합 와 예측된 pose의 집합 이 주어졌을 때
위와 같이 수식으로 나타낼 수 있다.
두 losses(flow loss + pose loss)는 매 iteration마다 기하급수적(exponentially)으로 증가하는 가중치 ()를 적용하여 출력값에 적용된다.
3.4 SLAM System
논문 모델이 실제 SLAM 시스템이 되는 구간이다. frontend는 최근 frame 안정화, backend는 전체 keyframe graph 정렬을 담당한다.
| 단계 | 요약 | 핵심 기준 |
|---|---|---|
| Initialization |
| 간단한 bootstrap으로 초기 frame graph 생성 |
| Frontend |
| 실시간 tracking과 keyframe 유지 담당 |
| Backend |
| loop closure와 장기 drift 감소 담당 |
| Motion-only BA | non-keyframe pose는 인접 keyframe과의 flow로 보완 | 평가는 keyframe이 아닌 full trajectory 기준 |
| Stereo / RGB-D |
| 재학습 없이 sensor constraint만 objective에 추가 |
추론 단계에서는 신경망을 full SLAM 시스템으로 구성하는데, 비디오 스트림 입력을 받아 reconstruction과 localization을 실시간으로 수행한다. 또한 제안하는 시스템은 비동기적(asynchronously)으로 동작하는 2개의 스레드(thread)를 포함하며, 하나는 frontend thread로, 새로운 프레임을 입력받아 특징을 추출하고 keyframe을 골라 local BA를 수행한다. 나머지 하나는 backend thread로, 모든 keyframe의 history를 기반으로 동시에 global BA를 수행한다.
DROID-SLAM은 간단한 초기화를 제안한다.
프레임이 12개가 될 때까지 프레임을 계속 축적하고, optical flow가 16px 이상인 이전 프레임에 대해서만 유지한다(여기서 optical flow는 한 번의 update iteration을 통해 추정된다). 12개의 프레임이 축적되면, keyframe(프레임)간의 edge를 형성하여 frame graph를 초기화하고, 이때 특정 keyframe 기준 edge를 형성할 keyframe은 3 timestep 내에 있어야 한다. 초기화가 끝나면 update operator를 10번 iteration 돌린다.
frontend는 비디오 스트림을 직접적으로 처리하며, keyframe 집합과 covisible keyframe간의 edge를 저장하는 frame graph를 가지고 있다. 또한 keyframe의 pose와 depth는 계속해서(actively) 최적화된다.
먼저 받아오는 프레임에서 특징을 추출하고, 해당 keyframe(프레임)을 기준으로 mean optical flow 기반의 3개의 closest neighbor를 찾아 frame graph에 추가해 edge를 연결한다.
pose는 linear motion model을 통해 초기화되며, 그 후에 keyframe의 pose와 depth를 업데이트하기 위해 update operator에 몇 번의 iteration을 적용한다. 여기서 첫 2개의 pose를 고정(fix)하여 guage freedom을 제거하며, depth는 free variable로 처리한다.
새로운 프레임이 추적된 후에 지울 keyframe을 선택하는데, 프레임쌍들간의 average optical flow magnitude를 계산함으로써 거리를 계산하고 중복 프레임을 제거하며, 만약 지울만한 후보가 없으면 가장 오래된 keyframe을 제거한다.
backend는 모든 keyframe의 history를 기반으로 동시에 global BA를 수행한다.
Backend implementation 세부 보기
global BA가 실제 비디오 길이에서 동작하도록 만드는 frame graph, memory, solver 구현을 접어둔 구간이다.
flow distance로 edge를 다시 고르고 loop closure 후보를 구성.
전체 correlation volume 대신 RAFT식 memory-efficient lookup 사용.
test-time에는 custom CUDA와 sparse Cholesky로 block-sparse BA를 처리.
각 반복(iteration)마다 키프레임 쌍들간의 flow를 기반으로 frame graph를 재건축(rebuild)하며, 해당 flow는 크기의 distance matrix로 표현된다. 먼저 시간적으로(temporally) 인접한 keyframe들간의 edge를 추가하고, flow값에 대해 오름차순으로 정렬된 distance matrix에서 새로운 edge들을 샘플링한다. 각 선택된 edge에 대해 distance가 2 이내인 이웃하는 edge들을 suppress하며, 여기서 distance는 인덱스 쌍 간의Chebyshev distance를 의미하며 의 수식으로 나타낸다.
