핵심 요약
WildPose는 MASt3R식 3D-aware feature, differentiable BA, edge-specific motion mask를 결합해 dynamic scene과 static scene 모두에서 안정적인 monocular pose estimation을 목표로 하는 프레임워크다.
이 논문은 in-the-wild pose estimation을 stronger 3D-aware pair feature와 edge-dependent motion mask가 differentiable BA를 함께 안정화하는 문제로 본다.
Unified Pose Estimator
dynamic, low-motion, static benchmark를 함께 겨냥하는 monocular pose estimator.
3D-aware BA Operator
DROID식 optimization loop 안에 MASt3R encoder feature를 넣어 frontend prior 강화.
Edge Motion Mask
pairwise motion mask로 특정 edge에서 outlier가 되는 dynamic region만 residual downweight.
Cross-regime Evidence
Wild-SLAM/Bonn/TUM dynamic, Sintel, TUM static, 7-Scenes, depth estimation, ablation으로 검증.
WildPose는 DROID-SLAM을 semantic segmentation 시스템으로 바꾸지 않으면서 static-scene 의존성을 줄이려는 시도로 읽으면 좋다. 핵심은 dynamic을 단순히 지우는 것이 아니라, optimizer가 더 강한 3D-aware pair evidence를 사용하게 만드는 데 있다.
class prior 기반 제거
known class에는 유용하지만 unseen movable object와 segmentation failure에 취약.
motion/rendering cue
semantic prior는 줄이지만 synthetic gap, low-capacity motion decoding, online mapping cost가 남음.
feature-rich optimizer
MASt3R의 3D-aware feature를 differentiable BA loop에 넣고 edge별 motion mask를 학습.
논문 상세 정리
아래부터는 기존 논문 내용을 최대한 담은 상세 해석이다. 핵심 흐름에서 벗어나는 related work, 학습 세부 조건, baseline 조건 메모는 접어두었다.
Problem: static-world 가정은 in-the-wild pose를 흔든다
WildPose의 출발점은 visual SLAM/SfM이 대체로 static world assumption에 기대고 있다는 점이다. 실제 영상에는 움직이는 사람, 이동하는 물체, 낮은 ego-motion, 조명 변화가 섞이는데, 이런 요소는 pose graph의 residual을 키우고 BA가 camera motion과 object motion을 혼동하게 만든다.
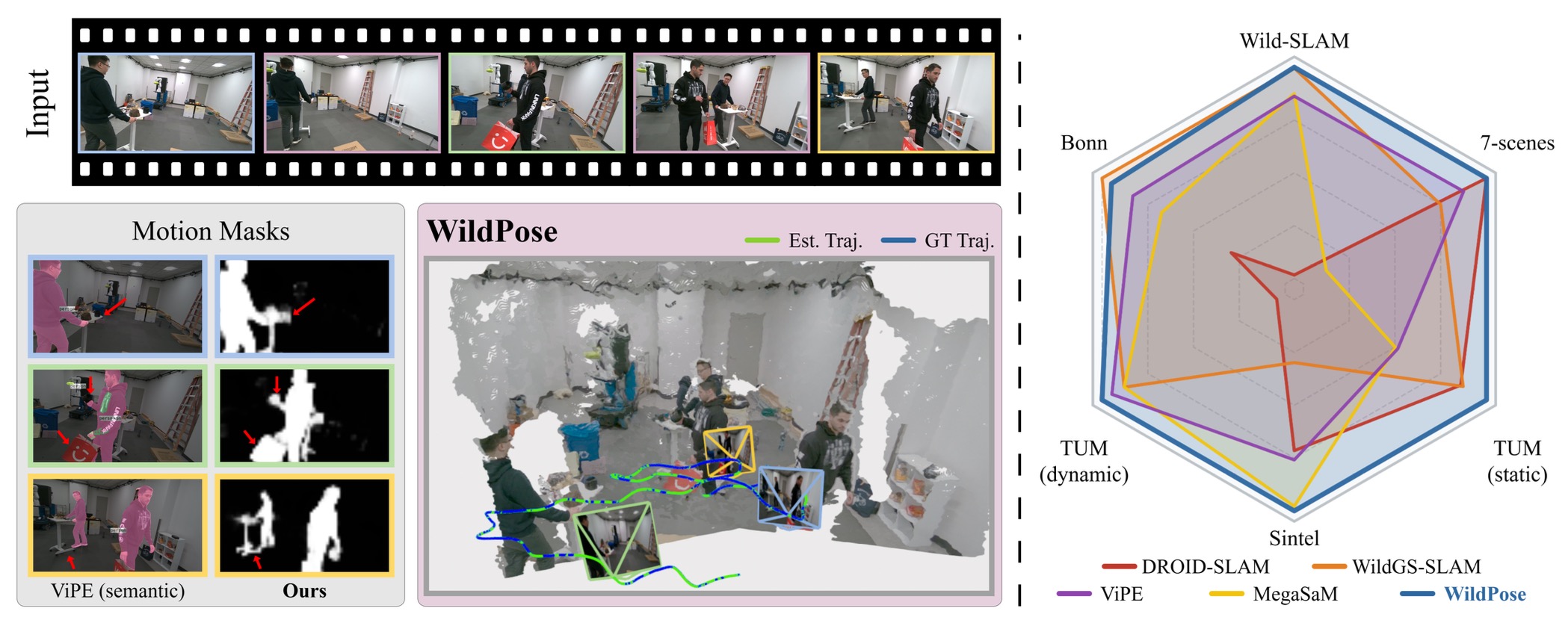
논문은 dynamic scene만 잘하는 특수 방법보다 dynamic과 static을 모두 다루는 unified pose estimator를 목표로 둔다.
기존 SLAM/SfM은 정적 장면의 reprojection consistency에 의존.
moving object의 true flow가 ego-motion flow와 달라 BA residual 증가.
semantic prior, online mapping, synthetic motion decoding은 각각 일반화/속도/용량 한계 보유.
3D-aware feature와 edge mask를 BA에 직접 연결.
문제 제기와 실험 결과는 모두 strong frontend + robust optimization의 결합이 필요하다는 주장으로 이어진다.
| 문제 축 | 기존 접근의 병목 | WildPose의 관점 |
|---|---|---|
| Dynamic scenes | semantic prior나 mask 품질에 민감 | edge-dependent learned motion mask |
| Static scenes | dynamic 전용 method는 static-only input에서 성능 저하 가능 | static/dynamic mixed curriculum |
| Long trajectory | local VO만으로 drift 누적 | loop closure + periodic/final global BA |
Related Work 맥락 자세히 보기
Related Work는 feed-forward reconstruction, visual SLAM, dynamic-scene pose estimation의 세 흐름으로 나누면 WildPose의 위치가 명확해진다.
| 흐름 | 강점 | WildPose가 보는 한계 |
|---|---|---|
| Feed-forward 3D reconstruction | DUSt3R/MASt3R/VGGT 계열의 robust 3D prior | long sequence와 정밀 pose estimation은 optimizer 보강 필요 |
| Differentiable SLAM | DROID-SLAM의 learnable update + differentiable BA | static training과 scratch-trained CNN encoder로 dynamic input에 취약 |
| Dynamic pose estimation | semantic/geometric/motion cue로 dynamic object 처리 | novel object, segmentation failure, synthetic-domain gap, online cost가 남음 |
Mechanism: MASt3R feature와 motion mask를 BA에 어떻게 넣나
방법론의 핵심은 DROID-SLAM의 differentiable BA pipeline을 유지하되, frontend feature와 residual weighting을 바꾸는 것이다. WildPose는 MASt3R encoder feature로 update operator를 강화하고, edge별 motion mask \( \hat{M}_{i,j} \)를 이용해 dynamic pixel의 reprojection residual을 낮춘다.
