핵심 요약
NeRF는 scene을 voxel이나 mesh가 아니라, 3D 위치와 viewing direction을 입력받아 density와 view-dependent color를 출력하는 연속 5D neural radiance field로 표현한다.
NeRF의 핵심은 MLP가 장면 자체를 저장하고, differentiable volume rendering으로 관측 image와 맞추며 학습한다는 점이다.
5D Radiance Field
위치 x와 방향 d에서 density σ와 RGB radiance c를 예측하는 continuous scene function.
Differentiable Rendering
ray별 volume rendering integral을 differentiable하게 근사해 image reconstruction loss로 최적화.
Positional Encoding
저주파에 치우친 MLP가 high-frequency geometry/texture를 표현하도록 좌표를 고주파 feature로 확장.
Hierarchical Sampling
coarse network가 찾은 중요한 구간에 fine samples를 더 배치해 ray sampling 효율 개선.
NeRF는 “3D를 어떻게 저장할까”보다 “image로부터 3D function을 어떻게 differentiable하게 학습할까”가 핵심이다. volume rendering이 학습 가능한 bridge 역할을 한다.
명시적 discretization
고해상도 장면에서 memory와 sampling cost가 커짐.
surface 중심
SDF/occupancy는 geometry에는 강하지만 복잡한 view-dependent appearance 표현이 어려웠음.
volumetric radiance field
continuous density와 view-dependent radiance를 volume rendering으로 image에 투영.
논문 상세 정리
아래부터는 기존 논문 내용을 최대한 담은 상세 해석이다. 핵심 흐름에서 벗어나는 배경지식, notation, 부가 자료는 접어두었다.
Problem: image supervision만으로 3D scene을 어떻게 학습하나
초록은 NeRF를 sparse input views에서 novel view synthesis를 수행하기 위한 continuous volumetric scene representation으로 소개한다. 입력은 5D coordinate, 출력은 volume density와 view-dependent emitted radiance이며, rendering loss로 scene-specific MLP를 최적화한다.
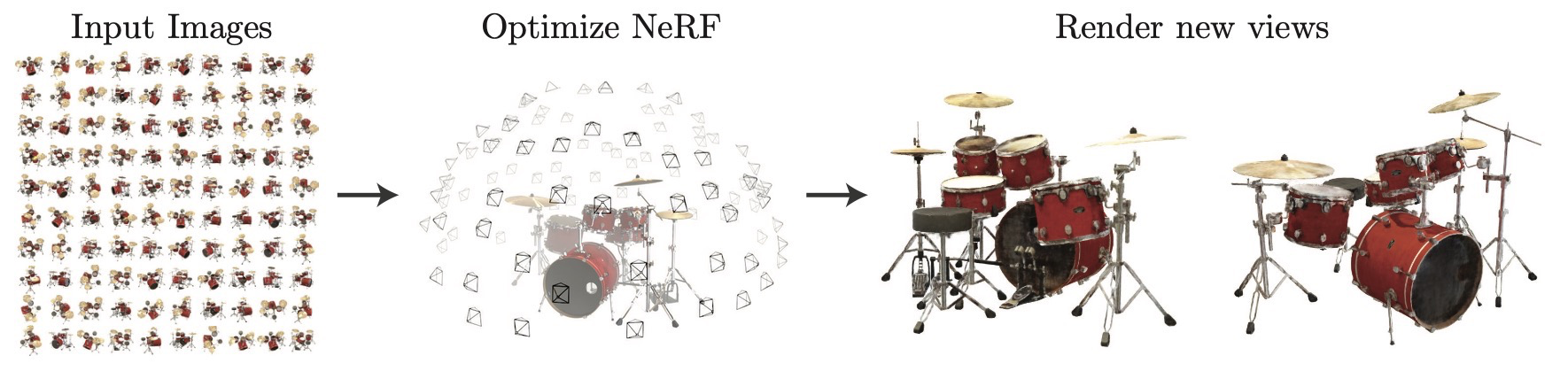
NeRF는 scene을 neural function으로 저장하고, rendering을 통해 supervision을 받는다.
| 요소 | 역할 | 의미 |
|---|---|---|
| 5D input | (x,y,z,θ,φ) 또는 (x,d) | 위치와 보는 방향을 함께 조건으로 사용 |
| Output | (c, σ) | view-dependent color와 density |
| Training signal | rendered RGB와 ground truth RGB 차이 | 3D supervision 없이 posed images로 학습 |
Related Work 맥락 보기
논문은 image-based rendering과 neural scene representation의 빈틈을 volume rendering 기반 neural field로 연결한다.
