핵심 요약
MapAnything은 image와 optional geometric input을 함께 받아 metric 3D geometry와 camera를 한 번에 예측하는 universal feed-forward 3D reconstruction model이다.
논문의 핵심은 multi-view geometry를 ray, ray depth, pose, global metric scale로 분해해, 어떤 geometric 정보가 주어져도 같은 모델 안에서 활용하게 만드는 것이다.
Flexible Inputs
image에 ray, pose, depth, partial reconstruction을 선택적으로 결합.
Factored Outputs
하나의 coupled pointmap 대신 local ray, ray depth, pose, metric scale을 분리 예측.
Universal Training
label이 있는 factor에만 loss를 적용해 partial supervision dataset을 함께 학습.
Broad Evaluation
SfM, MVS, calibration, metric depth, depth completion 계열을 함께 평가.
MapAnything이 중요한 이유는 단순히 multi-view network를 키운 것이 아니라, 입력으로 무엇이 주어질 수 있는가를 representation 설계 안에 넣었다는 점이다.
task-specific module
SfM, calibration, BA, MVS, depth가 여러 단계의 별도 문제로 나뉨.
image-first feed-forward 3D
강한 feed-forward prior를 쓰지만 geometric input과 metric scale을 항상 자연스럽게 다루지는 않음.
geometry-aware unified model
factored scene representation으로 image, ray, pose, depth를 유연하게 섞음.
논문 상세 정리
아래부터는 기존 논문 내용을 최대한 담은 상세 해석이다. 핵심 흐름에서 벗어나는 배경지식, notation, 부가 자료는 접어두었다.
Problem: task별 3D reconstruction을 하나의 모델로 묶을 수 있나
MapAnything의 문제의식은 image-based 3D reconstruction이 여전히 task별 pipeline에 많이 나뉘어 있다는 데서 출발한다. SfM, calibration, pose averaging, BA, MVS, monocular depth는 서로 연결되어 있지만, 실제 시스템에서는 대개 별도 module로 풀린다.
논문은 이 분리를 줄이기 위해 image-only setting뿐 아니라 calibration, pose, depth, partial reconstruction이 주어지는 상황까지 하나의 feed-forward 모델에서 다루려고 한다.
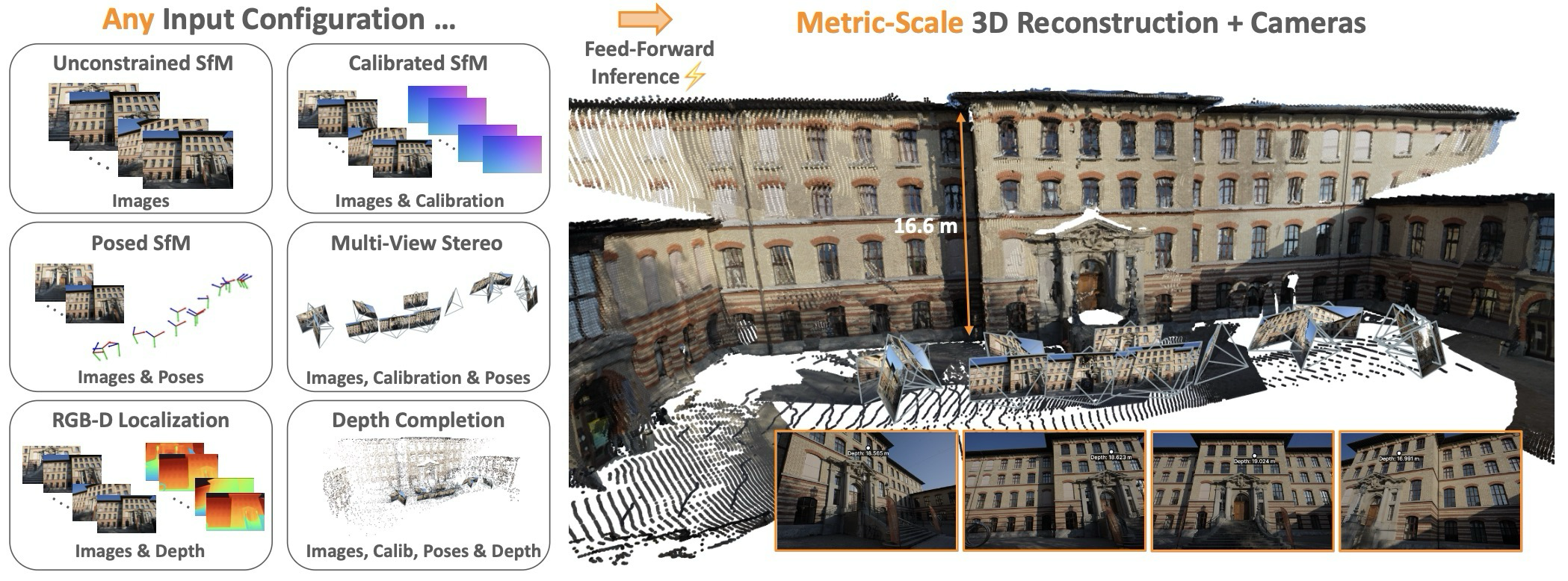
핵심 질문은 “image만 있을 때”가 아니라, 현장에서 geometry hint가 일부만 있을 때도 같은 모델이 활용할 수 있는가이다.
SfM, MVS, calibration, depth completion이 각각 다른 pipeline으로 구현됨.
기존 feed-forward 모델은 view 수, modality, camera model이 제한되는 경우가 많음.
dataset마다 depth, pose, metric scale, calibration annotation이 다르게 존재함.
geometry를 factor로 나누어 input과 output 양쪽에서 같은 구조로 다룸.