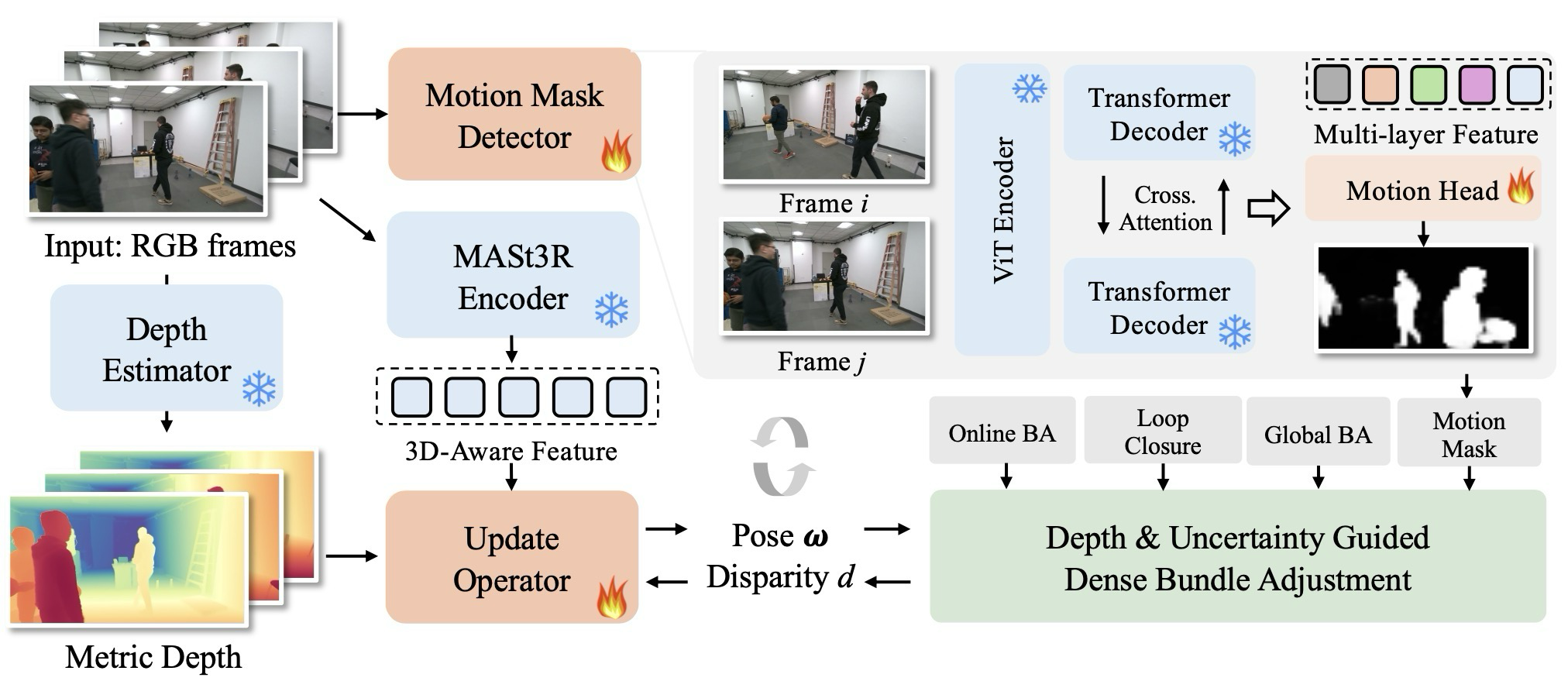
Method는 DROID-style BA state, MASt3R frontend, edge motion detector, curriculum training, online inference로 읽으면 된다.
| 구간 | 무엇을 담당하나 | 핵심 장치 |
|---|---|---|
| State | keyframe pose와 downsampled disparity 공동 최적화 | \( \hat{\omega}_i \), \( \hat{d}_i \), frame graph \( \mathcal{G} \) |
| Update operator | predicted flow, confidence, damping, upsampling mask 반복 갱신 | ConvGRU + correlation + MASt3R feature |
| Motion detector | edge별 dynamic residual downweight | MASt3R multi-level correspondence token + DPT-style fusion |
| Inference | online VO, metric depth initialization, loop/global BA | Moge2 depth prior + masked BA |
WildPose가 강조하는 선택은 dynamic을 semantic class로 지우지 않고, BA edge에서 residual weight로 다루는 것이다.
pointmap precision과 2D correspondence pretraining이 flow/BA update와 잘 맞음.
object가 특정 frame pair에서만 움직이면 그 edge에서만 outlier가 됨.
local sliding window만으로 생기는 long-sequence scale/pose drift를 보정.
각 keyframe의 state는 camera pose \( \hat{\omega}_i\in SE(3) \)와 downsampled disparity \( \hat{d}_i \)다. Edge \( (i,j)\in\mathcal{G} \)에서 geometry-induced optical flow는 projection/back-projection으로 계산된다.
Eq. (1)-(2)는 WildPose의 출발점이 되는 DROID-SLAM notation이다. 핵심은 update operator가 residual을 줄이는 방향으로 flow/confidence를 갱신하고, BA가 그 값을 pose/disparity 최적화에 쓰는 구조다.