이후에, 수천 frame 및 edge로 구성된 전체 frame graph에 update를 적용하는데, 여기서 correlation volume의 전체 집합을 저장하면 빠르게 비디오 메모리를 초과하기 때문에, 대신 RAFT에서 제안한 메모리 효율적인 방법을 사용한다.
훈련 단계에서는 자동 미분 엔진(automatic differentiation engine)을 사용하기 위해 dense bundle adjustment를 PyTorch로 구현하였고, 추론 단계에서는 custom CUDA kernel을 사용하여 block-sparse 구조의 이점을 챙겼고, reduced camera block에 sparse Cholesky 분해를 수행한다.
full BA는 keyframe 이미지에 대해서만 적용하며, non-keyframe들의 pose를 보완하기 위해, keyframe들과 해당 keyframe이 이웃하는 non-keyframe들간의 flow를 반복적으로 추정함으로써 motion-only BA를 수행한다.
테스트 단계에서는 일부 keyframe만 이용하는게 아닌, full camera trajectory로 평가한다.
본 시스템은 stereo나 RGB-D 비디오에도 쉽게 적용될 수 있다.
RGB-D의 경우, 센서 depth의 노이즈나 관측 오류 때문에 여전히 depth를 변수로써 다루고, 간단하게 최적화 단계에서 측정된 depth와 예측된 depth 사이의 squared distance로 페널티를 주는 항을 추가한다.
stereo의 경우, monocular 시스템에서 언급했던 것과 동일한 시스템을 사용하며, 프레임이 2배가 되고, DBA layer에서 좌우 프레임간의 상대 pose를 고정한다. 또한 frame graph에서 cross camera edges(좌우 프레임간 edges)를 통해 stereo 정보를 활용할 수 있다.
Evidence: 어떤 sensor와 SLAM 조건에서 검증했나
본 연구에서는 다양한 데이터셋과 모달리티를 이용한 실험을 진행하였고, 딥러닝과 고전 기반의 SLAM 알고리즘에서 둘 다 비교하였으며, cross-dataset generalization에 대한 실험도 중요하게 다뤘다고 한다.
앞서 연구에서 주로 사용한 Average Trajectory Error(ATE)를 통해 카메라 궤적의 정확도를 평가하였으며, 3D reconstruction 결과에 대해서는 GT가 명확한 데이터셋 외에는 평가가 힘들고 Multiview Stereo의 domain으로 여겨지기 때문에 평가에서 제외했다고 한다.
신경망은 전부 synthetic TartanAir 데이터셋의 monocular video로 학습되었으며, 학습 설정은 아래 표처럼 정리할 수 있다.
synthetic TartanAir monocular video로만 학습한 설정이다. 이후 stereo/RGB-D 평가는 같은 모델이 테스트 시점의 추가 제약을 받아들일 수 있는지 확인하는 근거로 읽으면 된다.
| 항목 | 설정값 | 읽는 포인트 |
|---|---|---|
| Resolution | 384x512 | 입력 해상도 고정 |
| Batch Size | 4 | 짧은 video clip 단위 학습 |
| Training Iteration | 250k | synthetic trajectory에서 반복 최적화 학습 |
| Frame Clip Size | 7 frames | recurrent update가 보는 시간 창 |
| Update Iteration | 15 | 한 clip 안에서 pose-depth update 반복 |
| GPU | RTX-3090 x4 | 학습 비용이 큰 편 |
| Training Time | 1 week | 단일 모델 학습에 소요 |
평가 섹션은 dataset 이름보다, 각 dataset이 어떤 실패 모드를 시험하는지와 DROID가 그 실패를 어떻게 줄였는지 먼저 보면 흐름이 잡힌다.