이 논문의 문제 제기는 task별 model을 여러 개 만드는 대신, 하나의 representation이 여러 입력 조건을 받아들이게 만들 수 있는가에 있다.
| 기존 제약 | MapAnything의 선택 | 의미 |
|---|---|---|
| Fixed modality | image + optional rays/pose/depth | 센서나 metadata availability 변화에 대응 |
| Coupled geometry | ray, depth, pose, scale로 factorization | prediction과 conditioning을 같은 언어로 정리 |
| Dataset mismatch | label이 있는 factor별 supervision | metric dataset과 up-to-scale dataset을 함께 활용 |
Related Work 흐름 자세히 보기
Related Work는 MapAnything이 “더 큰 VGGT”가 아니라, heterogeneous geometric input을 직접 다루는 범용 3D backbone을 목표로 한다는 위치를 잡아준다.
DeMoN, DeepTAM, DeepV2D부터 DUSt3R, VGGSfM, VGGT까지 이어지는 unified 3D 흐름.
DUSt3R/MASt3R는 pointmap coupling과 post-processing이 필요하고, VGGT/FASt3R도 redundant output 문제가 남음.
ray, origin, depth map은 여러 task에서 conditioning input으로 쓰였지만 universal 3D reconstruction의 중심 input은 아니었음.
Pow3R는 known prior를 쓰지만 two-view pinhole camera와 centered principal point, non-metric scale에 묶임.
Mechanism: geometry를 factor로 나누어 어떻게 예측하나
방법론의 핵심은 scene을 pointmap 하나로 바로 예측하지 않고, local ray direction, up-to-scale ray depth, camera pose, global metric scale로 나눈 뒤 다시 metric 3D로 조합한다는 점이다. 이렇게 하면 input으로 들어오는 geometry와 output으로 예측하는 geometry가 같은 구조를 공유한다.
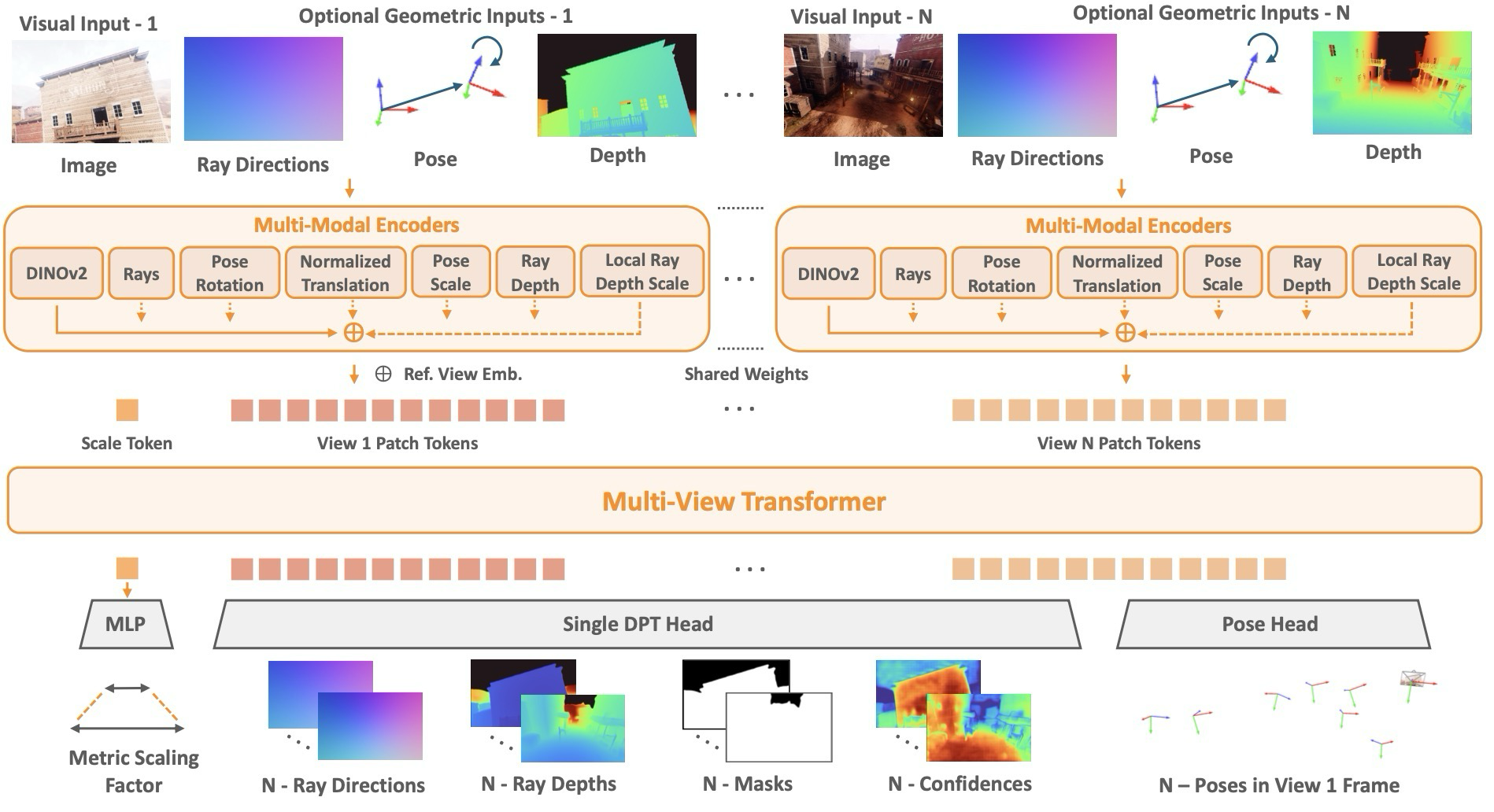
MapAnything은 “주어진 geometry를 보조 정보로 쓰는 모델”이라기보다, geometry factor를 입력과 출력의 공통 인터페이스로 쓰는 모델이다.
| 구간 | 무엇을 담당하나 | 핵심 장치 |
|---|---|---|
| Input factorization | intrinsics, pose, depth를 ray direction, quaternion/translation, ray depth로 정리 | generic central projection camera + metric/up-to-scale 분리 |
| Multi-modal encoding | image feature와 geometry feature를 같은 token space에 합침 | DINOv2 ViT-G, shallow conv encoder, MLP encoder |
| Transformer fusion | view 간 정보를 attention으로 교환 | 16-layer / 24-head alternating attention, reference view embedding, RoPE 미사용 |
| Factored decoding | ray/depth/mask/confidence, camera pose, scene scale을 따로 예측 | DPT head, pose head, scale token MLP |
MapAnything의 입력은 \(N\)개의 RGB image와 일부 view에만 존재할 수 있는 optional geometry다. output은 하나의 metric scale과 view별 factored geometry로 정리된다.