| Notation | 의미 | 읽는 포인트 |
|---|---|---|
| \( \hat{\omega}_i \), \( \hat{d}_i \) | keyframe \(i\)의 camera pose와 downsampled disparity | BA가 직접 최적화하는 state. |
| \( \mathcal{G} \), \( (i,j) \) | 관측 overlap이 있는 keyframe들을 잇는 frame graph와 edge | 모든 수식은 frame pair edge 단위로 residual을 쌓음. |
| \( \Pi_c \), \( p_i \) | pinhole camera projection과 reference frame \(i\)의 pixel location | 2D pixel을 3D로 back-project한 뒤 다시 frame \(j\)로 project. |
| \( \tilde{f}^{t}_{i,j} \) | 현재 pose/disparity가 유도하는 geometry-induced optical flow | static scene이라면 predicted flow와 가까워야 하는 기준 flow. |
| \( \hat{f}^{t}_{i,j} \) | update operator가 예측하는 optical flow, 원문 기준 \( \mathbb{R}^{H/8 \times W/8 \times 2} \) | BA objective에서 geometry-induced flow와 비교되는 learned flow. |
| \( \hat{w}^{t}_{i,j} \) | predicted flow confidence, 원문 기준 \( \mathbb{R}^{H/8 \times W/8 \times 2} \) | \( \Sigma_{ij}^{-1}=\operatorname{diag}(\hat{w}_{i,j}) \)로 BA weight가 됨. |
| \( r^{t}_{i,j} \) | \( r^{t}_{i,j}=\hat{f}^{t}_{i,j}-\tilde{f}^{t}_{i,j} \) | 현재 learned flow와 geometry flow의 차이. update operator가 다음 갱신을 결정하는 핵심 residual. |
| \( \hat{\eta}^{t} \), \( \hat{u}^{t} \) | BA 안정화를 위한 damping factor와 disparity upsampling mask | pose/disparity update가 과격해지지 않도록 보조하는 내부 변수. |
WildPose는 DROID의 scratch CNN encoder를 그대로 쓰지 않고, MASt3R의 pretrained ViT encoder feature를 adapter module로 변환해 ConvGRU가 사용할 local feature map과 global context로 넣는다. decoder token 전체를 쓰지 않는 이유는 ConvGRU와 직접 결합하면 학습/추론 비용이 커지기 때문이다.
dynamic pixel의 true optical flow는 ego-motion뿐 아니라 object self-motion을 포함한다. 논문은 이를 \(X_{i,j}(p_i)\)로 표현하고, static BA objective가 이 residual을 그대로 맞추려 하면 pose와 disparity가 잘못 업데이트된다고 설명한다.
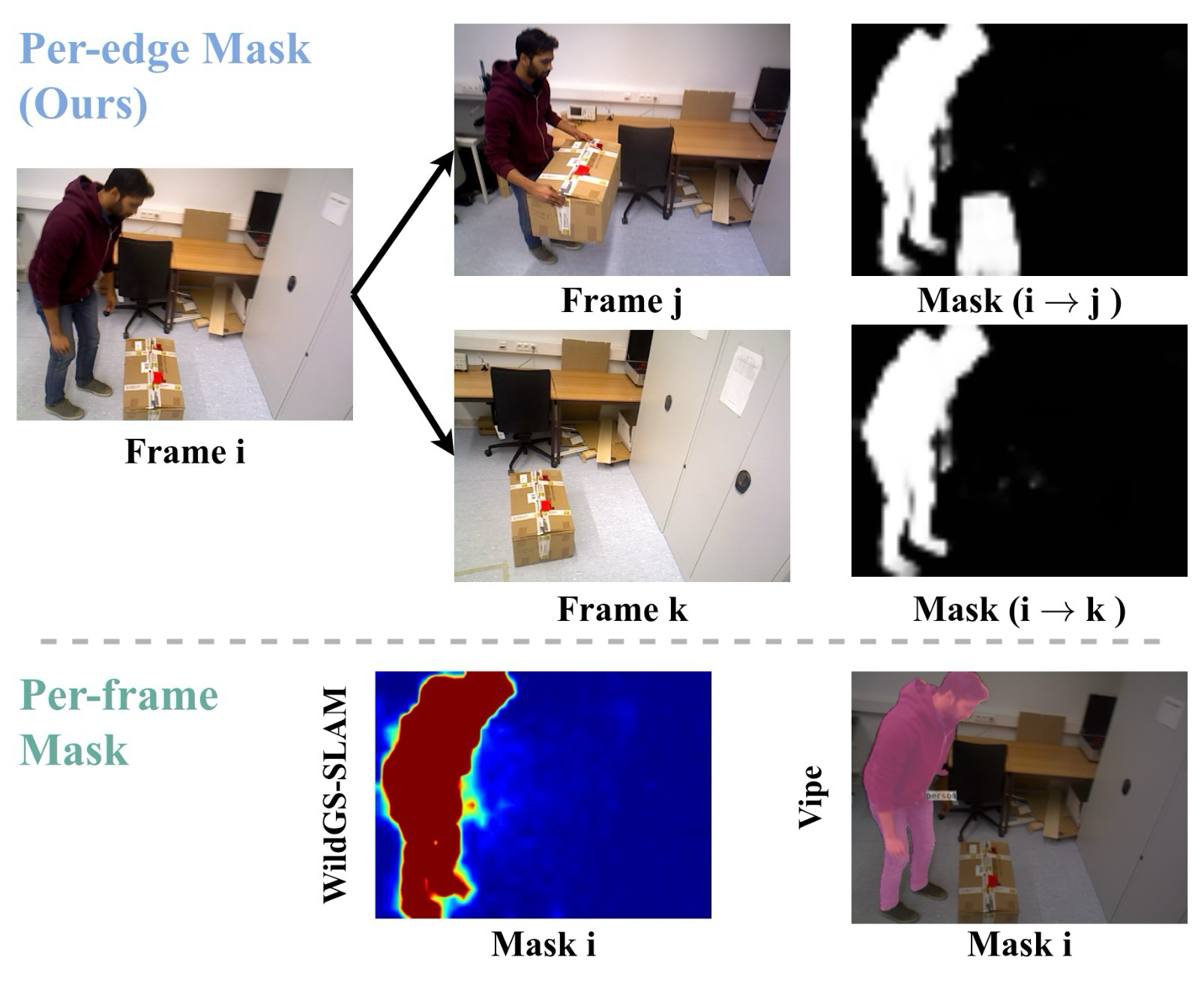
Training curriculum / loss notation 보기
Training은 update operator와 motion detector를 한 번에 섞지 않고 단계적으로 학습한다. 먼저 static data로 ego-motion 기반 pairwise flow를 배우고, 이후 dynamic data와 mask를 넣어 BA robustness를 높이며, 마지막에는 frozen update operator와 BA에 predicted mask를 연결한다.
Training loss term 세부 보기
Eq. (3)은 DROID-SLAM식 update-operator 학습 손실을 따르고, Eq. (4)는 motion detector를 붙이면서 mask supervision을 추가한다.
| 항 | 담당하는 신호 | WildPose에서의 의미 |
|---|---|---|
| \( \mathcal{L}_{\mathrm{cam}} \) | camera pose supervision | update operator가 pose를 안정적으로 보정하도록 하는 기본 pose loss. |
| \( \mathcal{L}_{\mathrm{flow}} \) | geometry-induced flow와 ground-truth flow 비교 | static ego-motion으로 설명되는 flow를 먼저 학습해 BA update의 기준을 만든다. |
| \( \mathcal{L}_{\mathrm{res}} \) | geometry-induced flow \( \tilde{f} \)와 operator-predicted flow \( \hat{f} \)의 residual supervise | ConvGRU update가 반복 단계에서 residual을 줄이도록 학습한다. |
| \( \mathcal{L}_{\mathrm{BCE}} \) | motion mask binary supervision | dynamic residual을 BA에서 낮은 weight로 처리하기 위한 edge별 mask 학습 항. |
Inference는 online visual odometry처럼 동작한다. 새 keyframe의 disparity는 Moge2 metric depth \(D_i\)로 초기화하고, co-visible keyframe과 edge를 만든 뒤 edge별 mask를 예측한다.
