핵심 요약
SLIM-VDB는 OpenVDB의 sparse volumetric backend에 Bayesian semantic fusion을 붙여, closed-set과 open-set 의미 정보를 실시간 3D map 안에 확률적으로 누적하는 framework다.
SLIM-VDB는 단순히 가벼운 voxel map이 아니라, sparse OpenVDB 저장 구조와 Bayesian uncertainty update가 함께 맞물리도록 만든 semantic mapping framework다.
OpenVDB Backend
TSDF geometry와 semantic parameter를 sparse hierarchical voxel grid에 저장해 memory와 query/update 비용을 줄임.
Unified Bayesian Fusion
closed-set Dirichlet-Categorical과 open-set Normal-Inverse-Gamma update를 하나의 framework 안에서 다룸.
Real-Time Efficiency
SOTA semantic mapping baseline보다 integration time과 memory를 줄이면서 semantic/geometric accuracy는 비슷하게 유지.
Robotics Interface
C++ core와 Python interface, NanoVDB rendering을 통해 실제 mobile robot application에 붙이기 쉬운 형태를 지향.
SLIM-VDB의 흥미로운 지점은 semantic mapping을 저장 구조 문제와 belief update 문제를 동시에 푸는 작업으로 본다는 점이다. OpenVDB는 정보를 어디에 싸게 저장할지 결정하고, Bayesian fusion은 흔들리는 label을 시간에 따라 어떻게 누적할지 결정한다.
semantic prediction이 OpenVDB voxel update와 Bayesian fusion으로 들어가는 순서.
closed-set, open-set, sparse backend가 각각 맡는 역할을 분리한다.
closed-set 의미 누적
semantic class를 categorical observation으로 보고 Dirichlet posterior를 voxel마다 갱신.
언어 feature 누적
CLIP/VLM feature embedding을 Gaussian observation으로 보고 Normal-Inverse-Gamma posterior를 갱신.
희소 voxel backend
surface 주변 voxel만 효율적으로 저장/조회해 large map에서 memory 부담을 낮춤.
논문 상세 정리
아래부터는 기존 논문 내용을 최대한 담은 상세 해석이다. 핵심 흐름에서 벗어나는 배경지식, notation, 부가 자료는 접어두었다.
Problem: semantic 3D map을 왜 실시간으로 유지해야 하나
초록은 SLIM-VDB를 경량 데이터 구조와 확률적 semantic fusion을 결합한 real-time semantic mapping framework로 위치시킨다.
| 문제 | SLIM-VDB의 답 | 읽는 포인트 |
|---|---|---|
| OpenVDB gap | OpenVDB는 geometric mapping에 쓰였지만 semantic mapping 적용은 비어 있었음 | 백엔드는 storage trick이 아니라 semantic map까지 담는 기반 |
| Semantic uncertainty | closed-set과 open-set label prediction을 하나의 Bayesian update 틀로 통합 | 불확실성을 누적해 frame-level flickering을 줄이는 방향 |
| Efficiency claim | memory와 integration time을 줄이면서 mapping accuracy는 비슷하게 유지 | 정확도 단독 SOTA보다 실시간 운용성의 균형이 핵심 |
요약하면 이 논문은 semantic mapping을 더 큰 neural model로 밀어붙이기보다, 이미 robotics에서 쓸 수 있는 sparse volumetric 구조 위에 확률적 update를 얹는 방향을 택한다. 그래서 초록에서 말하는 real-time 성능은 단순한 구현 최적화가 아니라, map을 저장하는 방식과 label uncertainty를 누적하는 방식이 함께 맞물린 결과로 읽는 것이 자연스럽다.
Abstract 세부 흐름 보기
초록의 세부 메모는 “무엇을 만들었나, 어떤 빈칸을 겨냥하나, 어떤 결과를 주장하나”로 나누면 중복 없이 읽힌다.
closed-set 또는 open-set dictionary를 위한 probabilistic semantic fusion을 갖춘 lightweight semantic mapping system.
volumetric scene representation에서 computation과 memory efficiency를 높인 sparse data structure.
기존 semantic mapping은 fixed-category와 open-language label prediction을 한 framework에서 다루기 어려움.
memory와 integration time을 줄이면서 semantic/geometric mapping accuracy는 comparable하게 유지.
아래 표는 기존 메모의 핵심 표현을 논문 초록의 claim 순서에 맞춰 다시 배치한 것이다.
| 세부 항목 | 핵심 내용 | 논문 흐름상 의미 |
|---|---|---|
| 제안하는 시스템 | SLIM-VDB는 closed/open-set dictionaries를 위한 확률적 semantic fusion을 포함 | 시스템의 정체성 |
| 기반 데이터 구조 | OpenVDB는 geometric mapping에는 쓰였지만 semantic mapping 적용은 아직 비어 있음 | 논문이 겨냥하는 technical gap |
| 논문의 제안 | OpenVDB data structure와 unified Bayesian update framework 결합 | method contribution |
| 주요 결과 | state-of-the-art semantic mapping 대비 memory/integration time 감소, accuracy는 comparable | evaluation에서 검증해야 할 claim |
Context: geometry/semantics/memory 병목은 무엇인가
Introduction은 “dense TSDF map은 좋지만 무겁고, semantic prediction은 흔들리며, open-set까지 같이 담는 프레임워크가 부족하다”는 순서로 문제를 쌓는다.
| 축 | 기존 한계 | SLIM-VDB가 가져오는 변화 |
|---|---|---|
| Geometry | TSDF는 dense reconstruction에 유용하지만 memory와 real-time 측면이 부담 | OpenVDB sparse hierarchy로 필요한 voxel 중심 저장/조회 |
| Semantics | segmentation label의 inconsistency와 flickering에 취약 | Bayesian update로 voxel-wise semantic belief를 누적 |
| Label space | closed-set 또는 open-set 중 한쪽만 다루는 경우가 많음 | Dirichlet-Categorical과 Normal-Inverse-Gamma를 같은 framework 안에서 운용 |
뒤에 이어지는 배경 설명은 “표현 방식, 불확실성, 저장 구조” 세 축으로 먼저 나누면 읽기 쉽다.
| 구간 | 핵심 내용 | SLIM-VDB로 이어지는 이유 |
|---|---|---|
| World representation | 로봇의 map은 geometry와 semantics를 함께 담아야 scene understanding과 task 수행에 쓰임 | semantic map을 단순 label overlay가 아니라 로봇이 조회하는 상태로 다룸 |
| TSDF / VDBFusion | TSDF는 dense reconstruction에 강하지만 dense storage는 부담, OpenVDB 기반 VDBFusion은 효율적 geometry mapping을 보임 | 효율적인 volumetric backend를 semantic mapping으로 확장할 여지 |
| Semantic uncertainty | non-probabilistic fusion은 label inconsistency와 flickering에 취약 | Bayesian update로 voxel-wise belief와 uncertainty를 누적 |
| Open-set pressure | closed-set은 단순 world understanding에 유용하지만 open-language representation 수요가 증가 | closed-set과 open-set을 한 framework에서 다루는 설계 필요 |
이 배경을 연결해서 보면, SLIM-VDB의 문제의식은 “semantic label을 더 잘 예측하자”에 머물지 않는다. 로봇이 계속 움직이며 관측을 쌓는 상황에서, geometry와 semantics를 같은 3D map 안에 유지하면서도 메모리와 계산 비용을 통제해야 한다는 요구가 논문의 출발점이다.
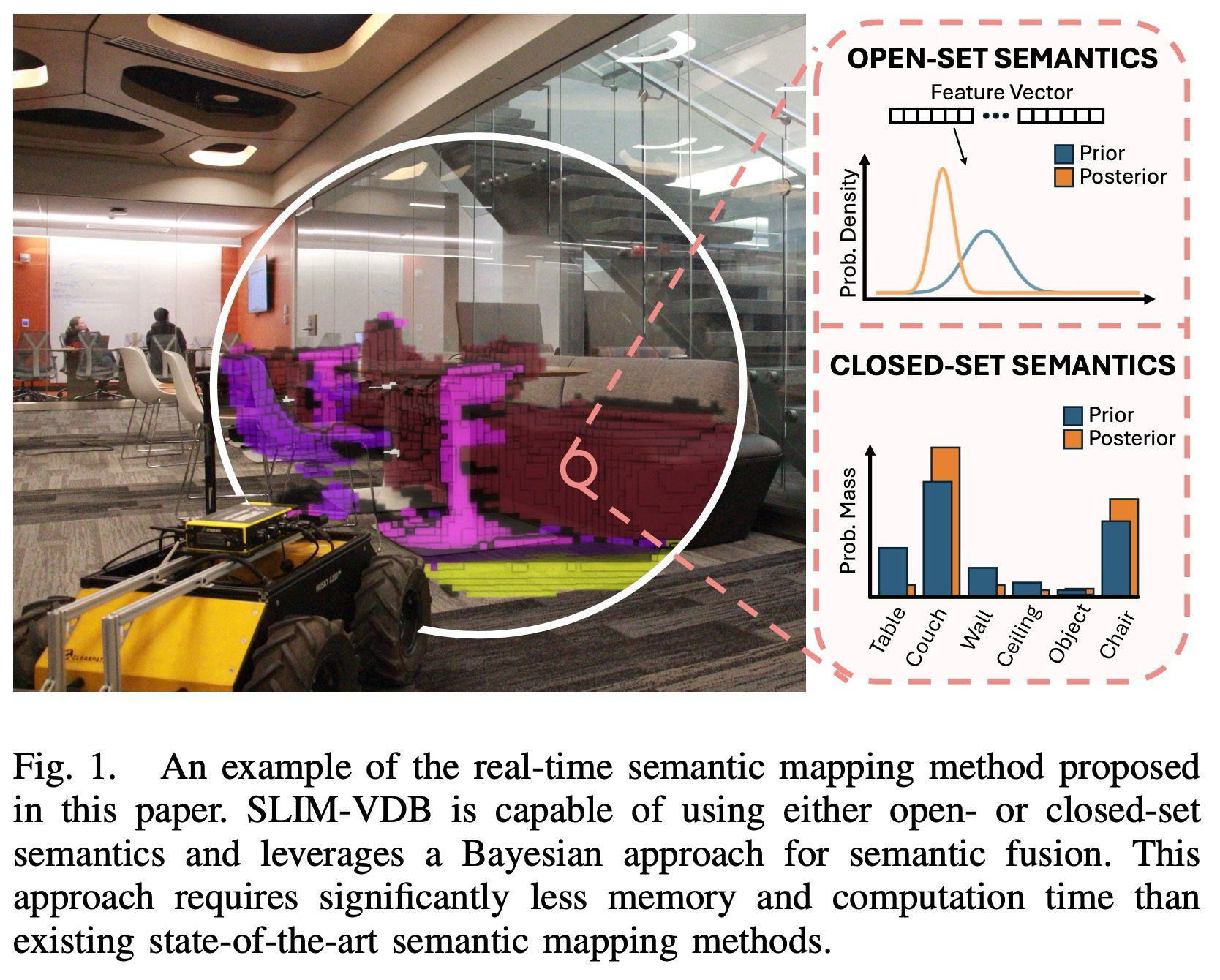
로봇이 실제 환경에서 안정적으로 작업하려면, 단순한 3D reconstruction보다 더 풍부한 월드 맵이 필요하다. 이때 semantic map은 객체나 공간의 의미를 저장하지만, frame마다 흔들리는 segmentation 결과를 그대로 누적하면 label이 쉽게 불안정해진다.