예측된 ray와 depth는 local pointmap이 되고, pose와 metric scale을 적용하면 global metric frame의 3D reconstruction이 된다.
translation과 depth는 scale에 묶이기 쉽다. 논문은 pose scale과 depth scale을 분리하고, metric scale value는 log-transform하여 large scene scale variation을 안정적으로 다룬다.
MapAnything은 하나의 pointmap을 바로 예측하지 않고, ray, depth, pose, metric scale을 분리한 뒤 다시 metric 3D로 조합한다. 따라서 각 factor가 어느 단계에서 쓰이는지 구분해 읽는 것이 중요하다.
| Notation | 의미 | 읽는 포인트 |
|---|---|---|
| \(\hat I\), \([\hat R,\hat Q,\hat T,\hat D]\) | RGB image와 optional geometry input | hat은 dataset에서 제공된 input/supervision factor를 의미. |
| \(m\) | predicted global metric scale | local/up-to-scale geometry를 metric 3D로 변환하는 핵심 scalar. |
| \(R_i\), \(\tilde D_i\), \(\tilde P_i\) | view \(i\)의 ray direction, up-to-scale ray depth, pose-like transform | factored output의 세 가지 주요 geometry factor. |
| \(\tilde L_i\), \(\tilde X_i\), \(X_i^{metric}\) | local ray-depth point, posed point, final metric point | ray-depth geometry가 pose와 scale을 거쳐 metric reconstruction이 됨. |
| \(O_i\), \(\tilde T_i\) | quaternion \(Q_i\)에서 얻은 rotation matrix와 translation component | local ray-depth point를 posed point로 올리는 transform 요소. |
| \(S_t\), \(\hat z_p\) | translation이 제공된 view 집합과 pose scale | pose translation이 있을 때 평균 거리로 scale 기준을 만든다. |
| \(\operatorname{sg}(\cdot)\), \(f_{\log}\) | stop-gradient와 log-space compression | scale loss가 geometry factor를 불안정하게 흔들지 않도록 분리. |
| \(C_i\), \(\mathcal L_{mask}\) | confidence/mask terms | ambiguous pixel과 invalid geometry 영역을 조절. |
Training loss와 dataset 구성 보기