synthetic hard sequence. monocular 0.129, stereo 0.047로 competition top methods 대비 62%/60% error 감소
새 카메라/환경 일반화. monocular 평균 ATE 2.2cm, ORB-SLAM3 성공 sequence 기준 43% error 감소
rolling shutter, motion blur, heavy rotation이 강한 실내 sequence. 9개 모두 tracking, 평균 ATE 0.038m
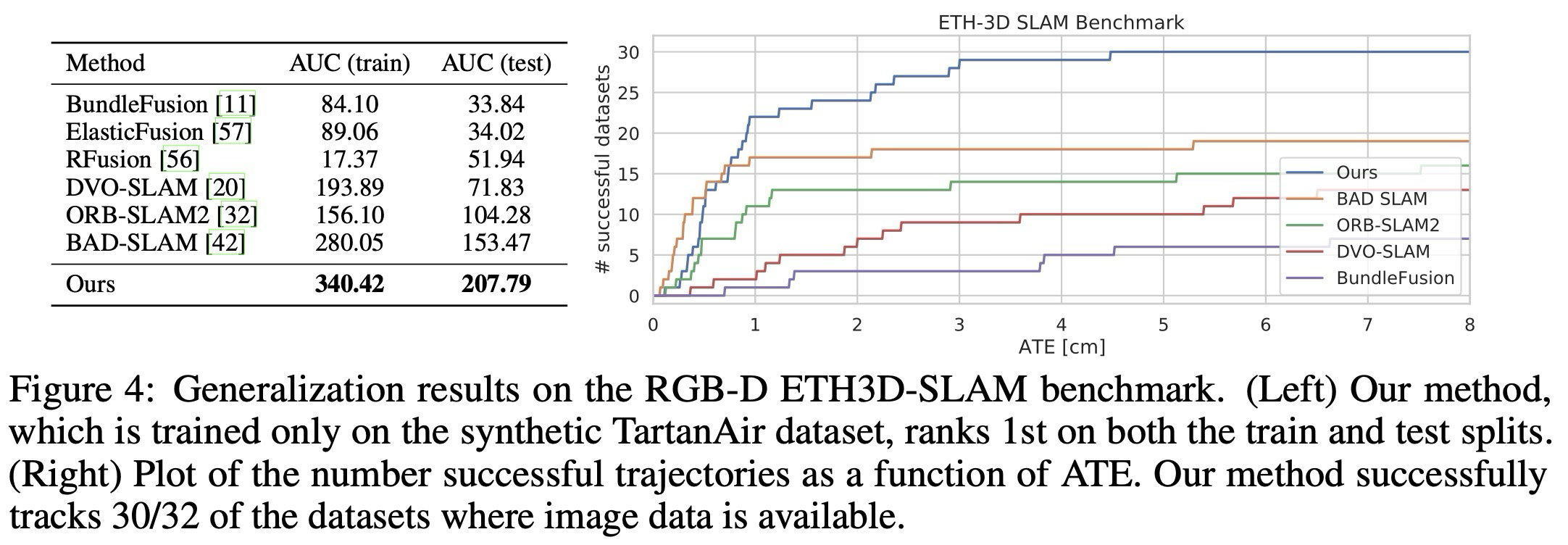
RGB-D generalization. train/test split 1위, image 사용 가능 test set 30/32 tracking 성공
synthetic hard benchmark에서 DROID-SLAM이 정확도와 failure robustness를 동시에 가져가는지 확인하는 파트다.
- ECCV 2020 SLAM competition hard split
- monocular와 stereo track 모두 비교
- monocular 62%, stereo 60% error 감소
- TartanVO 대비 8배, DeepV2D 대비 20배 낮은 평균 오차
deep SLAM이 classical/offline system보다 느슨한 대체가 아니라, hard sequence에서도 drift와 failure를 같이 줄이는지 보는 표.
상위 COLMAP 기반 submission은 더 느린 offline 성격이므로 속도 비교까지 함께 봐야 함.
TartanAir 세부 결과 보기
TartanAir 데이터셋은 SLAM 알고리즘을 평가하기 위한 어려운(challenging) synthetic 벤치마크이며, ECCV 2020 SLAM competition에서 이용되었다고 한다. 공식 test split을 사용하였고, 모든 “Hard” 시퀀스에 대한 결과가 아래 표에 나와있다.