Introduction 초반의 핵심은 map을 단순한 3D 형상 저장소가 아니라, 로봇이 작업을 수행하기 위해 조회하는 상태 표현으로 보는 것이다.
| 구성 요소 | 역할 | 읽는 포인트 |
|---|---|---|
| Geometry | 환경의 접촉 표면과 free/occupied structure 표현 | TSDF 기반 dense reconstruction과 충돌/탐색의 기반 |
| Semantics | 객체와 공간의 의미 정보를 map에 누적 | scene understanding과 복잡한 robot task 수행에 필요 |
| Uncertainty | frame-level semantic prediction의 흔들림을 voxel-level belief로 흡수 | label inconsistency와 flickering을 그대로 map에 쓰지 않기 위한 장치 |
논문은 semantic mapping을 closed-set과 open-set으로 나눠 보고, 둘을 같은 framework 안에서 다루는 것이 필요하다고 본다.
| 구분 | 의미 | 장점 / 한계 |
|---|---|---|
| Closed-set | 사전에 정의된 class 안에서만 예측 | 간단한 world understanding에는 충분하지만, 학습 시점 밖의 category나 언어 query에는 취약 |
| Open-set | 시스템이 미리 알지 못한 class나 language-linked concept까지 표현 | open-language representation 수요에 대응하지만, feature distribution과 불확실성 처리가 중요 |
| SLIM-VDB의 위치 | closed-set label과 open-set feature를 모두 Bayesian semantic fusion 대상으로 둠 | 두 setting을 별도 시스템이 아니라 하나의 sparse volumetric backend에서 다루려는 시도 |
따라서 이 구간은 “closed-set이 낡았고 open-set이 새롭다”는 단순한 대립보다, 실제 로봇 map이 두 종류의 semantic evidence를 모두 받아들여야 한다는 문제의식으로 읽는 편이 자연스럽다.
SLIM-VDB의 backend 선택은 TSDF, OpenVDB, VDBFusion의 장점과 빈틈을 이어받는다.
| 개념 | 기존 역할 | SLIM-VDB로 이어지는 이유 |
|---|---|---|
| TSDF | Truncated Signed Distance Function. 환경의 접촉 표면을 표현해 dense reconstruction 수행 | 기하학적으로 좋은 표면 복원이 가능하지만, dense storage는 memory와 real-time 측면에서 부담 |
| OpenVDB | 컴퓨터 그래픽스 커뮤니티에서 개발된 sparse volumetric data structure | 필요한 voxel 중심으로 저장/조회하여 large-scale map의 메모리 부담 완화 |
| VDBFusion | OpenVDB를 로봇 geometry mapping에 활용한 사례 | 속도, 메모리 효율, 기하 정확도는 강하지만 semantic mapping은 제공하지 않음 |
| Non-probabilistic semantic mapping | semantic segmentation output을 map에 직접 누적 | semantic label inconsistency와 flickering에 약해 uncertainty-aware fusion 필요 |
기존 Bayesian semantic mapping 연구들은 불확실성은 다뤘지만, 계산 비용과 semantic scope 측면에서 SLIM-VDB가 파고드는 빈틈을 남겼다.
| 기존 접근 | 얻은 것 | 남은 한계 |
|---|---|---|
| Bayesian update | closed-set 또는 open-set semantics의 semantic uncertainty 정량화 | 연산량이 크고 map update가 무거워질 수 있음 |
| Closed-set 중심 방법 | 사전 정의 class에 대한 안정적인 semantic belief 누적 | open-language query나 미지 category 표현에 제한 |
| Open-set 중심 방법 | VLM/feature embedding 기반 open-dictionary query 가능성 | 실시간 운용과 map scale이 GPU memory에 묶이기 쉬움 |
| SLIM-VDB의 gap | OpenVDB의 sparse hierarchy에 Bayesian semantic fusion 결합 | closed/open-set semantics를 real-time, memory-efficient 3D mapping 안에서 같이 다루는 방향 |
Introduction의 제안은 “무엇을 저장하나, 어떻게 갱신하나, 어디서 쓸 수 있나”로 나누면 장문 bullet을 따라가기 쉬워진다.
| 축 | 논문이 제안하는 것 | 의미 |
|---|---|---|
| Storage | OpenVDB backend에 TSDF와 semantic parameters 저장 | dense allocation 없이 large-scale semantic mapping을 다룸 |
| Fusion | closed-set label과 open-set feature를 Bayesian update로 통합 | label flickering과 uncertainty를 voxel 단위로 누적 |
| Deployment | C++ core, Python interface, NanoVDB rendering 제공 | mobile robot application과 visualization까지 고려 |
Contribution 세부 항목 보기
위 표에서 압축한 contribution을 세부 항목 기준으로 다시 확인하는 보충 구간이다.
| 항목 | 세부 내용 |
|---|---|
| SLIM-VDB | Semantic Lightweight Implicit Mapping system. closed-set과 open-set dictionaries를 위한 probabilistic semantic fusion 포함 |
| Unified update | closed/open-set semantics에서 real-time, memory-efficient semantic mapping을 가능하게 하는 Bayesian semantic fusion update step |
| Novelty | semantic mapping을 위해 OpenVDB backend를 사용하고, closed/open-set class labels를 위한 통합 확률적 semantic fusion update 제안 |
| Open source | robotics application을 위한 C++ core와 Python interface 제공 |
Gap: OpenVDB와 probabilistic semantics 사이에 무엇이 비어 있나
Related Works는 SLIM-VDB가 세 흐름을 이어받는다고 보면 된다: OpenVDB 기반 geometric mapping, probabilistic semantic mapping, open-dictionary semantic mapping.
| 계열 | 대표 흐름 | SLIM-VDB의 위치 |
|---|---|---|
| Geometric Mapping | OctoMap, Voxblox, Voxfield, VDBFusion | OpenVDB의 runtime/memory 장점을 semantic map으로 확장 |
| Semantic Fusion | ConvBKI, SEE-CSOM | Bayesian uncertainty는 유지하되 dense/global scalability 문제를 줄임 |
| Open Dictionary | VLM, CLIP, LatentBKI | open-language feature를 voxel map에 넣되 real-time/memory 제약을 강조 |
Related Works는 개별 방법을 외우기보다, SLIM-VDB가 어떤 빈칸을 채우는지 확인하는 용도로 읽으면 충분하다. 기존 geometric mapping은 효율적인 3D 구조를 제공했지만 semantic uncertainty를 본격적으로 다루지 않았고, probabilistic semantic mapping은 불확실성을 다뤘지만 큰 map에서의 runtime과 memory 부담이 남아 있었다.
Related Works 세부 배경 보기
이 토글은 개별 논문명을 나열하기보다, SLIM-VDB가 어떤 연구 계열의 장점과 빈틈을 이어받는지 확인하는 용도다.
OctoMap, Voxblox, Voxfield Panmap, VDBFusion은 efficient TSDF/voxel mapping 흐름을 만든다.
ConvBKI와 SEE-CSOM은 Bayesian semantic fusion으로 uncertainty를 다루지만 runtime/memory 부담이 남는다.
VLM과 LatentBKI는 language-linked feature space를 map으로 확장하지만 real-time과 scale이 병목이다.