모든 dataset이 모든 supervision을 갖고 있지는 않다. 그래서 논문은 label이 있는 factor에 맞춰 ray, rotation, translation, depth, pointmap, scale, normal, gradient matching, mask loss를 조합한다.
| Loss 계열 | 대상 | 역할 |
|---|---|---|
| Scale-independent | ray direction, quaternion rotation | scene scale과 무관하게 직접 regression |
| Scale-normalized | depth, translation, local/world pointmap | up-to-scale annotation과 metric annotation을 함께 사용 |
| Metric scale | global scale factor | geometry gradient를 오염시키지 않도록 stop-gradient 적용 |
| Detail / robustness | normal, gradient matching, mask | fine detail과 ambiguous region 처리 |
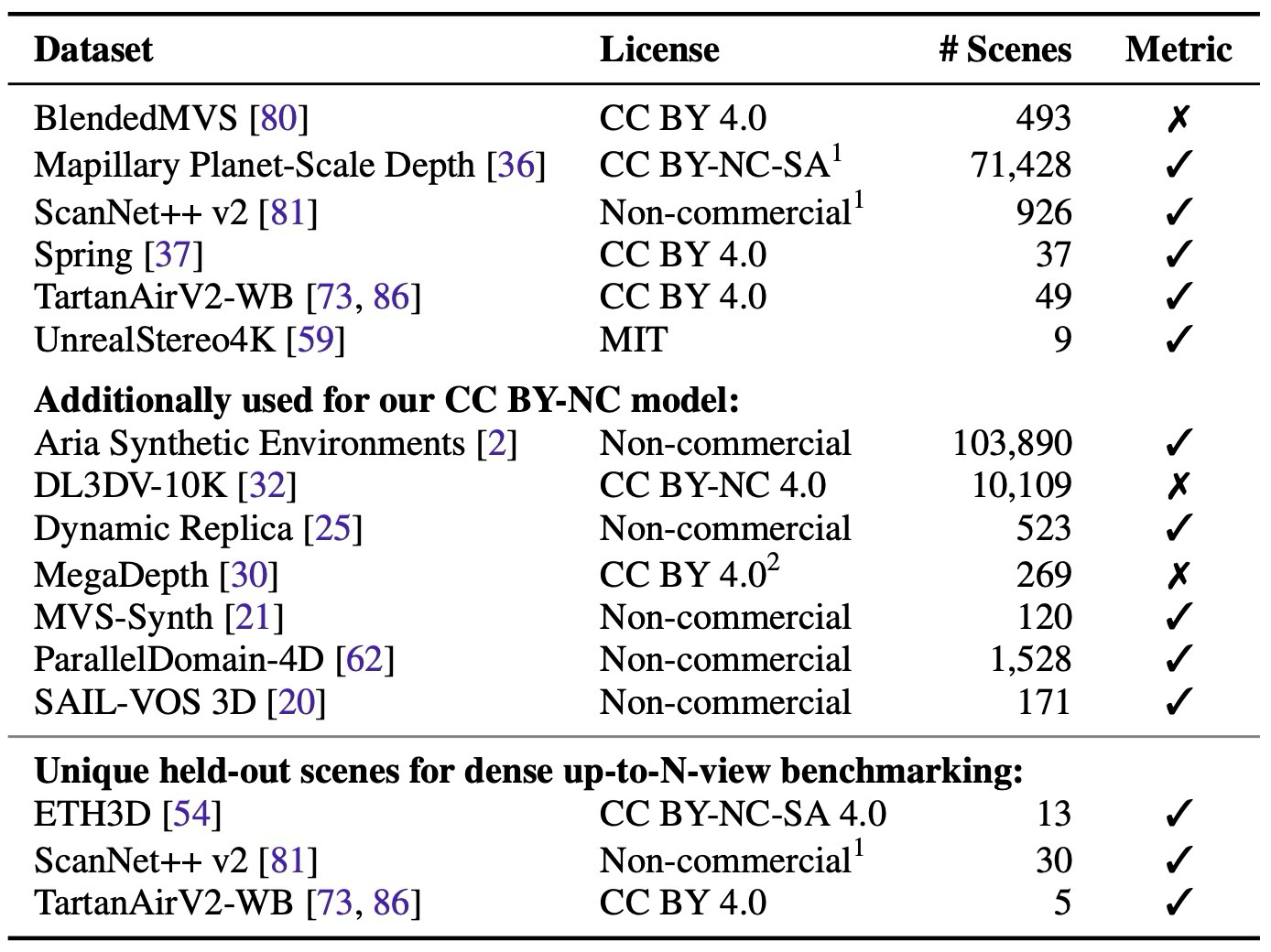
geometry input augmentation은 overall probability 0.9로 적용되고, ray direction, ray depth, pose는 각각 0.5 확률로 제공된다. depth input은 dense depth 또는 90% sparsified depth로 주어지며, per-view input probability 0.95로 일부 view에만 geometry가 있는 상황도 학습한다. normal loss와 gradient matching loss는 real geometry noise를 피하기 위해 synthetic dataset에만 적용된다.
indoor, outdoor, in-the-wild scene이 섞인 13개 dataset 사용.
ground-truth depth/pose 기반 pairwise covisibility를 계산하고 25% threshold random walk로 view graph sampling.
monocular metric depth dataset인 MPSD에 pose/camera 정보를 붙여 multi-view metric dataset으로 활용하고 metadata를 공개.
Apache 2.0 모델은 6개 dataset, non-commercial 모델은 추가 7개 dataset 포함.
Evidence: 어떤 조건에서 범용성이 검증되나
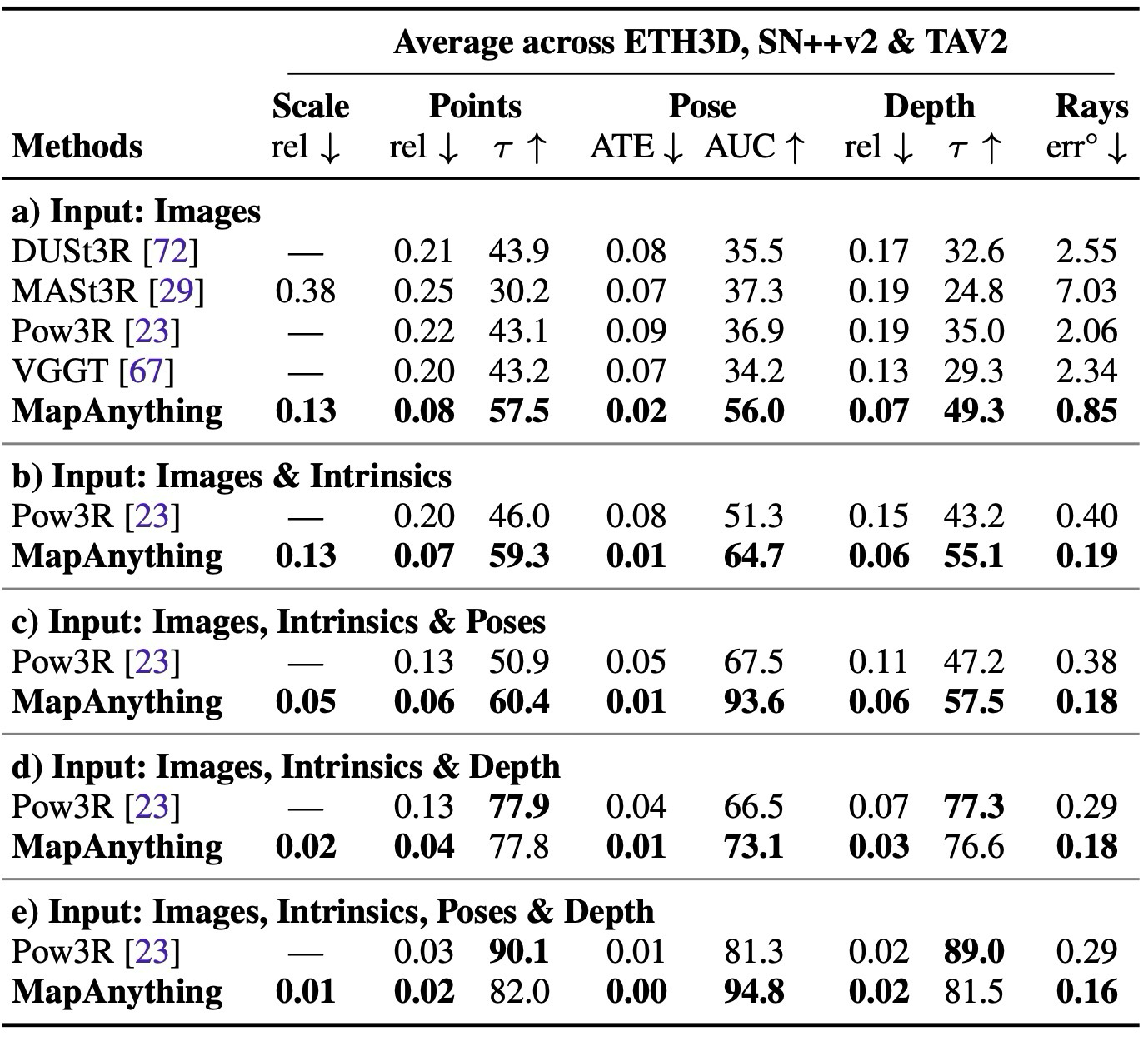
평가는 dataset 이름보다 task별 질문으로 읽는 편이 자연스럽다. MapAnything은 dense multi-view reconstruction, two-view reconstruction, single-image calibration, metric depth, ablation을 통해 image-only와 geometry-conditioned setting 모두를 검증한다.