WildPose가 DROID-SLAM에서 바꾸는 부분은 Eq. (5)의 weight와 depth prior다. dynamic residual은 mask로 낮추고, monocular scale은 metric depth로 붙잡는다.
| Notation | 의미 | 역할 |
|---|---|---|
| \( X_{i,j}(p_i) \) | frame \(i\)에서 \(j\)로 갈 때 moving point가 가진 3D displacement | dynamic pixel의 true flow가 ego-motion flow와 달라지는 원인. |
| \( \hat{M}_{i,j} \) | edge \( (i,j) \)별 predicted motion mask, 원문 기준 \( \mathbb{R}^{H/8 \times W/8} \) | 특정 frame pair에서 outlier가 되는 dynamic region만 downweight. |
| \( \bar{\Sigma}_{ij} \) | motion mask가 들어간 BA covariance/weight | \( \hat{w}_{i,j}\hat{M}_{i,j} \)로 confidence와 motion filtering을 함께 반영. |
| \( D_i \), \( \lambda \) | Moge2 metric depth prior와 regularization weight | online BA에서 disparity가 metric depth와 크게 어긋나지 않도록 보조. |
Training / inference 세부 조건 보기
재현이나 결과 해석에 필요한 조건을 Data, Training, Inference로 나누어 정리한다.
| 항목 | 내용 |
|---|---|
| Training data | TartanAir V2, TartanGround, Dynamic Replica, OmniWorld-Game, Kubric-generated static/dynamic sequence |
| Kubric motion | linear translation, pure rotation, target-locked motion 보강 |
| 항목 | 내용 |
|---|---|
| Update operator | static pretraining 200K iteration, static+dynamic finetuning 100K iteration |
| Motion detector | frozen update operator + differentiable BA와 결합해 15K iteration 학습 |
| 항목 | 내용 |
|---|---|
| Loop closure | temporal interval과 co-visibility 조건을 만족하는 past keyframe과 graph 구성 후 BA 수행 |
Evidence: 어떤 task에서 검증했나
평가는 동적 환경 pose estimation, static/low-motion robustness, downstream depth, ablation의 네 가지 claim으로 나뉜다.
평가는 monocular SLAM pipeline의 표준처럼 Sim(3) Umeyama alignment 후 ATE RMSE를 계산한다.
| 평가 축 | Dataset / metric | 의미 |
|---|---|---|