Related Works의 geometric mapping 파트는 “3D geometry를 효율적으로 저장하는 계열은 발전했지만, semantics가 빠져 있다”는 주장으로 이어진다.
| 방법 | 핵심 역할 | SLIM-VDB 관점의 빈칸 |
|---|---|---|
| OctoMap | real-time, dynamic, multi-resolution, probabilistic 3D mapping의 초기 표준 | TSDF surface reconstruction 품질/속도 측면에서는 이후 방법이 개선 |
| Voxblox | TSDF 기반 implicit surface representation으로 update speed와 reconstruction quality 개선 | semantic uncertainty와 open-set semantics까지는 핵심 범위가 아님 |
| Voxfield Panmap | instance/semantic 정보를 Voxblox 계열에 확장 | SLIM-VDB가 비교하는 non-Bayesian semantic mapping baseline |
| VDBFusion | OpenVDB 기반 lightweight TSDF mapping. runtime/memory efficiency와 geometric accuracy가 강점 | semantic mapping 기능이 없어서 SLIM-VDB의 직접적인 확장 출발점 |
| NeRF / 3DGS | 고품질 dense reconstruction | mobile robot의 제한된 compute/memory에서는 voxel-based mapping이 여전히 practical |
Related Works의 semantic mapping 파트는 semantic map의 방향을 learning-based, Bayesian, open-dictionary로 나눠 놓는다.
| 계열 | 대표 내용 | 논문이 가져가는 포인트 |
|---|---|---|
| Voting / heuristic | 초기 semantic mapping은 voting이나 heuristic으로 label을 누적 | uncertainty를 체계적으로 표현하기 어렵다는 배경 |
| SNI-SLAM | appearance, geometry, semantic feature를 cross-attention으로 연결하는 neural implicit representation | real-time 가능성을 보였지만 professional server GPU 의존이 커 mobile robot에는 부담 |
| ConvBKI / SEE-CSOM | conjugate prior와 Bayesian inference로 voxel-wise semantic expectation/variance 추적 | uncertainty handling은 중요하지만 dense/global scalability와 memory/runtime이 병목 |
| VLM / open-dictionary | language와 공유되는 latent space로 unseen/synonymous category query 가능 | closed-set class list 밖의 semantics까지 map에 담아야 한다는 동기 |
| LatentBKI | feature embedding likelihood에 conjugate prior를 적용해 open-dictionary mapping 확장 | real-time 운용과 GPU memory scale이 SLIM-VDB의 비교 지점 |
data structure 관점에서 확인할 내용은 아래처럼 구현 근거 중심으로 정리했다.
| 항목 | 세부 내용 | SLIM-VDB와의 연결 |
|---|---|---|
| OpenVDB | DreamWorks Animation에서 개발된 sparse volumetric data structure. lookup/insertion/delete가 효율적이고 B+ tree 기반 footprint가 작음 | surface 주변 voxel의 signed distance, weight, semantic parameters를 memory-efficient하게 저장 |
| Level set / SDF | signed distance field로 알려진 level set data structure 활용 | TSDF surface reconstruction을 sparse hierarchy 안에서 운용하는 기반 |
| VDBFusion | OpenVDB C++ 구현을 robotics mapping에 사용. LiDAR frame integration과 geometry mapping에서 효율성을 보임 | SLIM-VDB가 semantic fusion을 얹는 직접적인 geometric backend reference |
| NanoVDB / NanoMap | NanoVDB는 GPU-friendly VDB representation. 기존 NanoVDB 활용 사례도 semantic information은 제한적 | SLIM-VDB는 semantic TSDF visualization까지 고려해 NanoVDB rendering을 붙임 |
Mechanism: sparse VDB에 Bayesian semantics를 어떻게 쌓나
Methodology는 표면 복원, semantic fusion, rendering으로 나누면 가장 깔끔하다. 수식은 “어떤 확률분포의 hyperparameter를 voxel마다 갱신하는가”에 초점을 두고 읽으면 된다.
| 파트 | 무엇을 업데이트하나 | 핵심 장치 |
|---|---|---|
| Surface Reconstruction | TSDF distance, voxel weight | OpenVDB sparse hierarchy + DDA ray casting + truncated region update |
| Closed-set Fusion | class probability mass | Dirichlet-Categorical conjugacy로 class count/α 누적 |
| Open-set Fusion | CLIP/VLM feature distribution | Normal-Inverse-Gamma/Normal conjugacy로 mean/variance 추정 |
| Rendering | semantic TSDF visualization | NanoVDB로 GPU rendering을 붙여 real-time viewing 지원 |
Method의 핵심은 입력 sensor나 segmentation model을 새로 정의하는 데 있지 않고, 들어온 관측을 OpenVDB voxel에 어떻게 누적할지 정하는 데 있다. Geometry는 TSDF update로 표면 근처의 구조를 유지하고, semantics는 관측이 반복될수록 posterior가 갱신되도록 만들어 frame 단위 예측의 흔들림을 map 수준에서 흡수한다.
SLIM-VDB의 수식은 “새로운 neural network”가 아니라 voxel에 쌓이는 관측을 어떤 conjugate prior로 닫힌 형태 업데이트할 것인가를 보여주는 장치다.
Bayesian semantic update 세부 보기
이 토글은 pipeline, notation, theorem을 한 흐름으로 묶어 확인하는 공간이다. 먼저 관측이 voxel state로 들어오고, geometry와 semantics가 각각 어떤 posterior state를 갱신하는지 따라가면 된다.
RGB-D 또는 point cloud에 semantic prediction을 붙여 semantic point cloud 생성.
DDA ray casting으로 update voxel을 찾고 TSDF distance/weight를 누적.
Categorical observation과 Dirichlet prior의 conjugacy로 class probability 갱신.
VLM feature를 Gaussian observation으로 보고 NIG/Normal conjugacy로 feature distribution 갱신.
posterior predictive와 NanoVDB rendering으로 semantic TSDF를 읽어냄.
notation은 외우는 대상이 아니라, 각 update가 어떤 voxel state를 바꾸는지 확인하기 위한 색인이다.
| 파트 | 핵심 상태 | 의미 |
|---|---|---|
| TSDF | Dt(x*),Wt(x*) | voxel의 signed distance와 cumulative weight |
| Closed-set | α | class별 Dirichlet parameter. posterior predictive를 계산하는 데 충분 |
| Open-set | m,λ,ν,β | feature distribution의 mean/variance를 추정하는 NIG hyperparameter |
| Query | Student-t predictive / cosine similarity | open-set feature evidence를 class probability나 text-query similarity로 읽는 장치 |
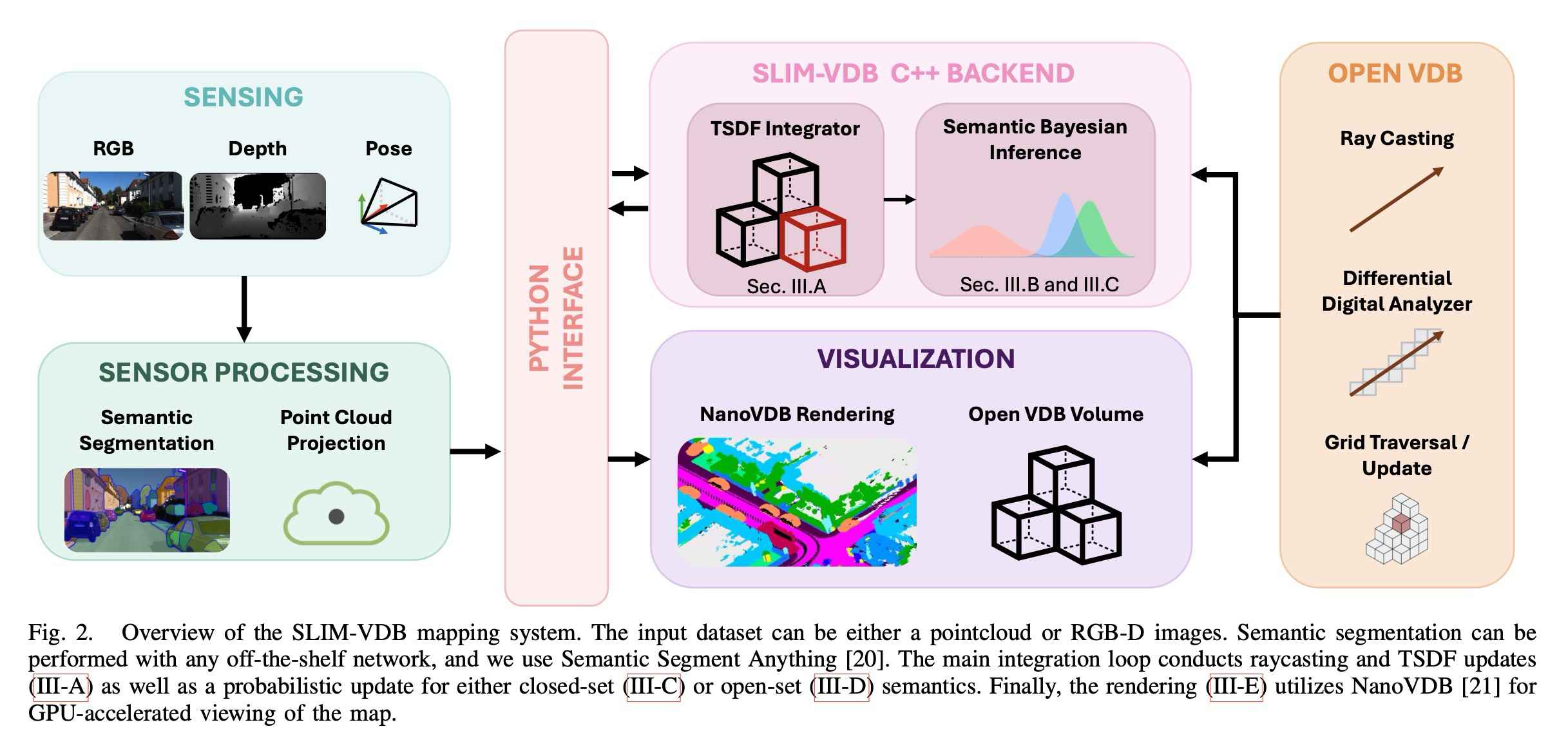
먼저 RGB-D/depth 관측과 semantic prediction을 3D semantic point cloud로 만든 뒤, OpenVDB의 sparse voxel 구조에 누적한다. 이 구간은 Bayesian update 이전에 “어떤 voxel을 업데이트할지” 정하는 준비 단계다.