결과의 핵심은 “여러 task를 하나의 모델로 한다”가 아니라, geometry input이 추가될수록 같은 모델이 이를 활용해 성능을 높인다는 점이다.
view 수 2부터 100까지, image-only와 geometry input 조건을 함께 확인.
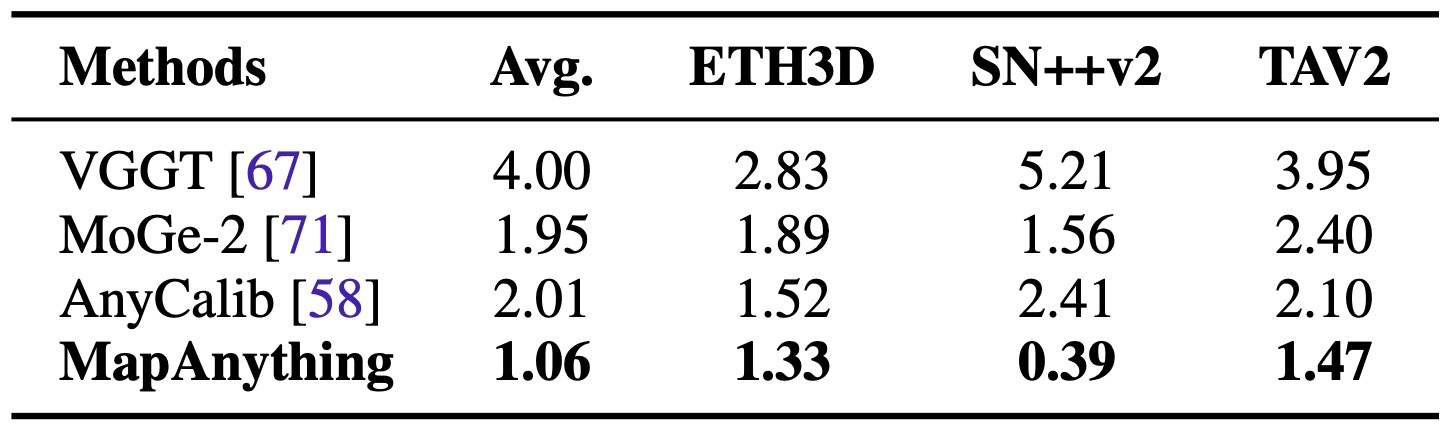
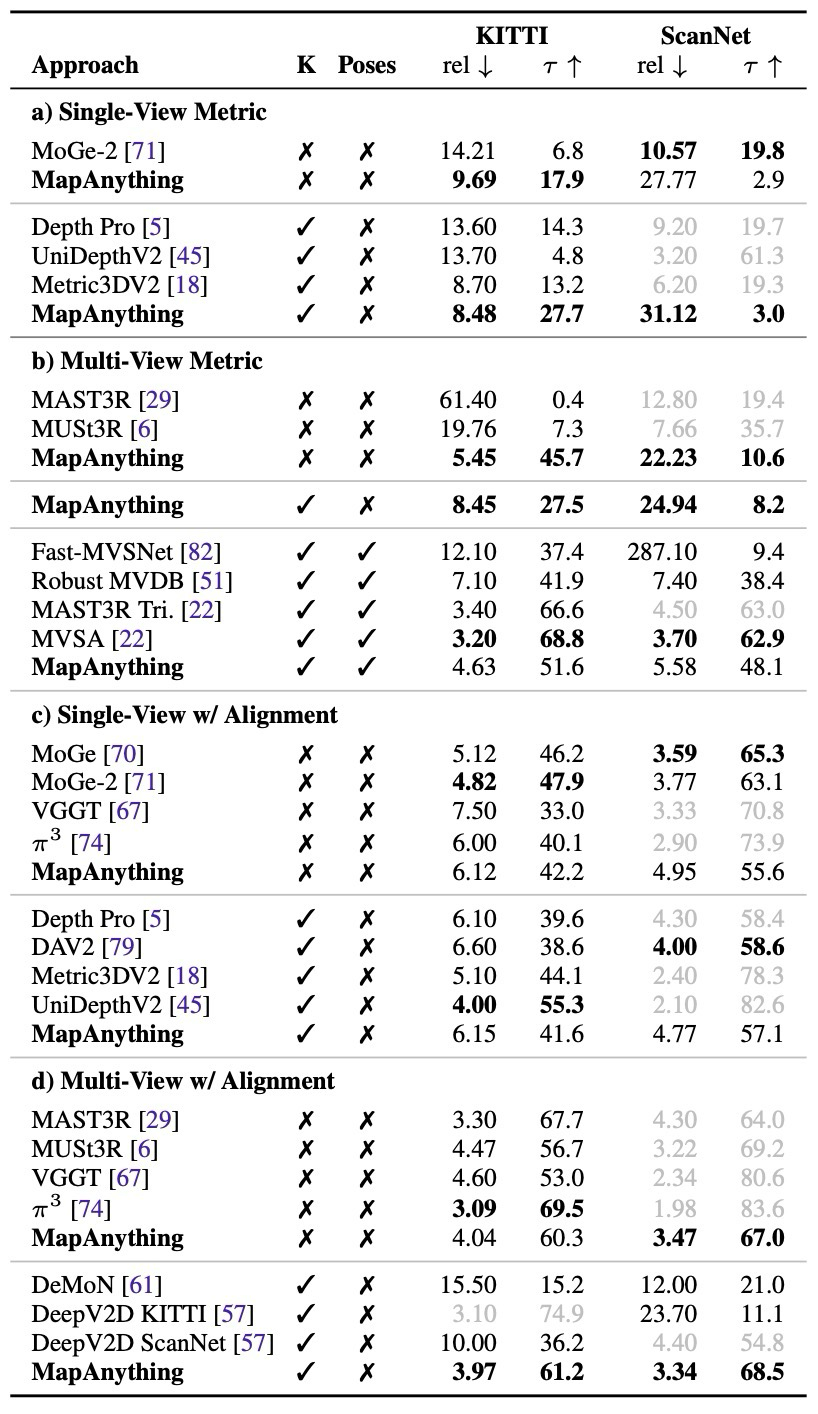
single-view calibration과 robust metric depth에서도 specialist와 비교.