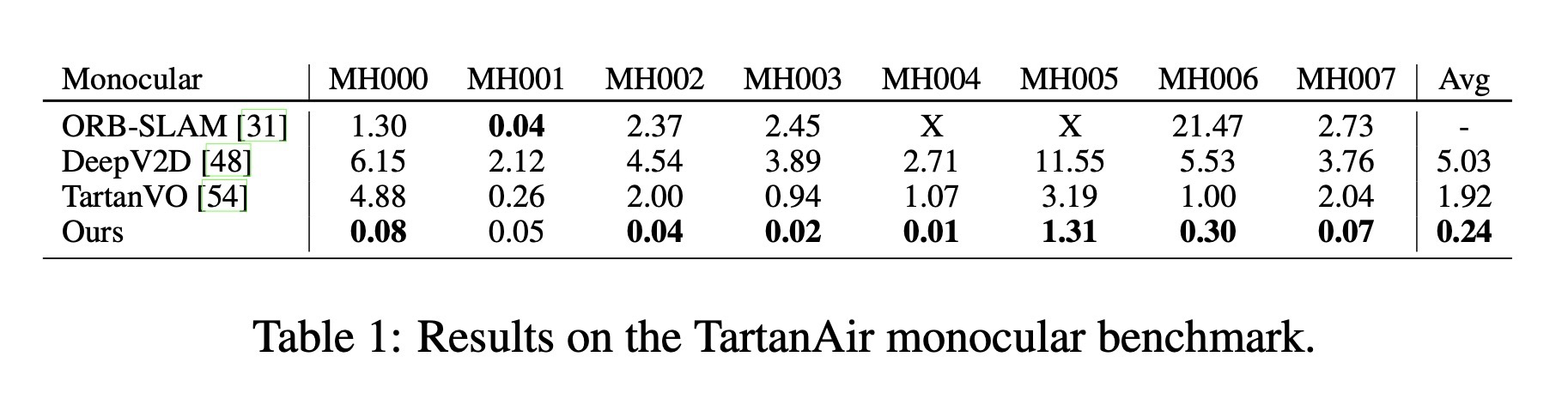
표를 보면 DROID-SLAM은 강건성(catastrophic failure가 없음)과 정확성(매우 낮은 drift)을 둘 다 보여주고 있다. baseline으로 DeepV2D를 TartaAir에 재학습(retrain)시킨 모델을 선정하였는데, 대부분의 시퀀스들에 대해 DROID-SLAM이 기존 방법론들 대비 한 자리수의 성능 차이를 보이며 능가하였고, TartanVO 모델 대비 8배, DeepV2D 대비 20배 적은 평균 오차를 달성했다.
또한 아래는 ECCV 2020 SLAM competition에서 1~3위를 차지한 모델들과의 비교 결과를 보여준다.

1~2위의 모델들은 모두 COLMAP을 사용하며, 이는 실시간(real-time) 시스템 대비 40배 느리다. 하지만 DROID-SLAM은 해당 시스템들 대비 16배 빠르며, monocular 벤치마크에서는 62% 낮은 오차율을, stereo 벤치마크에서는 60% 낮은 오차율을 달성했다.
synthetic monocular 학습 모델이 실제 MAV 카메라와 새로운 환경으로 얼마나 일반화되는지 보는 구간이다.
- EuRoC MAV sequence
- monocular와 stereo setting 모두 평가
- monocular 평균 ATE 2.2cm
- zero failure 방법 중 82% error 감소
- stereo input에서 ORB-SLAM3 대비 71% error 감소
DROID의 일반화 주장은 dataset 외삽뿐 아니라 sensor constraint를 test-time objective에 넣을 수 있다는 구조와 연결됨.
D3VO 비교는 train/test scene overlap과 평가 sequence 사용 방식까지 함께 확인해야 함.
EuRoC 세부 결과 보기
실험을 진행하면서 DROID-SLAM의 새로운 카메라 및 환경에 대한 일반화 능력에 흥미가 생겼다고 한다.
EuRoC 데이터셋은 Micro Aerial Vehicle(MAV)가 찍은 비디오로 구성되어 있으며, SLAM 시스템 벤치마크에 두루두루 쓰인다. 아래 표는 EuRoC 데이터셋의 monocular input에 대한 평가 결과를 보여준다.