입력 view를 보간해 novel view를 만들지만, sparse view와 복잡한 geometry에서 한계가 있음.
dense capture에서는 강하지만, 적은 view에서 scene geometry를 일반화하기 어려움.
MLP로 implicit surface나 occupancy를 표현하는 흐름을 이어받음.
rendered image와 ground truth image의 차이로 3D representation을 학습하는 근거.
핵심 차이는 density와 view-dependent color를 함께 예측하고, classical volume rendering 식을 end-to-end training objective로 쓴다는 점이다.
| 기존 흐름 | 남는 빈틈 | NeRF의 연결 |
|---|---|---|
| Explicit geometry | mesh/voxel 품질이 view synthesis 성능을 제한 | continuous density field로 geometry를 암시적으로 표현 |
| Pure image interpolation | view가 sparse하면 occlusion과 parallax가 어려움 | ray integration으로 3D consistency를 학습 |
| Neural implicit field | appearance와 view direction 처리가 분리되기 쉬움 | position은 density, direction은 color에 조건으로 반영 |
Mechanism: radiance field와 volume rendering으로 어떻게 렌더링하나
NeRF의 scene function은 density σ(x)를 위치만의 함수로 두고, color c(x,d)는 위치와 viewing direction의 함수로 둔다. 이렇게 해서 geometry는 multi-view consistent하게 유지하면서 specular 같은 view-dependent appearance를 표현한다.
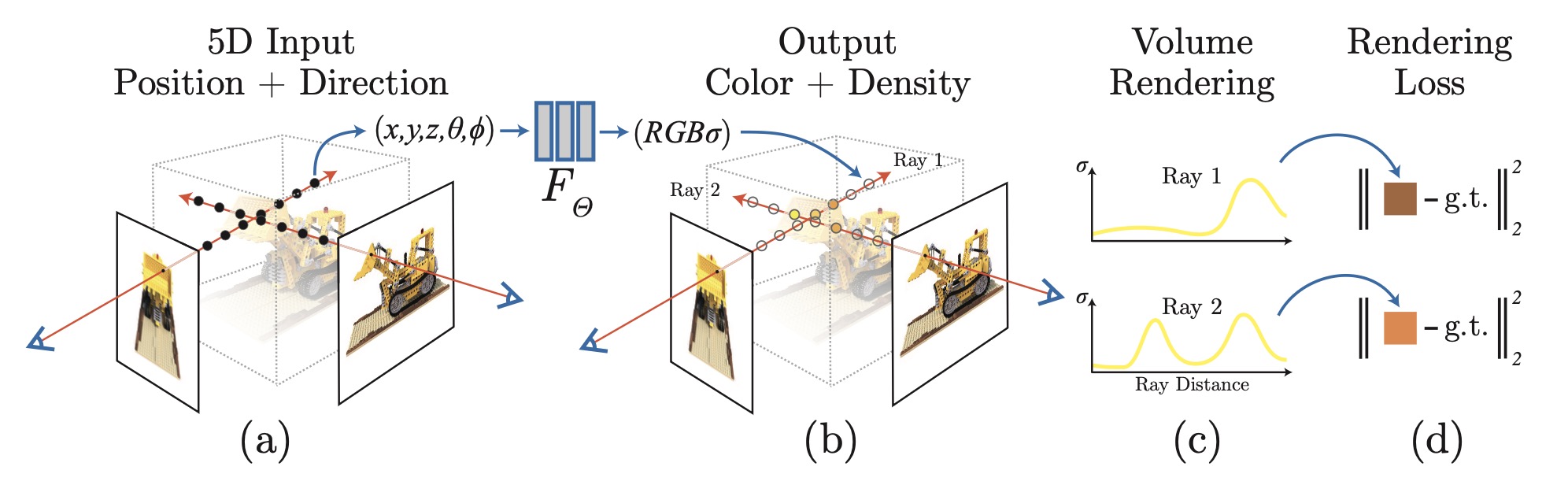
NeRF의 수식은 ray 위의 sample들이 각자 색을 조금씩 기여하고, 앞쪽 density가 뒤쪽 color를 가리는 구조로 읽으면 된다.
| 기호 | 의미 | 읽는 포인트 |
|---|---|---|
| σ | volume density | ray가 해당 지점에서 종료될 확률과 연결 |
| | transmittance | 앞쪽 물질을 통과해 t까지 도달할 확률 |
| αi | 1-exp(-σiδi) | discrete alpha compositing으로 구현 |
Mechanism: positional encoding과 hierarchical sampling은 왜 필요한가
기본 MLP만으로는 high-frequency geometry와 texture를 잘 표현하지 못한다. NeRF는 좌표를 sinusoidal positional encoding으로 확장하고, coarse network로 중요한 ray 구간을 찾은 뒤 fine network가 그 구간에 sample을 더 배치한다.