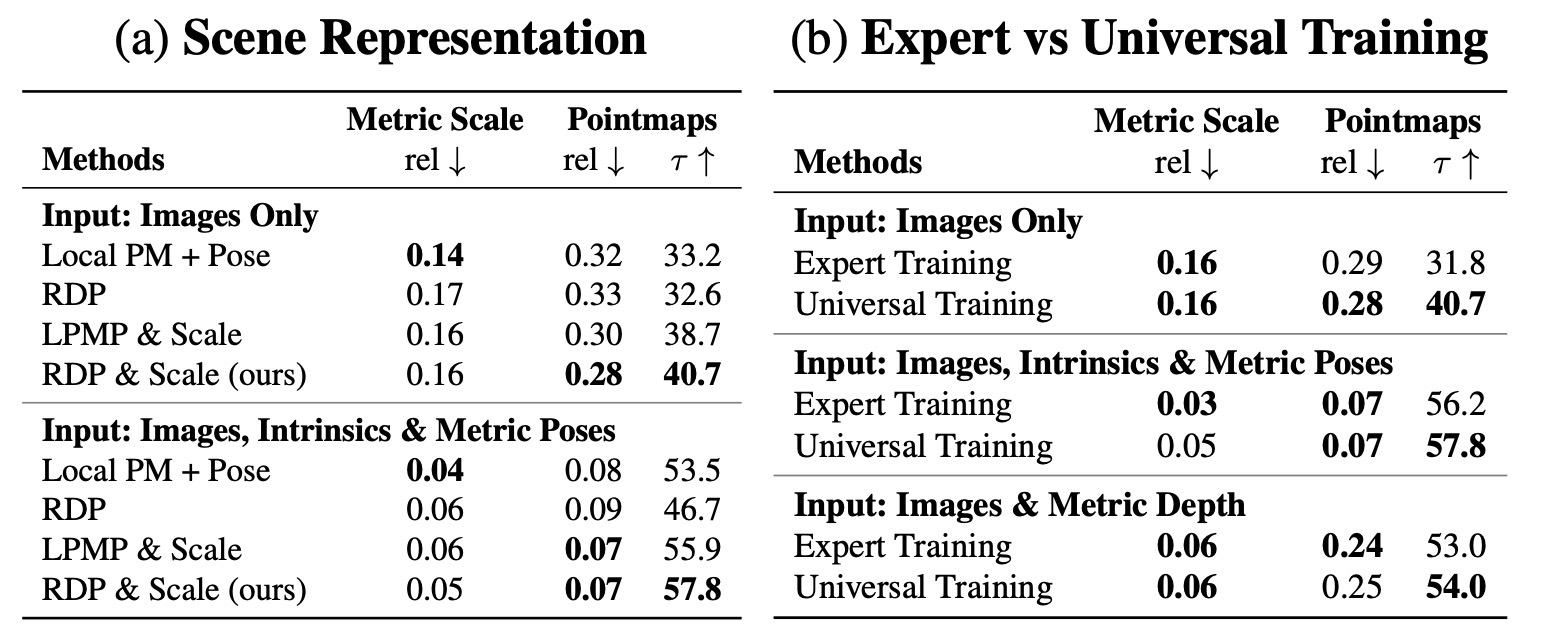
RDP & Scale representation과 universal training의 효과를 분리해 검증.