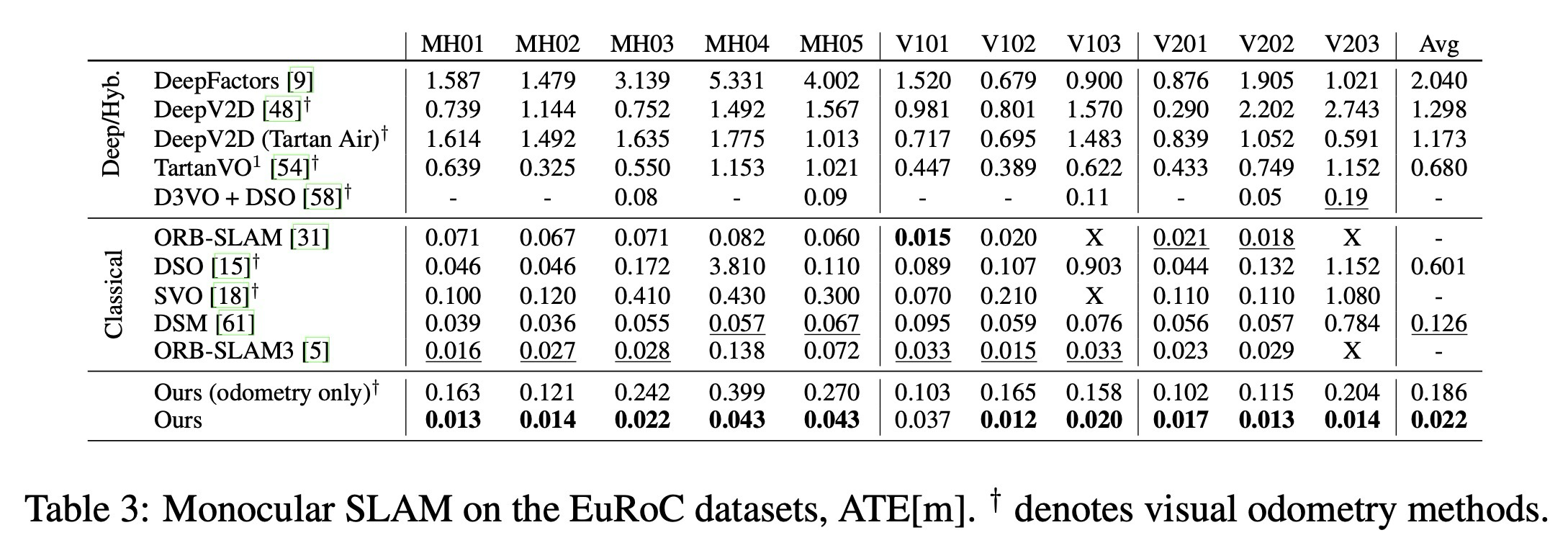
위 표를 보면, DROID-SLAM은 모든 시퀀스들에 대해 평균적으로 2.2cm의 오차를 보였으며, 다른 방법론들 대비 82%의 오차 감소율을 보였고, 실패가 없었으며, ORB-SLAM3의 결과(평가 성공) 대비 43%의 오차 감소율을 보여주었다. 또한 몇몇 딥러닝 기반 방법론들과 비교를 진행했으며, TartanAir 데이터셋으로 학습시킨 DeepV2D와 ScanNet으로 학습시킨 NYUv2와 DeepFactors가 있다. 하지만 이러한 최근 딥러닝 방법론들은 고전 SLAM 시스템들 대비 EuRoC 데이터셋에서의 평가 결과가 좋지 않았고, 이는 모델의 부족한 일반화 성능과 데이터셋 편향으로 인해 발생한 큰 drift 때문이며, DROID-SLAM은 이러한 문제에 강건했다고 볼 수 있다.
반면에 D3VO는 neural network로 구성된 frontend와 DSO로 구성된 backend를 결합한 구조를 통해 강건성과 정확성 둘 다 챙길 수 있었는데, 11개의 시퀀스들 중 6개의 시퀀스들을 평가하는데 사용하고, 나머지 5개는 비지도 학습을 하는데에 사용하였으며, 학습 시퀀스는 평가 시퀀스와 동일한 scene을 포함한다.
rolling shutter, motion blur, heavy rotation이 있는 실내 sequence에서 catastrophic failure를 줄이는지 보는 파트다.
- handheld RGB-D indoor sequence
- 대부분 monocular input 기준 비교
- 9개 sequence 모두 tracking 성공
- DeepFactors 대비 83%, DeepV2D 대비 90% 낮은 ATE
정확도 평균보다 먼저 failure 없이 끝까지 추적했는지 확인.
network correspondence와 DBA가 motion blur/rotation 조건에서 front-end 실패를 줄이는지 보여줌.