RGB-D 이미지 또는 point cloud에 semantic prediction을 붙여 3D observation으로 변환.
표면 근처 voxel에 signed distance, weight, semantic parameter를 sparse하게 저장.
VDBFusion 계열의 OpenVDB DDA를 사용해 업데이트 대상 voxel을 찾음.
표면 주변의 configurable truncated region만 계산해 integration cost를 줄임.
아래 TSDF 식은 semantic fusion의 기반이 되는 geometry state를 갱신한다. 핵심은 voxel별 signed distance와 cumulative weight를 새 point cloud 관측으로 재귀 업데이트하는 것이다.
- 새로운 pointcloud → truncated signed distance 및 voxel 가중치 값 업데이트
Auxiliary. Recursive TSDF distance update.새 point-cloud 관측의 truncated signed distance와 voxel weight를 기존 TSDF state에 누적한다. Auxiliary. Cumulative TSDF weight update.새 관측의 voxel 가중치를 더해 다음 TSDF 평균에 사용할 누적 신뢰도를 갱신한다. - : 특정 시간 에서의 voxel
- Dt(x*): 누적된 signed distance
- : 새로운 센서값
- : 가중 함수
-
→ 보통 가중 함수는 1로 둔다고 함
-
closed-set과 open-set은 observation likelihood가 다르지만, 둘 다 conjugate prior를 사용해 voxel별 hyperparameter만 갱신한다는 점은 같다. 이 덕분에 매 프레임마다 posterior를 다시 풀지 않고 recursive update로 semantic belief를 누적할 수 있다.
| 구분 | 관측 모델 | 갱신되는 상태 |
|---|---|---|
| Closed-set | class label을 categorical observation으로 취급 | Dirichlet parameter α |
| Open-set | VLM feature를 Gaussian observation으로 취급 | NIG parameter m,λ,ν,β |
closed-set에서는 class label이 정해진 dictionary 안에 있다고 보고, categorical likelihood와 Dirichlet prior의 conjugacy를 사용한다. Theorem 1은 관측 count가 들어올 때 Dirichlet parameter만 더해도 posterior predictive를 계산할 수 있음을 정리하는 구간이다.
Closed-Set Semantic Fusion
- Dirichlet-Categorical conjugate
Auxiliary. Closed-set label support.closed-set semantic observation이 사전에 정한 k개 class dictionary 안에서 샘플링된다는 가정을 둔다. 는 정해진 sample space에서 샘플링된 Categorical(범주형) random variable을 나타낸다.
또한 아래와 같은 확률 밀도 함수를 가진다.
Eq. (2). Categorical observation likelihood.class label 관측을 categorical likelihood로 표현해 Dirichlet prior와 결합할 기반을 만든다.
위 Categorical 분포의 conjugate prior는 아래 Dirichlet distribution을 따른다.
- Dirichlet distribution
Auxiliary. Dirichlet prior density.categorical class probability vector에 대한 conjugate prior를 Dirichlet distribution으로 둔다. Dirichlet 분포는 벡터 로 파라미터화된 Beta 분포를 다변수로 일반화한 것으로, 위 수식과 같은 확률 밀도를 가지며, 는 감마 함수를 의미한다.
위 2개의 분포(범주형, Dirichlet)는 아래 이론에 의해 공식화된다.
Theorem 1: Dirichlet-Categorical conjugacy
위 semantic observation 집합은 범주형 분포 에 의해 각각 독립적으로 그려진다.
사전확률
- Dirichlet 분포:
사후 확률
- 관측값 와 파라미터 가 주어졌을 때, 의 사후 확률은 Dirichlet 분포를 따른다.
Eq. (5). Dirichlet posterior form.closed-set observations를 반영한 class probability posterior가 다시 Dirichlet form으로 유지됨을 보인다. 위 수식에서 는 업데이트된 Dirichlet 파라미터로, 아래 수식을 따른다.
Eq. (6). Dirichlet parameter update.각 class count를 기존 Dirichlet parameter에 더해 voxel-wise semantic belief를 갱신한다. 위 수식에서 는 indicator function으로, 관측값 가 클래스 에 속하면 1, 아니면 0으로 값이 결정된다.
위 Theorem 1은 Bayesian 접근법을 통해 시간별로 한 voxel에서 여러개의 semantic 예측값들을 통합할 수 있게 한다.
시간 마다 3차원 점들의 집합과, 일치하는 closed-set의 semantic 예측값들은 이산 랜덤 변수(discrete random variable)로, RGB-D 센서나 point cloud로 얻어진다.
- semantic 예측값
Auxiliary. Closed-set semantic point cloud.3D point와 이산 semantic prediction을 함께 저장해 voxel update의 입력으로 사용한다. 해당 semantic 예측값 는 보통 segmentation network에서 출력된 원핫 벡터(one-hot vector) 형태
각 voxel마다 Dirichlet posterior distribution을 구하기 위해, (6)번 수식을 이용하여 Bayes’ Rule을 재귀적으로 적용한다.
predictive posterior 계산에는 로 marginalizing하는 과정이 포함되어 직접 다루기 어렵다.
→ Dirichlet-Categorical conjugate pair는 이에 closed-form solution을 제공
위 수식을 보면, closed-set semantic 클래스들에 대해 posterior predictive 분포를 정의한다.
→ 실제로는 이러한 예측값을 계산하기 위해 Dirichlet 파라미터 만 추적하면 충분하다.
open-set에서는 class label 대신 VLM feature vector를 map에 누적한다. feature의 평균과 분산을 모두 불확실하게 두기 때문에 Normal-Inverse-Gamma / Normal conjugacy가 필요하고, Theorem 2는 이 update가 닫힌 형태로 유지됨을 설명한다.
Open-Set Semantic Fusion
open-set fusion은 feature vector의 평균과 분산을 함께 추정해야 하므로, 분포 가정과 conjugacy를 아래 두 역할로 나눠 읽으면 된다.
| 요소 | 역할 | 읽는 포인트 |
|---|---|---|
| Normal Inverse Gamma | feature mean과 variance에 대한 prior/posterior hyperparameter를 담는 분포 | 불확실한 feature 분포를 voxel마다 누적하기 위한 상태 표현 |
| Normal conjugate pair | Gaussian observation이 들어와도 posterior를 같은 family 안에서 유지 | 새 관측이 들어올 때 closed-form recursive update가 가능해지는 이유 |
는 독립적인 요소들로 이루어진 다변량 연속적 정규분포(Gaussian Random Variable)를 따르며, 아래 수식과 같은 확률 밀도를 가진다.
Normal Inverse Gamma (정규 역 감마)
- 다변수 연속적 확률 분포
- 4개의 파라미터:
→ 평균 와 분산 를 가지는 정규 분포의 확률 밀도를 정의
Eq. (9). Normal-Inverse-Gamma prior.feature mean과 variance의 uncertainty를 함께 추적하기 위한 conjugate prior를 정의한다. 여기서 은 inverse gamma function이며, Theorem 2에 따라 Normal Inverse Gamma 분포는 정규분포의 conjugate pair가 된다.
Theorem 2: Normal-Inverse-Gamma conjugacy
⇒ 알려지지 않은 평균과 분산을 가지는 동일한 정규분포 에서 샘플링된 데이터들의 집합
⇒ 와 를 사전확률로 가지는 Normal Inverse Gamma distribution
사후 확률은 베이즈 이론을 통해 구해지며, 또한 Normal Inverse Gamma distribution이다.
closed-form equation
위 수식에서 와 는 각각 의 고유 column 개수와 평균을 의미한다.
open-set semantics
- VLM의 feature space에서의 측정값을 독립항등분포(i.i.d)의 성질을 지니는 다변량 정규분포로 가정
- 입력
- RGB-D
- VLM
- 출력
- 3d points + semantic prediction
⇒
- : 3d points
- : 다변량 정규분포
- 평균, 분산 모름
- 3d points + semantic prediction
이는 feature embedding을 평균과 분산을 모르는 1차원의 정규분포로 나타낼 수 있게 해줌
Theorem 2에 따라,
의 각 원소들의 사후 확률을 손쉽게 구하기 위해,
정규 분포와 Normal Inverse Gamma 사이의 conjugate를 활용한다.
→ 이는 (11)~(14)번 수식에 정의된 파라미터 업데이트 과정에서 진행됨
이후 이전 단계의 semantic 정보가 주어지면,
정규분포 의 predictive posterior를 통해 open-set semantics에 대한 예측을 수행한다.
: Student t분포
: Student t분포의 기댓값 ( 일때, 값)
Student t분포의 공분산: 일때,
이는 전반적인 feature vector의 분포를 나타내며, 각 semantic class에 속할 확률을 구하기 위해 softmax를 적용한다.
구현 단계
voxel 단위로, 평균 벡터 를 저장하며, 여기서 은 feature vector의 크기를 의미한다.