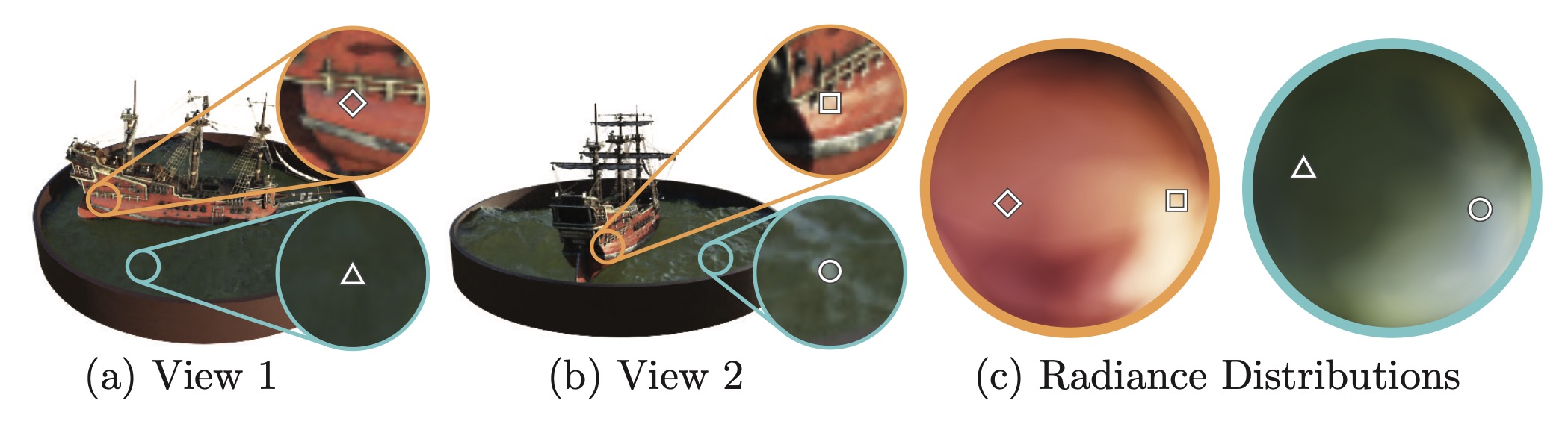

positional encoding은 표현력을, hierarchical sampling은 sample 효율을 담당한다.
| 개선 | 문제 | 효과 |
|---|---|---|
| Positional encoding | MLP가 low-frequency function부터 배우는 bias | fine texture와 sharp geometry 표현 개선 |
| View dependence | specular / non-Lambertian appearance | direction별 radiance distribution 학습 |
| Hierarchical sampling | free space와 occluded region에 sample 낭비 | visible content 주변에 fine samples 집중 |
Sampling / hierarchical sampling 보조 수식 보기
Sampling 보조 수식
본문에서 핵심으로 펼쳐둔 Eq. (1), (3), (4), (6) 외에, hierarchical sampling에서 이어지는 Eq. (2), (5)를 보조로 정리했다.
Evidence: view synthesis와 ablation을 어떻게 검증했나
결과는 synthetic 360°, real forward-facing scene에서 NeRF가 SRN, Neural Volumes, LLFF보다 더 높은 photorealistic view synthesis 품질을 보인다는 흐름이다. ablation에서는 positional encoding과 view dependence가 가장 큰 영향을 준다.
PSNR/SSIM/LPIPS 수치보다, 어떤 설계가 어떤 artifact를 줄이는지 같이 봐야 한다.
complex geometry와 non-Lambertian material에서 prior method보다 높은 품질.
LLFF보다 multiview consistency와 fine detail이 안정적.
scene-specific MLP weights가 voxel/MPI grid보다 훨씬 작음.
scene마다 100-300k iteration, V100 기준 1-2일 수준.
positional encoding, view dependence, hierarchical sampling 모두 성능에 기여.
optimization/rendering 효율과 neural representation 해석 가능성은 과제로 남음.