TUM-RGBD 세부 결과 보기
TUM-RGBD는 handheld camera로 찍은 실내 scene으로 이루어진 RGB-D 데이터셋으로, monocular 시스템에서는 rolling shutter artifacts, motion blur, heavy rotation으로 인해, 악명높게 어려운 데이터셋으로 알려져 있다.
본 연구에서는 이전 연구에서 freiburg 1에 대해서만 수행한 결과만 벤치마크 하였으며, 결과는 아래와 같다.
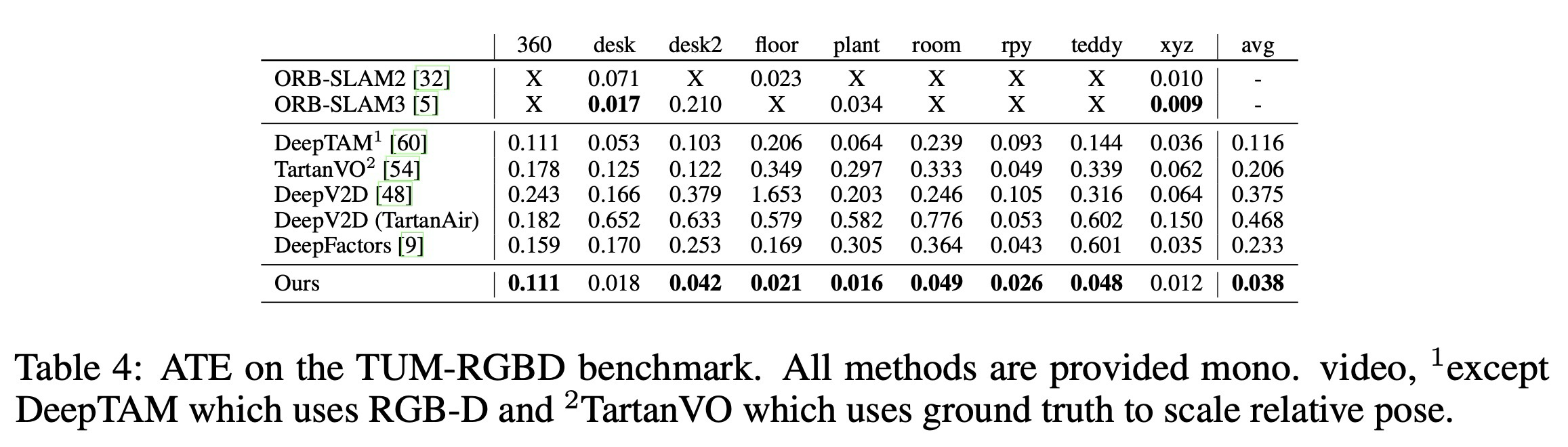
ORB-SLAM과 같은 고전 SLAM 알고리즘들은 대부분의 시퀀스에서 실패하였고, 딥러닝 방법론들은 고전 기법들보다는 강건했지만 대부분의 평가된 시퀀스에서 낮은 정확도를 보였다. 하지만 DROID-SLAM은 강건하고 정확한 모습을 보였고, 모든 9개의 시퀀스를 성공적으로 추적하며, 모든 시퀀스에 대해 성공한 DeepFactors와 DeepV2D보다 각각 83%, 90% 낮은 ATE를 보였다.
RGB-D sensor measurement를 optimization objective에 추가했을 때, monocular-trained model이 얼마나 잘 적응하는지 확인하는 구간이다.
- ETH3D RGB-D benchmark
- TartanAir 학습 모델에 depth penalty 항 추가
- train/test split 모두 1위
- test set 32개 중 30개 tracking 성공
이전 최고 19/32 성공 대비 failure robustness가 크게 개선됨.
RGB-D depth도 고정 진리가 아니라 noisy/missing measurement라서 optimization constraint로 다룸.
ETH3D-SLAM 세부 결과 보기
마지막으로 ETH3D-SLAM 벤치마크에서 RGB-D 시스템의 성능을 평가하였다. 신경망은 TartanAir에서 제공하는 RGB-D 카메라 측정값으로 훈련되며, 최적화 단계에서 예측된 inverse depth와 센서로 측정된 inverse depth 사이의 distance를 페널티로 주는 항을 추가한다.