| Dynamic pose | Wild-SLAM MoCap, Bonn RGB-D Dynamic, TUM dynamic / ATE RMSE | moving distractor에서 pose 안정성 검증 |
| Low-motion / static | Sintel, TUM static, 7-Scenes / ATE RMSE | dynamic 대응이 static 성능을 해치지 않는지 확인 |
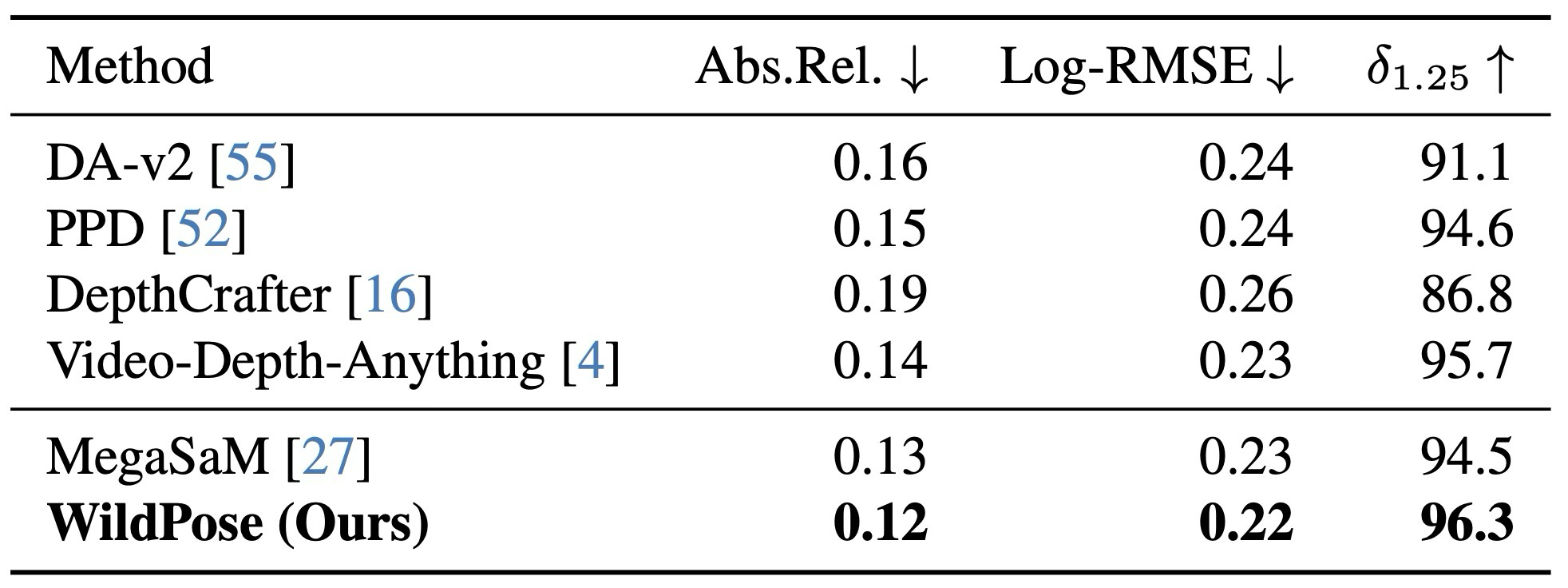
| Depth downstream | Bonn Dynamic / Abs.Rel., Log-RMSE, \( \delta_{1.25} \) | pose와 mask가 long-video depth optimization에 주는 영향 |
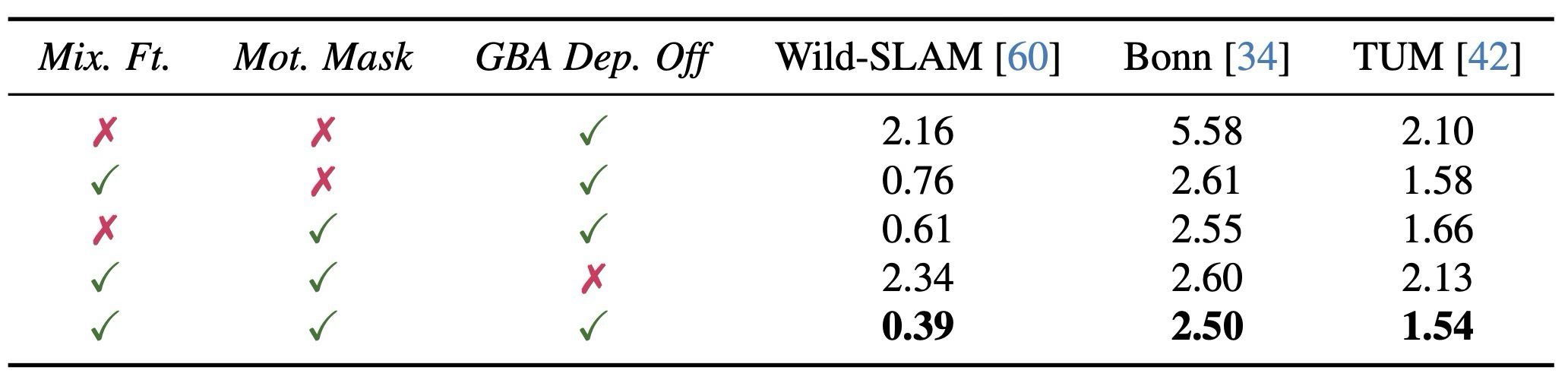
| Ablation | Mix. Ft., Motion Mask, GBA Depth Off | 각 design choice의 기여 분리 |
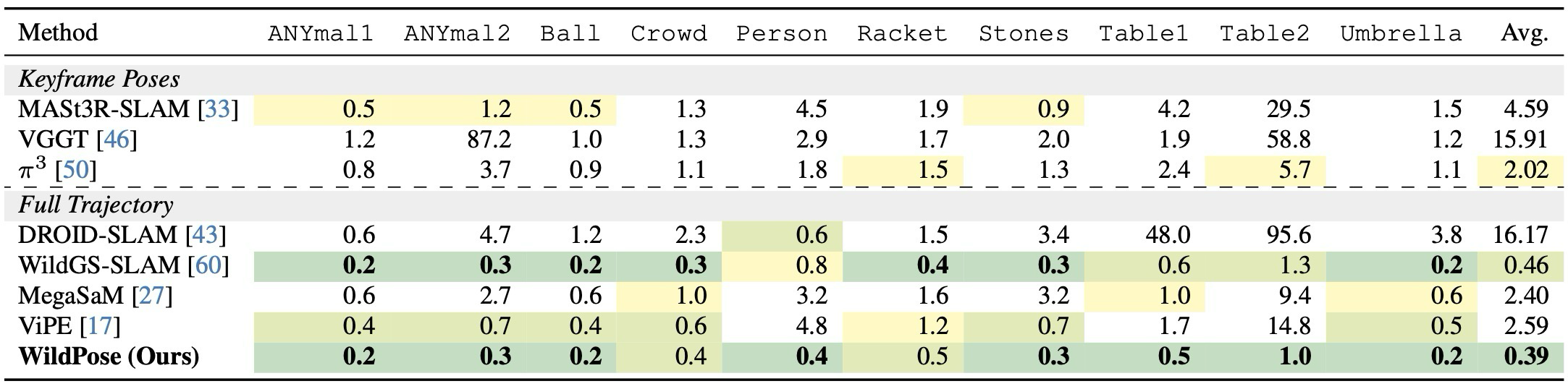
주요 결과: Wild-SLAM MoCap에서는 평균 0.39cm로 가장 낮은 ATE를 보이고, TUM dynamic에서도 best average를 달성한다. Bonn에서는 WildGS-SLAM이 illumination handling에서 약간 앞서지만 WildPose는 전체적으로 competitive하다.
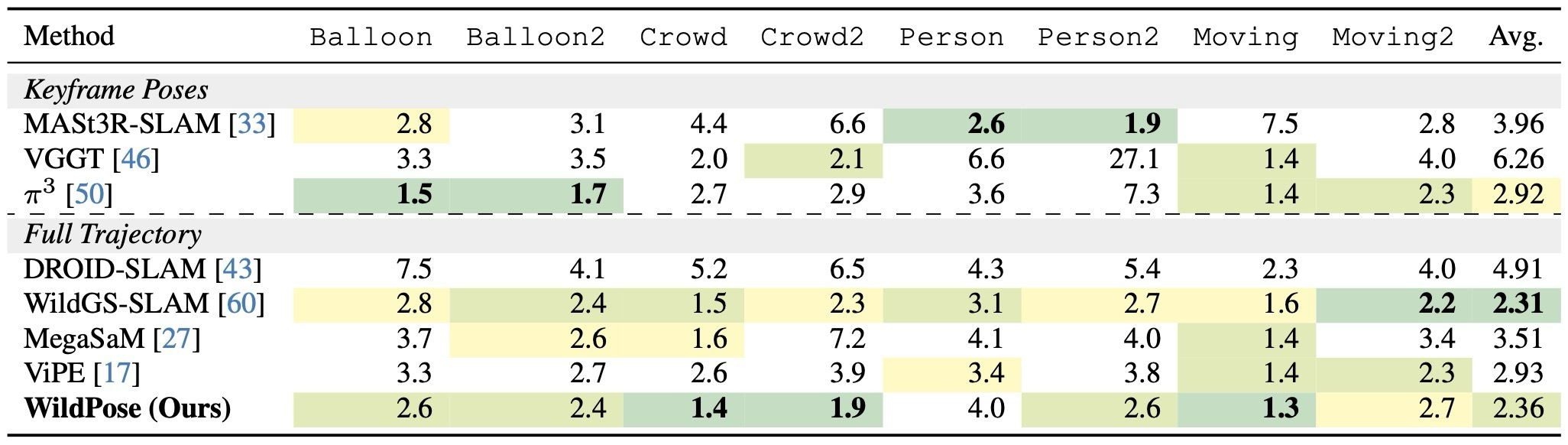
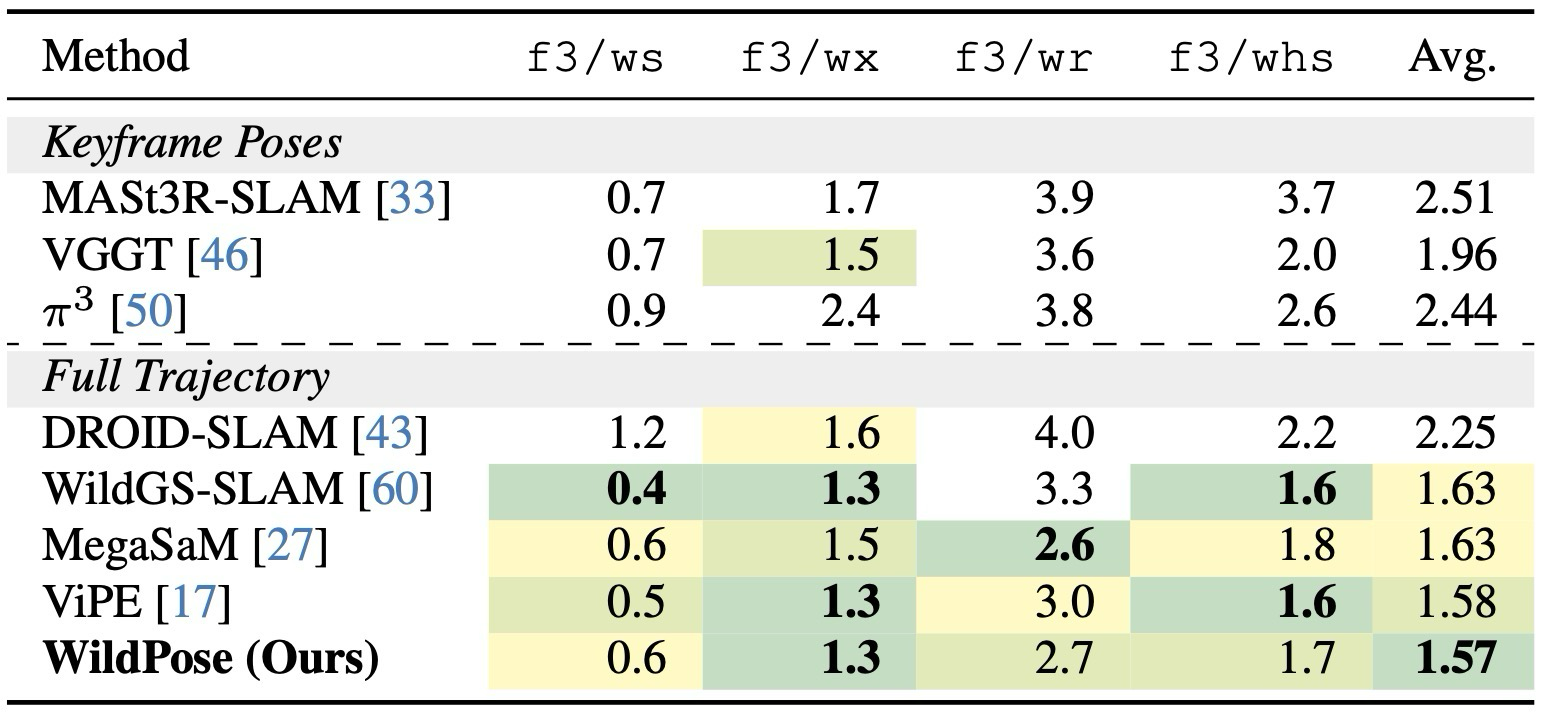
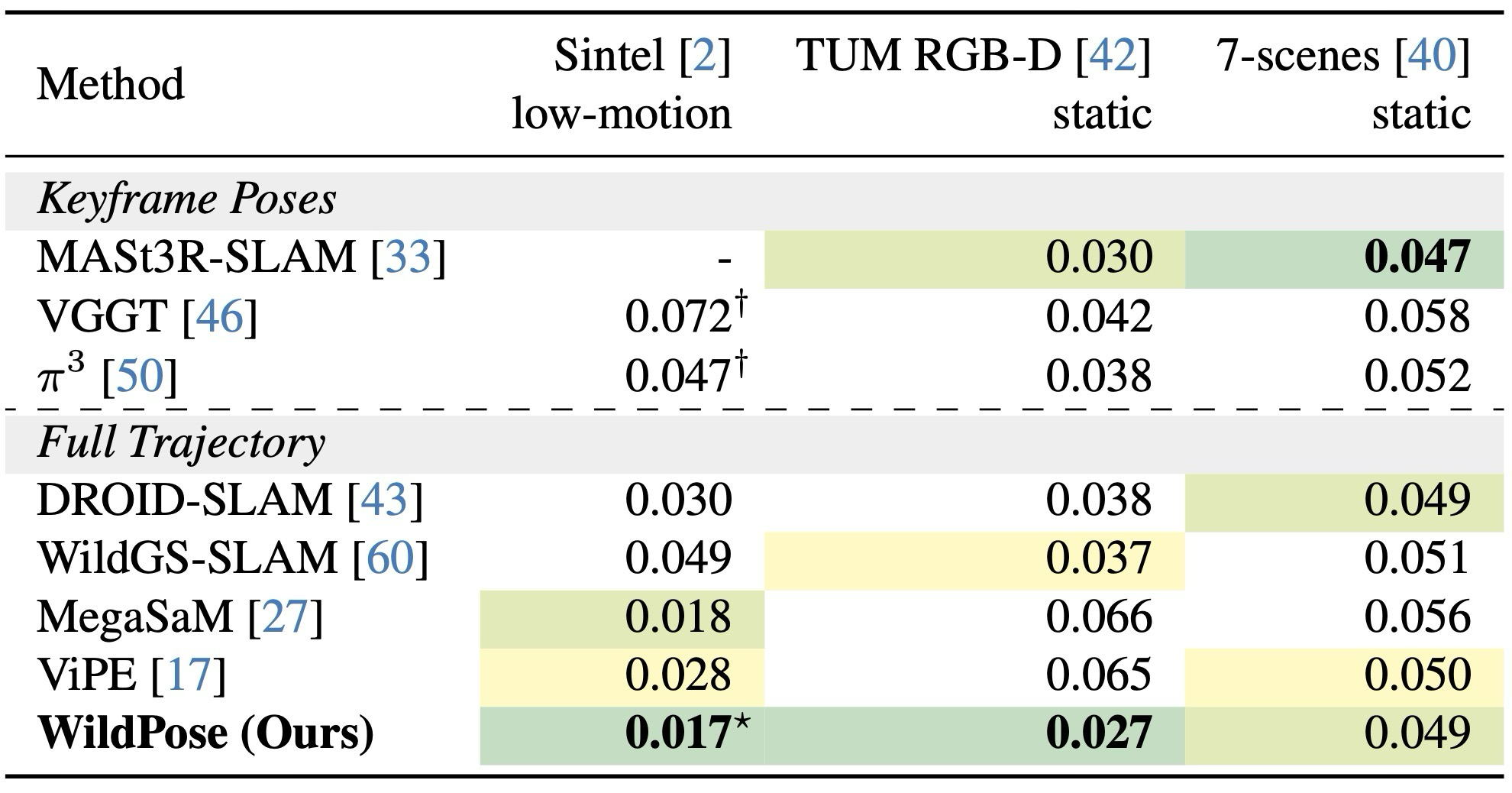
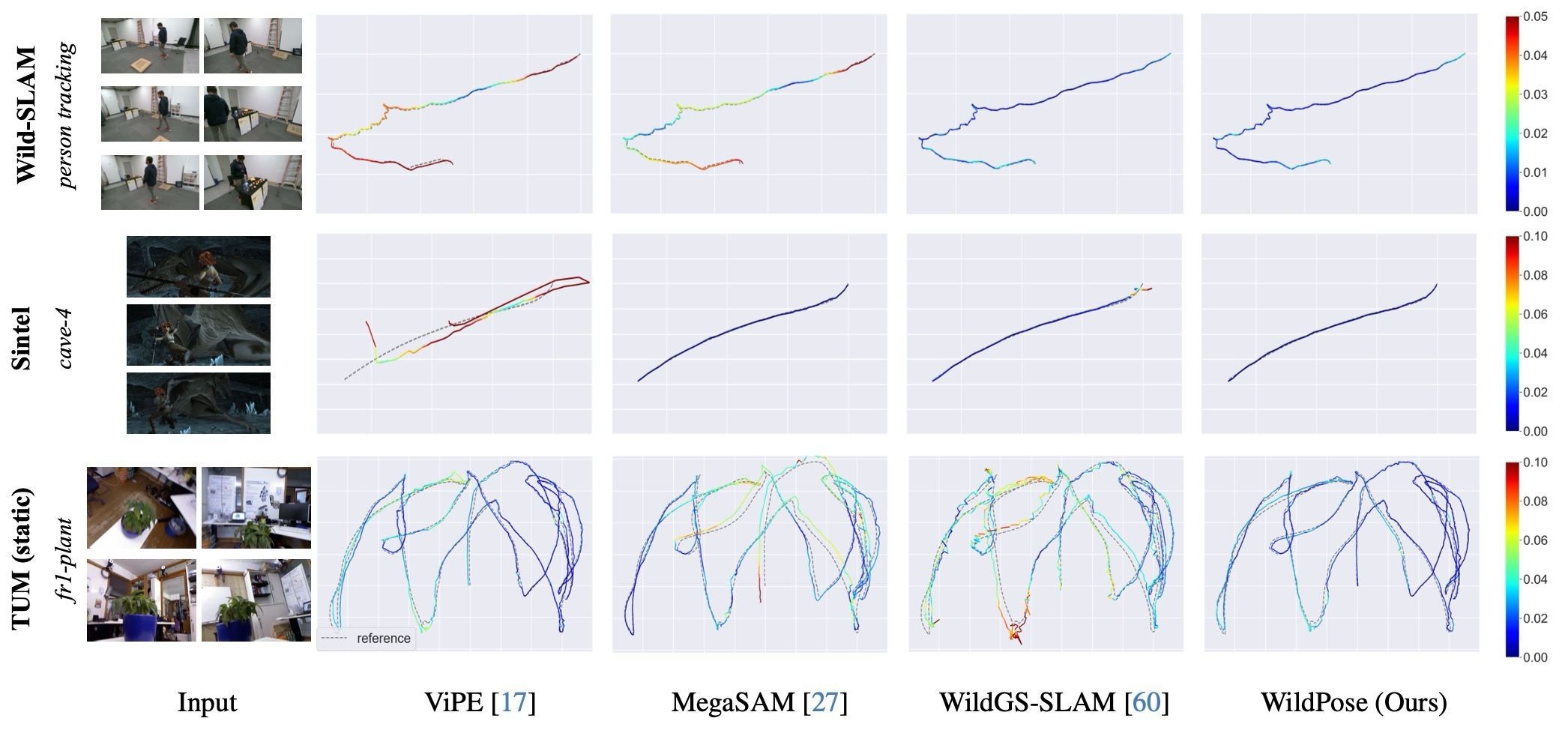
주요 결과: Sintel처럼 짧고 low-motion인 sequence에서는 WildGS-SLAM이 충분한 map coverage를 만들기 어렵지만 WildPose는 가장 좋은 성능을 보인다. TUM static과 7-Scenes에서는 dynamic-aware method가 static에서 무너지는 문제를 피한다.
주요 결과: MegaSaM의 long-video depth optimization pipeline에 WildPose pose와 mask를 넣으면 Abs.Rel., Log-RMSE, \( \delta_{1.25} \) 모두 개선된다. Ablation은 mixed finetuning, explicit motion mask, final global BA에서 depth regularizer 제거가 전체 시스템 성능에 기여함을 보여준다.
Usage / Limits: 언제 유용하고 어디서 약한가
WildPose는 dynamic handling과 static robustness를 동시에 요구하는 monocular pose estimation에 적합하다.
| 잘 맞는 상황 | 주의할 상황 |
|---|---|
|
|
느낀점
(진행중...)
Problem: static-world assumptions destabilize in-the-wild pose estimation