Usage / Limits: 효율과 해석 가능성에서 무엇을 조심하나
원문 discussion은 NeRF가 NV, SRN, LLFF보다 정량/정성적으로 우수한 이유를 각 baseline의 failure mode와 연결한다. SRN은 ray마다 하나의 depth/color만 고르는 구조라 geometry와 texture가 과도하게 smooth해지고, NV는 explicit voxel grid 때문에 고해상도 detail 확장성이 제한되며, LLFF는 large disparity와 representation blending에서 일관성이 흔들린다.
느낀점
(진행중...)
Problem: how can image supervision learn a 3D scene?
NeRF is introduced as a continuous volumetric scene representation for novel view synthesis from sparse input views. Its input is a 5D coordinate, its output is volume density and view-dependent emitted radiance, and a scene-specific MLP is optimized through rendering loss.
NeRF stores a scene as a neural function and supervises it through rendering.
| Element | Role | Meaning |
|---|---|---|
| 5D input | (x,y,z,θ,φ) or (x,d) | Conditions on both position and view direction. |
| Output | (c, σ) | View-dependent color and density. |
| Training signal | Rendered RGB vs. ground-truth RGB. | Uses posed images without direct 3D supervision. |
Related Work Context
The paper connects image-based rendering and neural scene representations through a neural field trained with volume rendering.
Interpolates input views, but sparse views and complex geometry remain difficult.
Works well with dense capture, but struggles to generalize geometry from few views.
Provides the idea of representing surfaces or occupancy with an MLP.
Supplies the training signal: compare rendered images with ground-truth images.
The key difference is predicting density and view-dependent color together, then using classical volume rendering as the end-to-end objective.
| Prior line | Remaining gap | NeRF connection |
|---|---|---|
| Explicit geometry | Mesh or voxel quality limits view synthesis. | Represents geometry implicitly as a continuous density field. |
| Pure image interpolation | Occlusion and parallax are hard under sparse views. | Learns 3D consistency through ray integration. |
| Neural implicit field | Appearance and view direction can be handled separately. | Uses position for density and view direction for color. |
Mechanism: how radiance fields and volume rendering render views
NeRF makes density σ(x) depend only on position, while color c(x,d) depends on both position and view direction. This preserves multi-view geometry while representing view-dependent appearance such as specularities.
Read the ray equation as sampled points contributing colors, while earlier density occludes later colors.
| Symbol | Meaning | Reading point |
|---|---|---|
| σ | Volume density. | Related to ray termination probability. |
| | Transmittance. | Probability the ray reaches t without termination. |
| αi | 1-exp(-σiδi) | Implements discrete alpha compositing. |
Mechanism: why positional encoding and hierarchical sampling matter
A plain MLP struggles with high-frequency geometry and texture. NeRF expands coordinates using sinusoidal positional encoding, then uses a coarse network to identify important ray regions and allocates fine samples there.
Positional encoding improves expressivity; hierarchical sampling improves sample efficiency.
| Improvement | Problem | Effect |
|---|---|---|
| Positional encoding | MLPs are biased toward low-frequency functions. | Improves fine texture and sharp geometry. |
| View dependence | Specular and non-Lambertian appearance. | Learns direction-dependent radiance. |
| Hierarchical sampling | Wasted samples in free or occluded space. | Concentrates fine samples near visible content. |
Sampling / hierarchical sampling support formulas
Sampling support formulas
Beyond Eq. (1), (3), (4), and (6), this section keeps the hierarchical sampling equations Eq. (2) and Eq. (5) visible.
Evidence: how view synthesis and ablations are tested
The results show that NeRF produces higher-quality photorealistic novel views than SRN, Neural Volumes, and LLFF on synthetic 360-degree and real forward-facing scenes. The ablations show that positional encoding and view dependence matter most.
Beyond PSNR/SSIM/LPIPS, read which design choice reduces which visual artifact.
Improves quality on complex geometry and non-Lambertian materials.
Better fine detail and multiview consistency than LLFF.
Scene-specific MLP weights are much smaller than voxel/MPI grids.
Requires 100-300k iterations per scene, about 1-2 days on V100.
Positional encoding, view dependence, and hierarchical sampling all help.
Efficiency and interpretability remain open problems.
Usage / Limits: what to watch about efficiency and interpretability
The paper's discussion links NeRF's quantitative and qualitative gains to the failure modes of each baseline. SRN oversmooths geometry and texture because it selects only one depth and color per ray, NV is limited by its explicit voxel grid at high resolution, and LLFF can struggle with large disparity and view-inconsistent blending.
Takeaway
(In progress...)
Comments