DROID-SLAM은 finetuning 없이 train과 test split에 대해 1등(1st rank)을 달성하였고, 사용 불가능한 이미지가 포함된 몇몇 데이터셋들은 평가에서 제외하였다. test set에서는 32개의 RGB-D 시퀀스 중 30개의 시퀀스를 추적 성공하여, 이전 최고 기록(32개의 RGB-D 시퀀스 중 19개의 시퀀스에서 성공) 대비 향상된 결과를 보여주었다.
성능 개선의 반대편에서 DROID-SLAM이 어떤 compute/memory cost를 요구하는지 확인하는 파트다.
- RTX 3090 2개 사용
- frontend local BA와 backend global BA를 분리 운용
- EuRoC 평균 20fps
- TUM-RGBD 평균 30fps
- TartanAir는 빠른 camera motion으로 평균 8fps
backend가 전체 image feature map을 저장하므로 long sequence에서 메모리 요구량 증가.
정확도와 robustness는 강하지만, classical SLAM 대비 resource cost가 중요한 trade-off.
Timing / Memory 세부 조건 보기
DROID-SLAM은 3090 GPU 2개로 실시간 운용 가능하며, 첫 번째 GPU에서는 tracking과 local BA를, 두 번째 GPU에서는 global BA와 loop closure를 수행한다.
EuRoC 데이터셋은 320x512 해상도로 downsampling하고 나머지 프레임들을 skip하여 평균 20fps로 사용했는데, 위에서 봤던 Table 3이 해당 setting으로 얻은 결과이다.
또한 TUM-RGBD 데이터셋은 240x320 해상도로 downsampling하고 나머지 프레임들을 skip하여 평균 30fps로 사용했는데, 마찬가지로 위에서 봤던 Table 4가 해당 setting으로 얻은 결과이다.
TartanAir 데이터셋은 훨씬 빠른 카메라 움직임으로 인해 실시간 운용이 불가능했으며, 평균 8fps로 사용했다. 하지만 여전히 TartanAir SLAM challenge에서 1, 2등을 차지한 COLMAP 기반 방법론들 대비 16배 빠른 결과를 보여주었다.
DROID-SLAM의 frontend는 8GB의 GPU 메모리로 운용할 수 있지만, backend는 모든 이미지에 대한 feature map을 저장해야 하기 때문에 더 많은 메모리를 요구한다. TUM-RGBD 데이터셋의 모든 평가 결과는 단일 1080Ti GPU로 얻을 수 있고, EuRoC, TartanAir, ETH-3D(video 시퀀스 하나가 5000 프레임까지 구성될 수 있는) 데이터셋의 평가 결과는 24GB의 메모리를 가진 GPU를 필요로 한다.
DROID-SLAM의 현재 가장 큰 한계는 메모리와 리소스에 대한 요구사항(requirements)이며, 이는 중복 연산 제거(culling) 및 더 효율적인 표현(representation) 방법으로 극적으로 감소시킬 수 있다.
- Accuracy: 단순 평균 오차뿐 아니라 failure가 포함된 결과인지 확인
- Robustness: catastrophic failure가 줄었는지가 DROID-SLAM의 핵심 주장
- Resource: backend가 feature map을 저장하므로 긴 sequence에서는 memory가 병목
Usage / Limits: 어떤 SLAM 기준선으로 남았나
본 연구에서는 visual SLAM을 위한 end-to-end 신경망 구조인 DROID-SLAM을 소개하며, 이는 정확하고 강건하고 다재다능하며, monocular, stereo, RGB-D video에 대해 운용될 수 있고, 이전 연구들 대비 어려운 벤치마크에서 큰 차이(margin)를 보여주며 능가하는 성능을 보였다.
느낀점
SLAM의 백엔드 최적화를 DBA라는 미분 가능한 레이어로 통합하여, 반복적으로 pose와 depth를 업데이트하며 frame graph를 재구성하는 방식이 인상적이었다. 또한 monocular 학습만으로도 stereo나 RGB-D 입력에서 성능이 향상되는 일반화 능력이 눈에 띄었고, 처음 두 개의 pose를 고정하여 gauge freedom을 제거하고 학습을 안정화한 점도 이해에 큰 도움이 되었다.
Comments