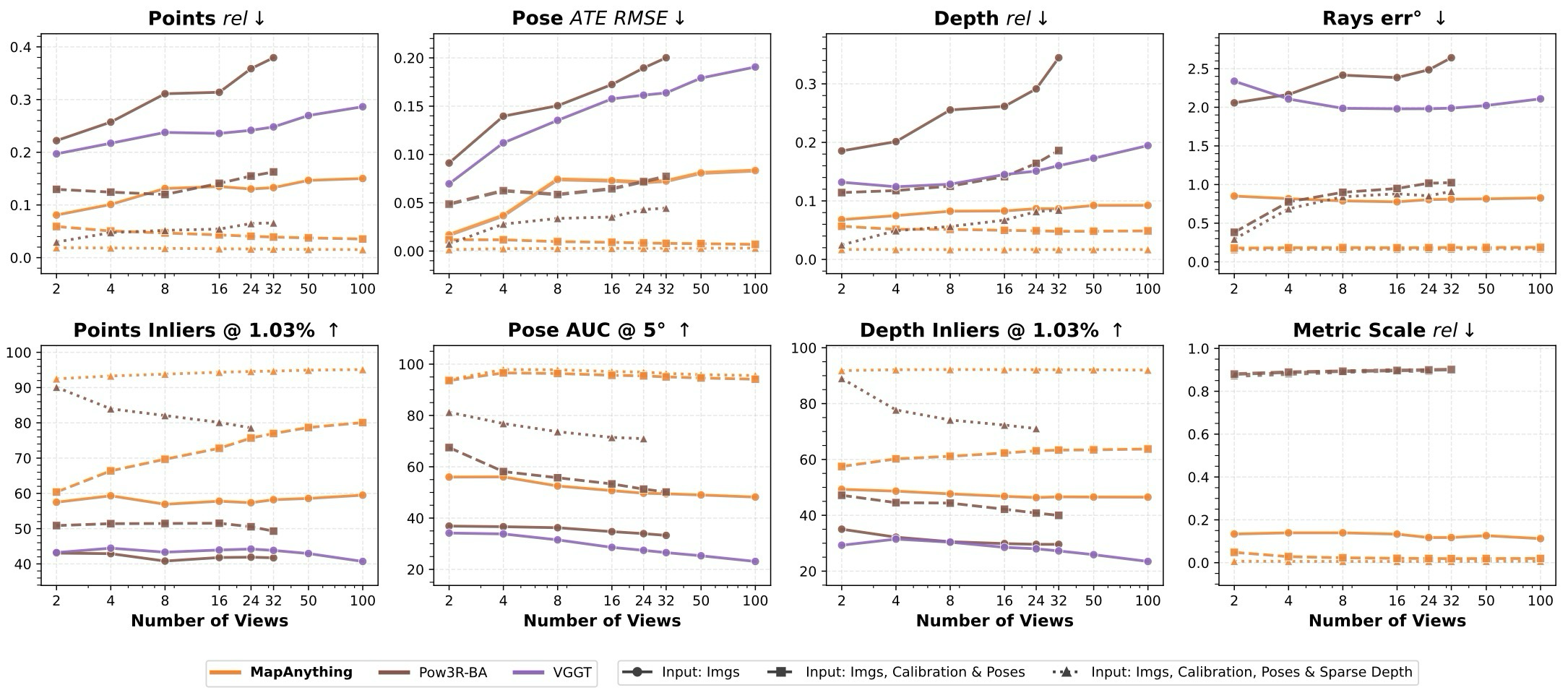
Calibration / depth / ablation 보조 결과 보기
이 세 결과는 MapAnything의 범용성을 보강하지만, 핵심 주장은 앞의 dense multi-view와 two-view reconstruction에서 먼저 확인된다.
single-image 전용 학습 없이 perspective calibration 성능 확인.
Robust-MVD에서 single-view와 multi-view metric depth 모두 확인.
RDP & Scale representation과 universal training의 필요성 검증.
Usage / Limits: 어떤 상황에 쓰기 좋은가
MapAnything은 입력 image와 함께 일부 geometry metadata가 있을 수도, 없을 수도 있는 환경에 잘 맞는다. 특히 robotics, mapping, dataset curation처럼 camera pose, calibration, depth가 부분적으로만 존재하는 경우, 하나의 모델로 여러 setting을 처리할 수 있다는 장점이 크다.
Limitations는 범용 backbone의 가능성과 아직 남은 공학적 제약을 함께 보여준다.
| 구분 | 요약 | 이유 |
|---|---|---|
| 좋은 사용처 | image와 calibration/pose/depth가 섞여 있는 multi-view reconstruction | optional geometry를 같은 representation으로 받아들임 |
| 좋은 사용처 | SfM, MVS, metric depth, calibration을 하나의 backbone으로 실험 | task-specific tuning 없이 넓은 task setting 지원 |
| 주의할 점 | geometric input의 noise나 uncertainty가 큰 경우 | 논문은 geometric input uncertainty를 명시적으로 모델링하지 않음 |
| 확장 가능성 | target view에는 camera만 있는 novel view synthesis식 task | 현재 지원하지는 않지만 architecture 확장 방향으로 언급됨 |
| 한계 | 매우 큰 scene, dynamic motion, scene flow | pixel-output one-to-one mapping과 static scene parameterization의 제약 |
MapAnything은 “모든 3D task를 완전히 끝낸 모델”이라기보다, 다양한 입력 조건을 하나의 metric 3D reconstruction backbone으로 흡수하는 설계에 의미가 있다.
느낀점
(진행중...)
Problem: can one model cover fragmented 3D reconstruction tasks?
MapAnything starts from the observation that image-based 3D reconstruction is still split into many task-specific pipelines. SfM, calibration, pose averaging, BA, MVS, and monocular depth are connected, but they are usually solved as separate modules.
The paper tries to reduce this fragmentation by handling not only image-only inputs, but also settings where calibration, pose, depth, or partial reconstruction may be available.
The core question is not only “what if we have images,” but whether partial geometric hints can be used inside the same model.
SfM, MVS, calibration, and depth completion are usually separate pipelines.
Prior feed-forward models often constrain view count, modality, or camera model.
Datasets differ in depth, pose, metric scale, and calibration availability.
Factor geometry so the same structure can serve as both input and output.
The main idea is to build one representation that accepts multiple input conditions instead of training many task-specific models.
| Constraint | MapAnything's choice | Meaning |
|---|---|---|
| Fixed modality | Images plus optional rays, poses, and depth | Handles changing sensor or metadata availability |
| Coupled geometry | Factor into rays, depth, pose, and scale | Uses one language for prediction and conditioning |
| Dataset mismatch | Apply supervision only to available factors | Uses metric and up-to-scale datasets together |
Related Work details
The related work frames MapAnything as a universal 3D backbone for heterogeneous geometric inputs, rather than simply a larger image-only reconstruction model.
From DeMoN, DeepTAM, and DeepV2D to DUSt3R, VGGSfM, and VGGT.
DUSt3R/MASt3R need pointmap recovery and post-processing, while VGGT/FASt3R retain redundant output issues.
Rays, origins, and depth maps have been used as conditioning inputs, but not as the central interface for universal feed-forward 3D reconstruction.
Pow3R uses known priors but is limited to two pinhole images, centered principal point, and non-metric scale.