WildPose starts from a common weakness in visual SLAM/SfM: many systems assume a static world. Real videos contain moving people, movable objects, low ego-motion, and illumination changes, which increase pose-graph residuals and make BA confuse camera motion with object motion.
The paper aims for a unified pose estimator rather than a dynamic-scene-only special case.
Classical consistency assumes a static scene.
Moving objects create flow not explained by ego-motion.
Semantic priors, online mapping, and low-capacity motion decoding each leave limitations.
Connect 3D-aware features and edge masks directly to BA.
The problem statement and experiments point to the same answer: strong frontend features plus robust optimization.
| Axis | Existing bottleneck | WildPose view |
|---|---|---|
| Dynamic scenes | Sensitive to semantic priors or mask quality | Edge-dependent learned motion mask |
| Static scenes | Dynamic-only methods can degrade on static-only input | Static/dynamic mixed curriculum |
| Long trajectory | Local VO accumulates drift | Loop closure + periodic/final global BA |
Related Work context
WildPose is positioned between feed-forward 3D reconstruction, differentiable SLAM, and dynamic-scene pose estimation.
| Line | Strength | Limitation identified by WildPose |
|---|---|---|
| Feed-forward 3D reconstruction | Robust 3D priors from DUSt3R/MASt3R/VGGT-style models | Long sequences and precise pose still benefit from optimization |
| Differentiable SLAM | DROID-SLAM's learnable update and differentiable BA | Static training and a scratch-trained CNN encoder are weak under dynamic input |
| Dynamic pose estimation | Handles dynamics through semantic, geometric, or motion cues | Unseen objects, segmentation failure, synthetic-domain gap, and online cost remain |