사후 확률에 대한 재귀 추정은 누적 TSDF 가중치 함수 Wt(x*)를 사용하여, 와 를 적용함으로써 단순화했고, feature vector의 각 요소가 독립이라고 가정하기 때문에, 공분산 행렬 는 대각 성분만 고려하면 된다.
추론 단계
각 voxel에서 posterior predictive로 얻은 클래스 확률 중 최댓값을 임곗값 과 비교하여, 불확실한 클래스 예측을 필터링한다.
마지막 단계는 voxel에 쌓인 geometry와 semantic posterior를 읽어내는 과정이다. closed/open-set semantics의 TSDF, weight, semantic parameters는 OpenVDB에 저장되고, visualizer 대신 NanoVDB 기반 GPU rendering으로 실시간 확인을 지원한다.
Rendering
closed & open-set semantics의 TSD 값, 가중치, semantic 파라미터들
→ voxel에 저장
⇒ OpenVDB 데이터 구조에 포함
voxel mesh 구성 → visualizer(e.g. Rviz) (❌)
camera viewpoint → NanoVDB (✅, real-time, use GPU)
Evidence: runtime/memory/accuracy를 어떻게 검증했나
Evaluation은 정확도만 보는 실험이 아니라, mobile robot에서 실제로 돌릴 수 있는지(runtime/memory/rendering)를 함께 검증한다.
closed-set Bayesian baseline 대비 FPS 향상, non-Bayesian 도 Voxfield/SNI-SLAM보다 빠름.
OpenVDB가 전체 map bounds를 미리 dense allocation하지 않아 CPU+GPU memory 사용량 감소.
SceneNet에서는 SEE-CSOM과 비슷하고 KITTI에서는 가 baseline을 상회.
CLIP 512-D feature를 Normal-Inverse-Gamma update로 통합해 expressiveness를 확보.
VDBFusion과 같은 TSDF update를 써서 geometric accuracy는 비슷한 수준 유지.
Jetson Orin 4GB에서 SceneNet indoor closed-set mapping을 약 6.12 FPS로 수행.
실험을 읽을 때는 SLIM-VDB가 모든 지표에서 절대적으로 최고라는 주장보다, semantic mapping을 실제 로봇 시스템에 올릴 때 생기는 병목을 얼마나 줄였는지에 초점을 두는 편이 좋다. 따라서 runtime과 memory는 단순 부가 지표가 아니라 이 논문의 핵심 주장이고, semantic/geometric accuracy는 효율화를 하면서도 map 품질이 무너지지 않았는지 확인하는 안전장치에 가깝다.
논문에서 글머리로 나열된 실험 조건은 평가 재현성과 fairness를 확인하는 체크포인트로 묶어 읽는다.
| 체크포인트 | 설정 | 읽는 포인트 |
|---|---|---|
| Hardware | Intel Xeon W-2245 CPU, NVIDIA RTX 3090 32GB | 주요 benchmark는 desktop GPU 환경에서 측정 |
| Resolution | KITTI 10cm/voxel, SceneNet closed-set 5cm/voxel, open-set 10cm/voxel | open-set은 LatentBKI memory 한계 때문에 해상도 조건을 확인해야 함 |
| Baselines | ConvBKI, SEE-CSOM, Voxfield Panmap, SNI-SLAM, LatentBKI | Bayesian / non-Bayesian / open-set 계열을 분리해 비교 |
| Metrics | FPS, CPU+GPU memory, mIoU, Chamfer distance, rendering time | 정확도보다 runtime-memory-accuracy 균형을 보는 평가 |
| Implementation | C++ 기반 평가 | mapping runtime 비교가 실제 구현 비용을 반영하는지 확인 |
중첩 글머리로 이어지는 데이터셋과 모델 조건은 아래 네 가지 항목을 먼저 확인하면 흐름이 끊기지 않는다.
| 구분 | 조건 | 주의점 |
|---|---|---|
| SceneNet | 실내 synthetic scene 12개를 사용하고 Semantic Segment Anything 기반 label을 활용 | closed-set은 5cm/voxel, open-set 비교는 10cm/voxel |
| SemanticKITTI | PolarSeg를 scenes 0-5로 fine-tuning하고 scenes 6-10의 첫 100 frame으로 평가 | 대규모 outdoor map에서 scalability와 geometry artifact 확인 |
| Bayesian baselines | ConvBKI, SEE-CSOM은 closed-set Dirichlet parameter update 비교군 | 확률적 update 품질과 runtime/memory 비용을 함께 봄 |
| Non-Bayesian baselines | Voxfield Panmap, SNI-SLAM은 consistent semantic prediction을 가정 | 공정 비교를 위해 Bayesian update를 제거한 도 함께 제시 |
Closed-Set Semantic mapping
closed-set 평가는 semantic accuracy만이 아니라, runtime과 memory까지 같이 보는 비교다.
| 구분 | 대상 | 읽는 포인트 |
|---|---|---|
| Bayesian baselines | ConvBKI, SEE-CSOM | Dirichlet parameter update를 쓰는 확률적 semantic fusion 비교군 |
| Non-Bayesian baselines | Voxfield Panmap, SNI-SLAM, | Bayesian update 비용을 제거했을 때 runtime/memory trade-off 확인 |
| Semantic datasets | SceneNet 12 scenes, SemanticKITTI scenes 6-10 first 100 frames | indoor synthetic과 outdoor driving scene을 나눠 일반성 확인 |
| Metrics | runtime, memory consumption, mIoU | 실시간 semantic mapping의 practical balance 평가 |
closed-set에서 runtime은 단일 프레임에서의 pre-processing, integration, visualization steps 시간을 포함한다.
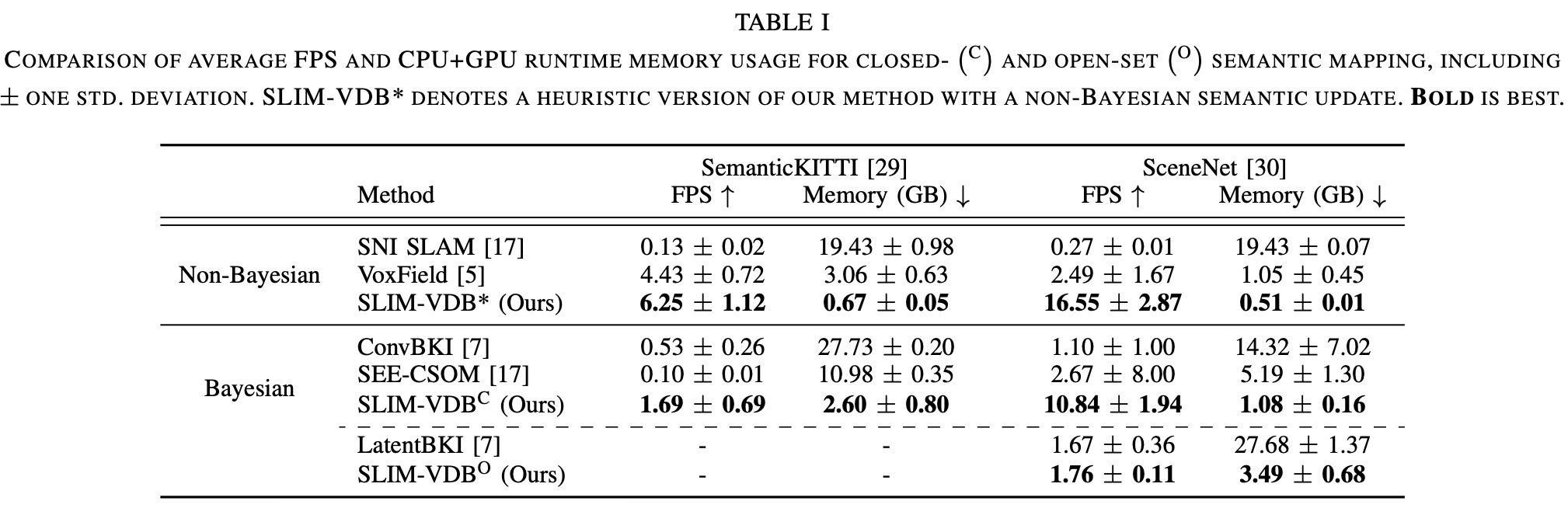
위 표는, Non-Bayesian 및 Bayesian 방법들에 대해 언급한 2개의 데이터셋을 통해 정량적 평가를 진행한 결과이다.
는 두 데이터셋 모두에서 낮은 메모리 소모량과 높은 FPS를 보였다.