Mechanism: how does the model factor and predict geometry?
The method does not predict one coupled pointmap directly. Instead, it decomposes the scene into local ray directions, up-to-scale ray depths, camera poses, and one global metric scale, then composes these factors into metric 3D.
MapAnything uses geometry factors as a shared interface for both inputs and outputs.
| Stage | Role | Device |
|---|---|---|
| Input factorization | Represent intrinsics, pose, and depth as ray directions, quaternion/translation, and ray depths | Generic central projection camera plus metric/up-to-scale separation |
| Multi-modal encoding | Put image and geometry features into one token space | DINOv2 ViT-G, shallow conv encoder, MLP encoder |
| Transformer fusion | Exchange information across views | 16-layer / 24-head alternating attention, reference view embedding, no RoPE |
| Factored decoding | Predict rays/depth/masks/confidence, camera poses, and scene scale separately | DPT head, pose head, scale-token MLP |
The model receives \(N\) RGB images and optional geometry that may only exist for some views. The output is one metric scale plus per-view factored geometry.
Predicted rays and depths form local pointmaps; poses and metric scale lift them into one global metric frame.
Translation and depth are entangled with scale. The paper separates pose scale and depth scale, and log-transforms metric scale values to handle large scene-scale variation.
MapAnything does not predict one coupled pointmap directly. It separates rays, depth, pose, and metric scale, then composes them back into metric 3D.
| Notation | Meaning | How to read it |
|---|---|---|
| \(\hat I\), \([\hat R,\hat Q,\hat T,\hat D]\) | RGB images and optional geometry inputs | Hats denote provided input or supervision factors when available. |
| \(m\) | Predicted global metric scale | The scalar that converts local or up-to-scale geometry into metric 3D. |
| \(R_i\), \(\tilde D_i\), \(\tilde P_i\) | Ray direction, up-to-scale ray depth, and pose-like transform for view \(i\) | The three main geometry factors predicted per view. |
| \(\tilde L_i\), \(\tilde X_i\), \(X_i^{metric}\) | Local ray-depth point, posed point, and final metric point | Ray-depth geometry becomes metric reconstruction after pose and scale. |
| \(O_i\), \(\tilde T_i\) | Rotation matrix derived from quaternion \(Q_i\) and translation component | Transform elements that lift local ray-depth points into posed points. |
| \(S_t\), \(\hat z_p\) | Views with provided translation and the derived pose scale | Translation supervision defines the scale reference through average distance. |
| \(\operatorname{sg}(\cdot)\), \(f_{\log}\) | Stop-gradient and log-space compression | Keeps scale supervision from destabilizing the geometry factors. |
| \(C_i\), \(\mathcal L_{mask}\) | Confidence and mask terms | Control ambiguous pixels and invalid geometry regions. |
Training losses and datasets
Not every dataset provides every label. The paper therefore combines ray, rotation, translation, depth, pointmap, scale, normal, gradient matching, and mask losses according to available supervision.
| Loss family | Target | Role |
|---|---|---|
| Scale-independent | Ray direction and quaternion rotation | Direct regression independent of scene scale |
| Scale-normalized | Depth, translation, local/world pointmaps | Use metric and up-to-scale annotations together |
| Metric scale | Global scale factor | Uses stop-gradient so geometry is not corrupted by scale loss |
| Detail / robustness | Normal, gradient matching, mask | Handles details and ambiguous regions |
Geometry input augmentation is applied with overall probability 0.9. Ray directions, ray depth, and poses each have input probability 0.5. Depth inputs are either dense or 90% sparsified, and per-view input probability 0.95 teaches the model to handle partial geometry availability. Normal and gradient-matching losses are applied only to synthetic datasets to avoid noisy real geometry.
Uses 13 datasets spanning indoor, outdoor, and in-the-wild scenes.
Precomputes pairwise covisibility from depth/pose and samples connected view graphs with a 25% threshold.
The paper adds pose/camera metadata to MPSD to enable real-world multi-view metric-scale training and releases that metadata.
The Apache 2.0 model uses six datasets, while the non-commercial model adds seven more.
Evidence: where is universality validated?
The evaluation is easiest to read by task. MapAnything tests dense multi-view reconstruction, two-view reconstruction, single-image calibration, metric depth, and ablations across both image-only and geometry-conditioned settings.
The key evidence is that the same model can exploit additional geometry when it is available.
Tests 2 to 100 views under image-only and geometry-input settings.
Compares against specialist models for single-view calibration and robust metric depth.
Separates the effect of RDP & Scale representation and universal training.
Calibration / depth / ablation supporting results
These results support MapAnything's breadth, while the core evidence appears first in dense multi-view and two-view reconstruction.
Tests perspective calibration despite no single-image-specific training.
Checks both single-view and multi-view metric depth on Robust-MVD.
Validates RDP & Scale representation and universal training.
Usage / Limits: when is it useful?
MapAnything is useful when images may be accompanied by partial geometric metadata. Robotics, mapping, and dataset curation often provide calibration, pose, or depth only for some views, which matches the paper's flexible input setting.
The limitations clarify where this universal backbone still needs future work.
| Category | Summary | Reason |
|---|---|---|
| Good fit | Multi-view reconstruction with mixed image, calibration, pose, or depth inputs | Optional geometry is part of the representation |
| Good fit | Testing SfM, MVS, metric depth, and calibration from one backbone | Broad task settings without task-specific tuning |
| Caution | Noisy or uncertain geometric inputs | The paper does not explicitly model input uncertainty |
| Extension | Novel-view-synthesis-like tasks where target views only have cameras | The paper mentions this as an architectural extension, not current support |
| Limitation | Very large scenes, dynamic motion, or scene flow | One-to-one pixel output and static scene parameterization remain limiting |
MapAnything is best read as a representation and training design for absorbing diverse input conditions into one metric 3D reconstruction backbone.
Takeaway
(Writing in progress...)
Comments