Mechanism: how are MASt3R features and motion masks injected into BA?
The method keeps DROID-SLAM's differentiable BA pipeline, but changes the frontend and residual weighting. WildPose strengthens the update operator with MASt3R encoder features and uses an edge-specific motion mask \( \hat{M}_{i,j} \) to downweight dynamic-pixel reprojection residuals.
The method is easiest to read as DROID-style BA state, MASt3R frontend, edge motion detector, curriculum training, and online inference.
| Part | Role | Key device |
|---|---|---|
| State | Jointly optimizes keyframe pose and downsampled disparity | \( \hat{\omega}_i \), \( \hat{d}_i \), frame graph \( \mathcal{G} \) |
| Update operator | Iteratively updates predicted flow, confidence, damping, and upsampling mask | ConvGRU + correlation + MASt3R feature |
| Motion detector | Downweights dynamic residuals per graph edge | MASt3R multi-level correspondence token + DPT-style fusion |
| Inference | Online VO, metric depth initialization, loop/global BA | Moge2 depth prior + masked BA |
The key choice is to treat dynamics as edge-level residual weights, not only semantic classes.
Pointmap precision and 2D-correspondence pretraining align well with flow/BA updates.
An object is an outlier only for graph edges where it actually moves.
It mitigates long-sequence scale and pose drift beyond the local sliding window.
Each keyframe state contains the camera pose \( \hat{\omega}_i\in SE(3) \) and downsampled disparity \( \hat{d}_i \). For an edge \( (i,j)\in\mathcal{G} \), geometry-induced flow is computed by projection and back-projection.