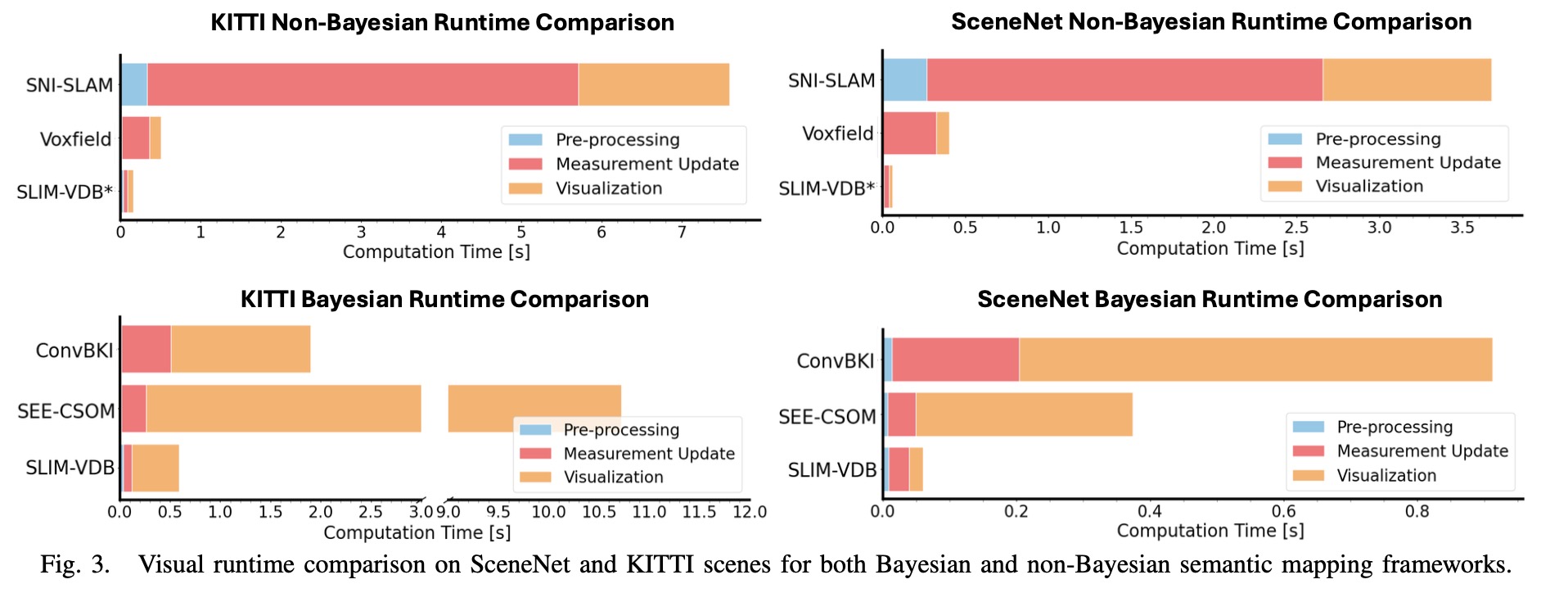
위 그래프는 동일한 모델군들의 runtime 비교 결과를 보여주며, 확실히 SLIM-VDB가 상대적으로 빠른 runtime을 보여준다.
시각화 비용 부분에서도 다른 baseline 대비 큰 향상을 보였지만,
이는 baseline의 시각화(mesh 형성 → Rviz 시각화)와 달리 단일 시점에 대한 렌더링만 수행하므로,
둘을 비교하는 것은 공정하지 않음(less comparable)
SLIM-VDB는 CPU + GPU를 이용하는 baseline 대비 낮은 메모리 소비를 가짐
→ OpenVDB 구조 때문
→ 맵 범위 내에서 모든 voxel을 초기화할 필요가 없음
반면에,
ConvBKI
- 재귀적으로 dense convolutional filter를 이용한 맵 업데이트 진행
→ GPU 메모리에 local map 올려야 함 (메모리 비용 증가)
ConvBKI, SEE-CSOM
- 미리 정적 global map 크기를 지정
Semantic prediction accuracy는 closed-set semantic fusion이 실제 label 품질을 유지하는지 확인하는 구간이다.
| 항목 | 설정 | 읽는 포인트 |
|---|---|---|
| Metric | mIoU | class-wise segmentation 품질을 평균 비교 |
| SceneNet | 임의 12개 scene | synthetic indoor scene에서 semantic consistency 확인 |
| SemanticKITTI | 임의 5개 scene | outdoor driving scene에서 scalability와 robustness 확인 |
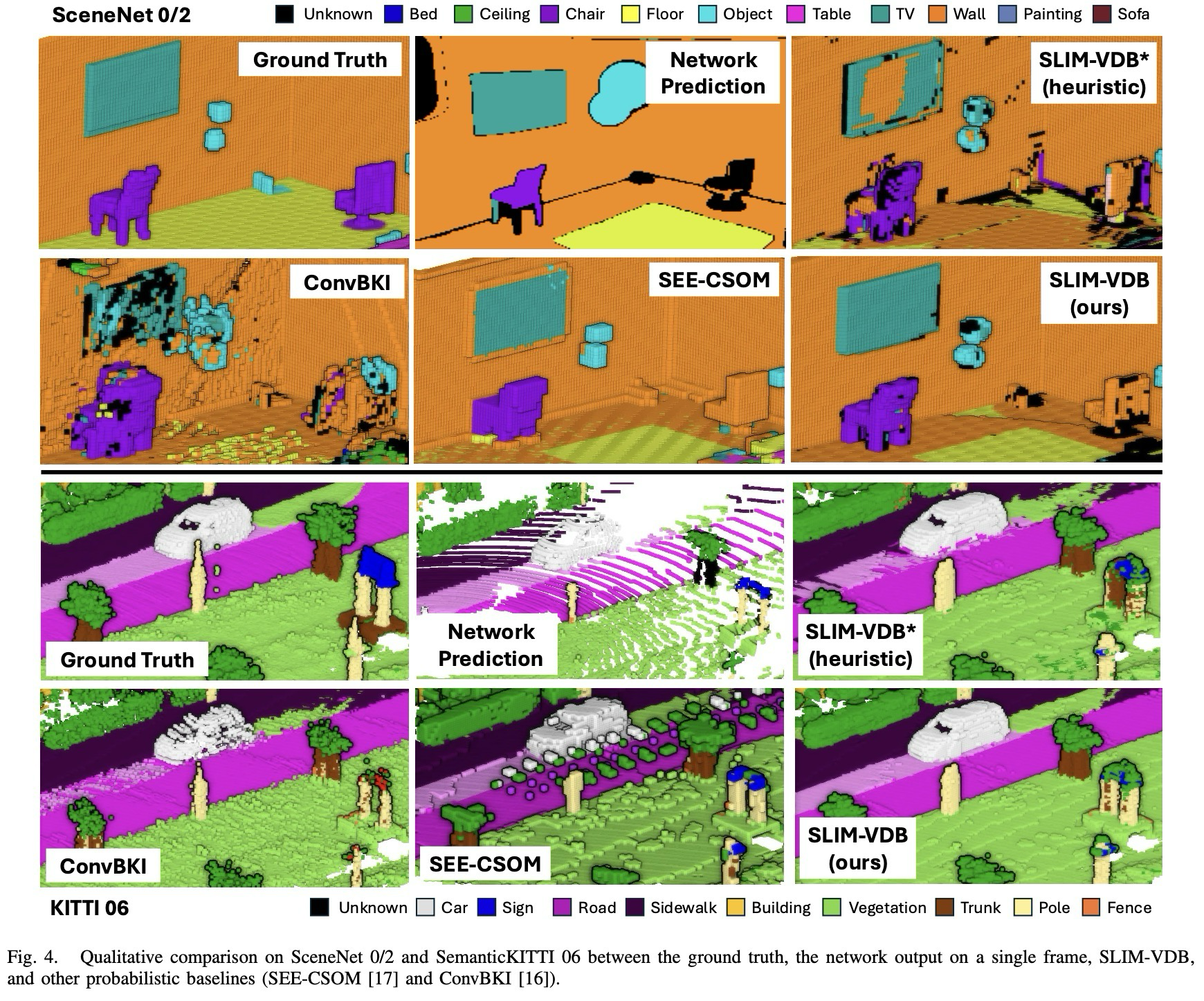
위 정성적 결과를 보면 SceneNet 결과에서는 SEE-CSOM과 가 비교적 높은 성능을 보였고, 두 모델 다 ConvBKI를 능가하는 성능을 보여준다.
하지만 아래의 SemanticKITTI 결과에서는 가 다른 baseline 모델들 대비 더 높은 성능을 보였고, 특히 SEE-CSOM은 대규모 map에 대해 기하학적 오류를 보인다.
(참고로 voxel 기반 비교에서는, 기하학적 정확도가 높을수록 유리하며, 실제로 없는 voxel을 채워 넣을 경우 페널티를 부과함)
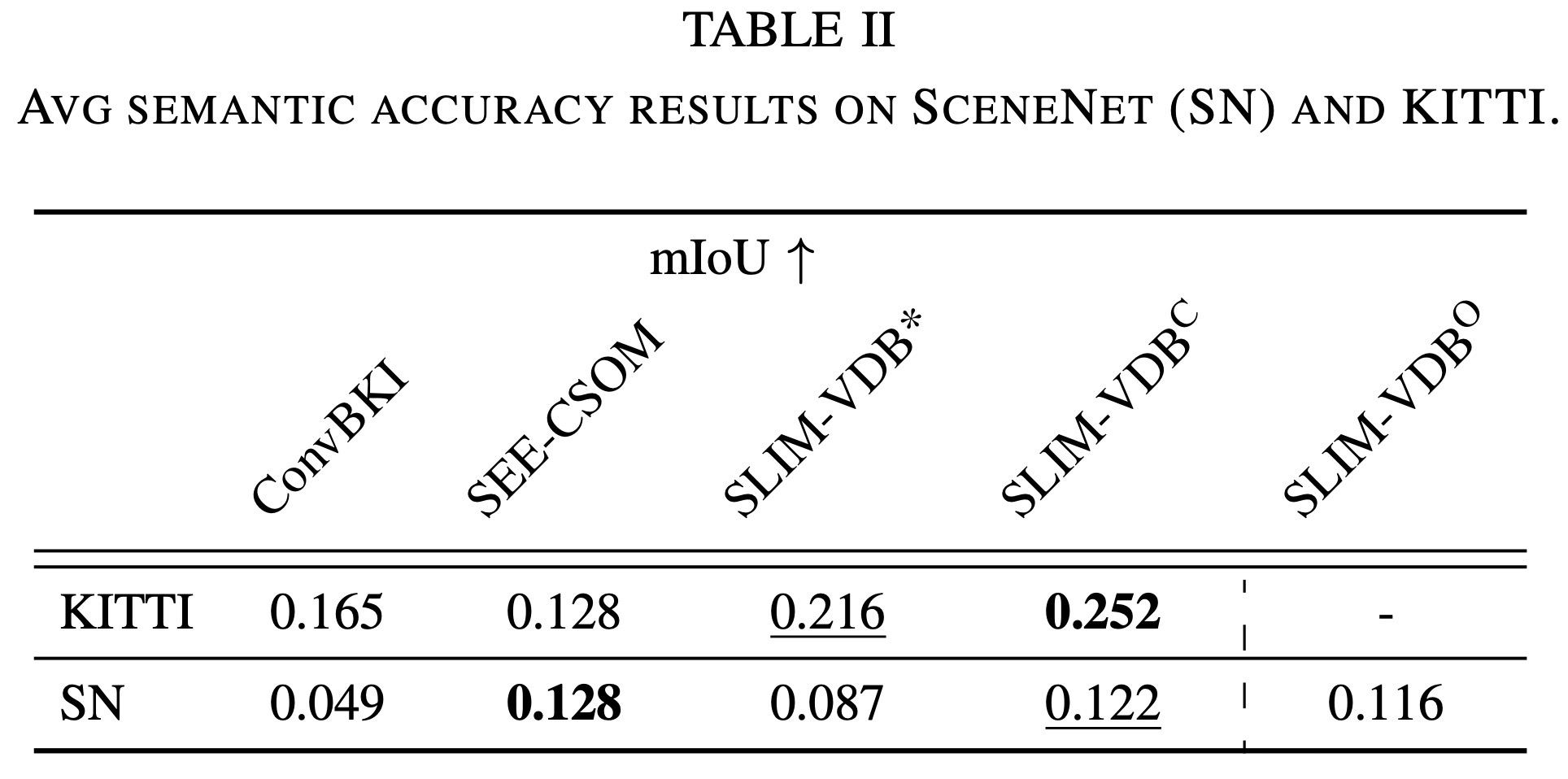
위 표는 의 semantic 예측 정확도를 보여주며,
KITTI 결과에서는 가 다른 baseline 모델들 대비 더 높은 성능을 보였고,
SceneNet 결과에서는 정성적 결과와 마찬가지로 SEE-CSOM의 정확도가 가장 높았고, 다음으로 가 뒤를 이었다.
Open-Set Semantic mapping
공정한 평가를 위해, 기존 closed-set에서 이용했던 open-set text labels를 그대로 사용
+ Contrastive Language-Image Pre-training (CLIP)을 통해 512차원으로 임베딩
→ 매 시간마다 Normal Inverse Gamma update를 통해 volume에 통합됨
open-set에서 runtime은 SceneNet scene의 300 프레임에 대해, visualization을 제외한 preprocessing과 integration 시간을 포함한다.
→ visualization을 제외한 이유: 비교군인 LatentBKI가 실시간 시각화를 지원하지 않기 때문
Table I 기준으로 보면 는 baseline인 LatentBKI보다 메모리 소모량이 확연히 적으며, 이는 비교군인 LatentBKI의 neural implicit representation로 인한 극심한 GPU 소모 때문이다.
위 표를 보면 의 semantic 예측 정확도가 나 SEE-CSOM 대비 낮은 정확도를 보이고 있었지만, 는 open-set semantics의 표현력(expressiveness)을 눈여겨 보는 이용자들에게 유용한 선택지가 된다. (아래 쿼리 결과 참고)

위 그림은 “Sit”이라는 텍스트와 유사한 특징 공간에 대해 voxel을 겹쳐보이게 한 결과를 보여주며, 이는 CLIP 임베딩과 유사한 기능이라고 볼 수 있다. (유사도는 코사인 유사도를 이용했다)
Geometry Mapping Accuracy
기하 정확도는 semantic fusion이 붙어도 TSDF reconstruction 품질이 크게 무너지지 않는지 확인하는 구간이다.
| 항목 | 설정 | 해석 포인트 |
|---|---|---|
| Metric | L2 Chamfer distance | 재구성된 surface와 ground truth 사이 거리 비교 |
| SceneNet | 선별 trajectory 기반 map 평가 | SEE-CSOM보다 약간 낮지만 baseline 대비 competitive |
| SemanticKITTI | outdoor scene의 large-scale map 평가 | boxy object나 noisy extra voxel이 생기는 baseline과 비교 |
미리 선별된 SceneNet trajectories를 기반으로 만들어진 맵에 대해 L2 Chamfer distance를 적용하여 매핑 정확도를 구했다.
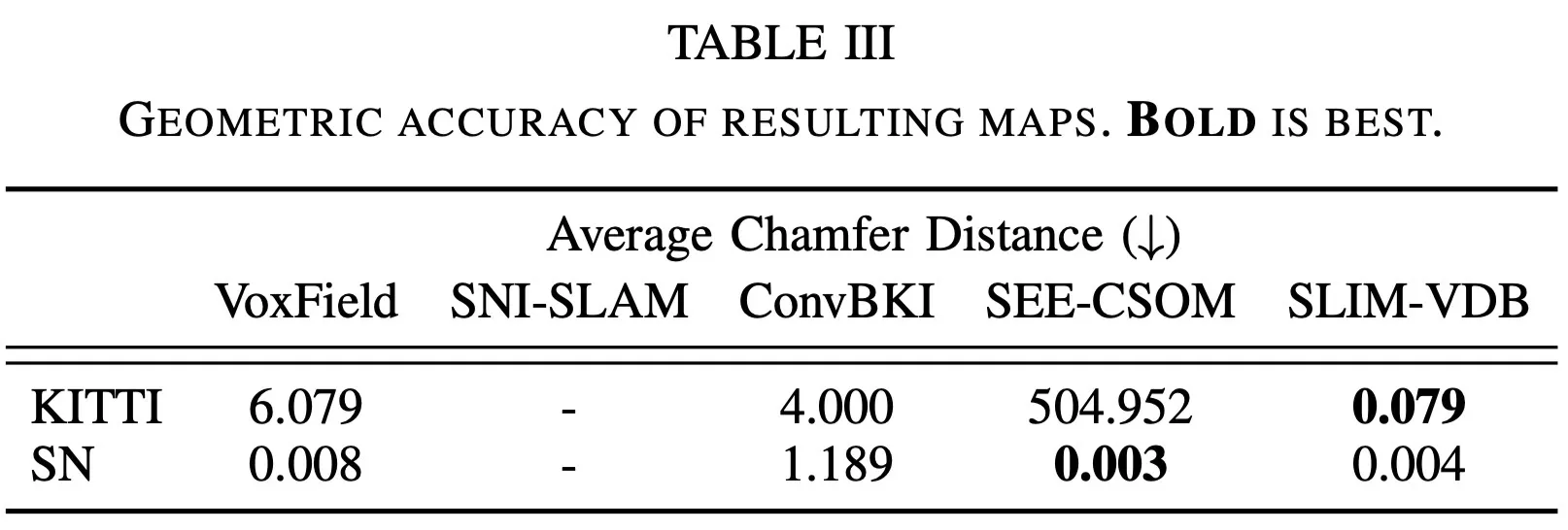
기하 정확도 표는 semantic fusion을 붙인 뒤에도 TSDF reconstruction 품질이 크게 무너지지 않는지 확인하는 근거다.
SEE-CSOM보다 약간 낮지만, sparse VDB 기반 semantic mapping으로 competitive reconstruction 유지.
large-scale outdoor map에서 baseline 대비 더 좋은 결과를 보이며 noisy extra voxel을 줄임.
- SEE-CSOM: 실제 scene에 없는 boxy object 생성
- ConvBKI: noisy depth에서 extra voxel 발생
최고 수치보다 semantic mapping을 붙였을 때 geometry가 유지되는지 확인하는 구간.
Rendering
| Compute | 10 images (691 x 256 px) | 10 images (1209 x 448 px) |
|---|---|---|
| CPU | 181.8 ms | 527.7 ms |
| GPU | 2.1 ms | 3.9 ms |
Mobile Robot Hardware
이 구간은 SLIM-VDB가 논문용 offline 결과가 아니라 작은 GPU 환경에서도 실시간 운용 가능성을 보였다는 근거다.
| 항목 | 설정 | 의미 |
|---|---|---|
| Hardware | NVIDIA Jetson Orin 4GB | mobile robot에 가까운 제한된 GPU 환경 |
| Scenario | SceneNet indoor, closed-set semantics, visualization 포함 | mapping과 viewing을 함께 수행 |
| Resolution | 5 cm / voxel | 실시간성과 map detail 사이의 practical setting |
| Result | 약 6.12 FPS | 실내 환경에서 real-time에 가까운 semantic mapping 가능성 |
Usage / Limits: mobile robot semantic mapping에는 언제 유용한가
SLIM-VDB는 OpenVDB를 semantic mapping의 저장소로 확장하고, closed-set과 open-set semantic fusion을 모두 확률적 update로 처리해야 하는 mobile robot mapping 상황에 잘 맞는다. 다만 실시간 3D map viewing은 아직 선택된 rendering viewpoint에 묶이고, fVDB 기반 연산과의 통합은 후속 보완 지점으로 남는다.