Eq. (1)-(2) use the DROID-SLAM notation that WildPose builds on. The update operator reduces residuals by refining flow/confidence, and BA uses those values to optimize pose and disparity.
| Notation | Meaning | How to read it |
|---|---|---|
| \( \hat{\omega}_i \), \( \hat{d}_i \) | camera pose and downsampled disparity of keyframe \(i\) | The state optimized by BA. |
| \( \mathcal{G} \), \( (i,j) \) | frame graph and an edge between keyframes with observation overlap | Residuals are accumulated per graph edge. |
| \( \Pi_c \), \( p_i \) | pinhole camera projection and a pixel in reference frame \(i\) | Back-project the pixel to 3D, then project it into frame \(j\). |
| \( \tilde{f}^{t}_{i,j} \) | geometry-induced optical flow from the current pose/disparity at iteration \(t\) | The flow that should explain a static scene. |
| \( \hat{f}^{t}_{i,j} \) | predicted optical flow, \( \mathbb{R}^{H/8 \times W/8 \times 2} \) in the paper | The learned flow compared against geometry-induced flow. |
| \( \hat{w}^{t}_{i,j} \) | confidence of predicted flow, \( \mathbb{R}^{H/8 \times W/8 \times 2} \) in the paper | Becomes the BA weight through \( \Sigma_{ij}^{-1}=\operatorname{diag}(\hat{w}_{i,j}) \). |
| \( r^{t}_{i,j} \) | \( r^{t}_{i,j}=\hat{f}^{t}_{i,j}-\tilde{f}^{t}_{i,j} \) | The residual between learned flow and geometry flow; this is the key input for the next update. |
| \( \hat{\eta}^{t} \), \( \hat{u}^{t} \) | BA damping factor and disparity upsampling mask | Auxiliary variables that stabilize BA and upsample disparity. |
WildPose replaces DROID's scratch-trained CNN encoder with pretrained MASt3R ViT encoder features. A lightweight adapter converts these features into local feature maps and global context for the ConvGRU. The paper avoids feeding full decoder tokens into the ConvGRU because that would make training and inference expensive.
The true flow of a dynamic pixel includes object self-motion in addition to camera ego-motion. The paper writes this as \(X_{i,j}(p_i)\); if static BA tries to fit this residual directly, pose and disparity are updated incorrectly.
Training curriculum / loss notation
Training is staged rather than fully joint from the start. The update operator first learns ego-motion-induced pairwise flow on static data, then learns robustness with dynamic data and ground-truth masks, and finally the motion detector is trained with the frozen update operator and differentiable BA.
Training loss terms
Eq. (3) follows the DROID-SLAM-style update-operator training loss, while Eq. (4) adds motion-mask supervision for the detector.
| Term | Signal | Role in WildPose |
|---|---|---|
| \( \mathcal{L}_{\mathrm{cam}} \) | Camera-pose supervision | Trains the update operator to refine pose reliably. |
| \( \mathcal{L}_{\mathrm{flow}} \) | Geometry-induced flow versus ground-truth flow | Builds the static ego-motion flow baseline for BA updates. |
| \( \mathcal{L}_{\mathrm{res}} \) | Residual between geometry-induced flow \( \tilde{f} \) and operator-predicted flow \( \hat{f} \) | Encourages the recurrent update to reduce residuals across iterations. |
| \( \mathcal{L}_{\mathrm{BCE}} \) | Binary motion-mask supervision | Trains edge-specific masks that downweight dynamic residuals in BA. |
At inference time, WildPose runs as online visual odometry. A new keyframe is initialized with Moge2 metric depth \(D_i\), connected to co-visible keyframes, and assigned edge-specific motion masks.
WildPose modifies DROID-SLAM mainly through the BA weight and the metric-depth prior. Dynamic residuals are downweighted by masks, while monocular scale is anchored by depth.
| Notation | Meaning | Role |
|---|---|---|
| \( X_{i,j}(p_i) \) | 3D displacement of a moving point from frame \(i\) to \(j\) | Explains why dynamic-pixel flow cannot be modeled by ego-motion only. |
| \( \hat{M}_{i,j} \) | edge-specific predicted motion mask, \( \mathbb{R}^{H/8 \times W/8} \) in the paper | Downweights only the regions that are outliers for a given frame pair. |
| \( \bar{\Sigma}_{ij} \) | BA covariance/weight after applying the motion mask | Combines confidence and motion filtering through \( \hat{w}_{i,j}\hat{M}_{i,j} \). |
| \( D_i \), \( \lambda \) | Moge2 metric-depth prior and regularization weight | Keeps online BA disparity close to metric depth. |
Training / inference details
The setup is separated into data, training, and inference conditions.
| Item | Content |
|---|---|
| Training data | TartanAir V2, TartanGround, Dynamic Replica, OmniWorld-Game, Kubric-generated static/dynamic sequences |
| Kubric motion | linear translation, pure rotation, target-locked motion |
| Item | Content |
|---|---|
| Update operator | static pretraining for 200K iterations, static+dynamic finetuning for 100K iterations |
| Motion detector | trained for 15K iterations with frozen update operator and differentiable BA |
| Item | Content |
|---|---|
| Loop closure | adds BA edges to past co-visible keyframes when temporal and co-visibility thresholds are met |
Evidence: which tasks validate the method?
The evaluation is best read through four claims: dynamic-scene pose, static/low-motion robustness, downstream depth, and ablation.
The paper follows the common monocular SLAM protocol: Sim(3) Umeyama alignment followed by ATE RMSE.
| Axis | Dataset / metric | Meaning |
|---|---|---|
| Dynamic pose | Wild-SLAM MoCap, Bonn RGB-D Dynamic, TUM dynamic / ATE RMSE | Pose robustness under moving distractors |
| Low-motion / static | Sintel, TUM static, 7-Scenes / ATE RMSE | Checks whether dynamic handling preserves static-scene performance |
| Depth downstream | Bonn Dynamic / Abs.Rel., Log-RMSE, \( \delta_{1.25} \) | Effect of pose and masks on long-video depth optimization |
| Ablation | Mix. Ft., Motion Mask, GBA Depth Off | Separates contributions of the design choices |
Main result: WildPose reaches the lowest average ATE on Wild-SLAM MoCap and the best average on TUM dynamic. On Bonn, WildGS-SLAM is slightly ahead under illumination-heavy conditions, while WildPose remains competitive overall.
Main result: On short low-motion Sintel sequences, WildGS-SLAM struggles to build enough map coverage, while WildPose performs best. On TUM static and 7-Scenes, WildPose avoids the static-scene degradation seen in dynamic-specialized methods.
Main result: Using WildPose poses and masks inside MegaSaM's long-video depth optimization improves Abs.Rel., Log-RMSE, and \( \delta_{1.25} \). The ablation shows that mixed finetuning, explicit motion masks, and removing depth regularization in final global BA all contribute to the full system.
Usage / Limits: when is it useful?
WildPose is well suited to monocular pose estimation where dynamic handling and static robustness are both required.
| Good fit | Use with care |
|---|---|
|
|
Takeaway
(In progress...)
Comments