적용 조건은 memory/runtime 이득과 unified closed/open-set semantic fusion에 있다. 한계는 viewer와 VDB-grid 연산 확장성에서 확인하면 된다.
| 적합한 상황 | OpenVDB 기반 3D probabilistic semantic mapping으로 closed/open-set을 하나의 Bayesian framework에서 처리해야 하는 경우 |
|---|---|
| 한계 | 3D map의 real-time viewing은 미리 선택한 camera rendering viewpoint에 제한 |
| 후속 방향 | NanoVDB Viewer 동적 업데이트, fVDB 기반 convolution/splatting 도구와의 통합 |
느낀점
(진행중...)
Problem: why maintain semantic 3D maps in real time?
SLIM-VDB is a lightweight semantic mapping framework that combines OpenVDB-based sparse volumetric storage with probabilistic semantic fusion. The paper's main claim is that semantic mapping can be made more practical for robotics by reducing memory and integration cost while still keeping semantic and geometric accuracy comparable to stronger baselines.
The abstract positions SLIM-VDB around three ideas: OpenVDB as an efficient backend, Bayesian fusion as the uncertainty mechanism, and closed/open-set support in one package.
| Claim | Meaning | Reading Point |
|---|---|---|
| OpenVDB backend | Use a sparse hierarchical volumetric data structure for semantic mapping. | The backend is part of the contribution, not just an implementation detail. |
| Unified fusion | Support both fixed categories and open-language labels through Bayesian updates. | The paper connects two semantic regimes under one mapping framework. |
| Efficiency | Lower memory and integration time while maintaining comparable accuracy. | The target is real robotic deployment rather than accuracy alone. |
In other words, the paper treats real-time semantic mapping as both a storage-design problem and a probabilistic-update problem. OpenVDB keeps the map sparse enough to be practical, while Bayesian fusion decides how noisy semantic observations should become stable voxel-level beliefs over time.
Context: what are the geometry, semantics, and memory bottlenecks?
Robots need maps that carry both geometry and semantics. TSDF maps give useful dense surface reconstructions, but many TSDF-based methods have high memory requirements and struggle to run in real time. Semantic mapping adds another issue: frame-level segmentation can be inconsistent or flicker over time, so directly writing labels into the map is brittle.
The paper's answer is to combine OpenVDB with Bayesian semantic fusion. OpenVDB addresses the storage/query side with sparse volumetric allocation, while Bayesian updates accumulate uncertain semantic observations at the voxel level. The paper also emphasizes that modern mapping should handle both closed-set categories and open-language representations.
The introduction is easier to read by separating what the map must store, what kind of semantics it supports, and where prior methods remain limited.
| Thread | Meaning | Why it matters |
|---|---|---|
| World map | Geometry plus semantics, not just a surface model. | Supports scene understanding and robot tasks that query the map. |
| Closed-set | Predictions stay within predefined semantic classes. | Useful for simple world understanding, but limited for unseen categories and language queries. |
| Open-set | Language-linked feature representations can express concepts outside a fixed class list. | Requires uncertainty-aware feature fusion and memory-efficient storage. |
| Prior gap | Bayesian semantic mapping handles uncertainty, but often targets only one semantic scope or becomes computationally heavy. | Motivates a sparse OpenVDB backend with unified closed/open-set Bayesian updates. |
Gap: what is missing between OpenVDB and probabilistic semantics?
The related-work section is useful mainly as a positioning frame. Efficient geometric mapping contributes the sparse volumetric backbone, probabilistic semantic mapping contributes uncertainty handling, and open-dictionary methods motivate support for language-linked semantics.
View related-work background
This supplement groups prior work by the role it plays in the paper.
OctoMap, Voxblox, Voxfield Panmap, and VDBFusion establish efficient voxel/TSDF mapping.
ConvBKI and SEE-CSOM show why Bayesian semantic uncertainty matters.
VLMs and LatentBKI motivate language-linked semantic features but expose runtime and memory limits.
The implementation-oriented takeaway is that sparse VDB storage handles map scale, while NanoVDB supports GPU-friendly viewing.
| Item | Detail | Connection to SLIM-VDB |
|---|---|---|
| OpenVDB | Sparse hierarchical volumetric storage with efficient lookup, insertion, and deletion. | Stores TSDF values, weights, and semantic parameters near surfaces. |
| VDBFusion | Adapts OpenVDB to efficient robotic TSDF mapping. | Provides the geometric mapping reference that SLIM-VDB extends with semantics. |
| NanoVDB | GPU-friendly VDB representation. | Supports accelerated semantic TSDF rendering in the SLIM-VDB pipeline. |
SLIM-VDB is best read as a fusion of sparse volumetric storage and unified closed/open-set Bayesian semantics.
| Line of work | What it contributes | Remaining gap |
|---|---|---|
| OctoMap / Voxblox / VDBFusion | Efficient 3D geometric mapping and TSDF integration. | Semantic information is missing or limited. |
| ConvBKI / SEE-CSOM | Bayesian semantic fusion with uncertainty estimates. | Global scalability and memory/runtime can be expensive. |
| LatentBKI / VLMs | Open-dictionary mapping in language-image feature spaces. | Real-time operation and map scale are limited by GPU memory. |
Mechanism: how Bayesian semantics are built on sparse VDB
The system takes RGB-D or point-cloud input, obtains semantic predictions with an off-the-shelf segmentation model, projects them into a semantic point cloud, and updates an OpenVDB volume. The geometry side updates TSDF distance and voxel weight. The semantics side updates either closed-set categorical beliefs or open-set feature distributions.
The method is easiest to read as three coupled updates: geometry, closed-set semantics, and open-set semantics.
| Part | Update | Core idea |
|---|---|---|
| Surface reconstruction | TSDF distance and cumulative voxel weight. | Use OpenVDB DDA ray casting and truncated integration regions. |
| Closed-set fusion | Dirichlet parameters for categorical semantic classes. | Use Dirichlet-Categorical conjugacy for closed-form recursive updates. |
| Open-set fusion | Normal-Inverse-Gamma parameters for feature distributions. | Model VLM features as Gaussian observations with unknown mean and variance. |
| Rendering | Semantic TSDF visualization. | Use NanoVDB for GPU-accelerated rendering instead of publishing a full mesh. |
The important shift is that the map is not just a container for already-decided labels. Each new observation updates geometric and semantic state in the same sparse volume, so repeated measurements can refine both surface evidence and semantic belief instead of overwriting the map with one-frame predictions.
View Bayesian semantic updates
This supplement follows the same hierarchy as the Korean version: observation, geometry state, closed-set belief, open-set feature distribution, and rendering/query readout.
Attach semantic predictions to RGB-D or point-cloud input.
Update TSDF distance and cumulative voxel weight.
Use Dirichlet-Categorical conjugacy to update class belief.
Use Normal-Inverse-Gamma / Normal conjugacy for feature distributions.
Use posterior predictive distributions and NanoVDB rendering.
The notation is best read as a list of voxel states, not as isolated symbols.
| Part | State | Meaning |
|---|---|---|
| TSDF | Dt(x*),Wt(x*) | Signed distance and cumulative weight for each voxel. |
| Closed-set | α | Dirichlet parameter for categorical semantic classes. |
| Open-set | m,λ,ν,β | Normal-Inverse-Gamma parameters for feature mean and variance. |
| Query | Student-t predictive / cosine similarity | Read out open-set semantic evidence as class or text-query scores. |
The TSDF equations update geometric support. The Dirichlet update handles closed-set class evidence. The Normal-Inverse-Gamma update handles open-set feature uncertainty. Rendering is the final readout layer, not a separate mapping objective.
Evidence: how runtime, memory, and accuracy are tested
The experiments evaluate SLIM-VDB on SemanticKITTI and SceneNet. The paper measures runtime, memory, semantic prediction accuracy, geometric mapping accuracy, rendering speed, and feasibility on mobile robot hardware.
The main experimental story is not only that SLIM-VDB is accurate, but that it is much more deployable under runtime and memory constraints.
SLIM-VDB is faster than probabilistic baselines, and the heuristic is faster than non-probabilistic baselines.
OpenVDB avoids dense allocation over the entire map bounds, reducing CPU+GPU memory.
SceneNet is comparable to SEE-CSOM, while KITTI favors .
is close to the closed-set variant while enabling language-linked queries such as “sit.”
Geometric accuracy is comparable to VDBFusion because the TSDF update backbone is shared.
On a Jetson Orin 4GB setup, SLIM-VDB runs indoor closed-set mapping at about 6.12 FPS.
For this paper, runtime and memory are not secondary engineering details. They are part of the main evidence that the framework could be useful on robotic platforms, while the semantic and geometric metrics check whether that efficiency comes at the cost of map quality.
Geometry accuracy and hardware deployment are easier to read as separate checks: reconstruction quality and practical runtime on limited GPU hardware.
| Check | Setup | Reading Point |
|---|---|---|
| Geometry | L2 Chamfer distance on selected SceneNet trajectories and large-scale KITTI maps. | Semantic fusion should not break TSDF reconstruction quality. |
| Rendering | NanoVDB-based GPU rendering. | Viewing cost is part of deployment, but not fully comparable to mesh-based baselines. |
| Mobile hardware | Jetson Orin 4GB, SceneNet indoor closed-set mapping, 5 cm voxels. | Reports about 6.12 FPS, showing practical feasibility. |
Usage / Limits: when is it useful for mobile robot mapping?
SLIM-VDB is useful when a robot needs memory-efficient 3D probabilistic semantic mapping with both closed-set and open-set semantics. The main limitation is that real-time map viewing is tied to preselected camera rendering viewpoints, while dynamic NanoVDB updates and fVDB-based convolution/splatting remain follow-up directions.
Takeaway
(In progress...)
Comments